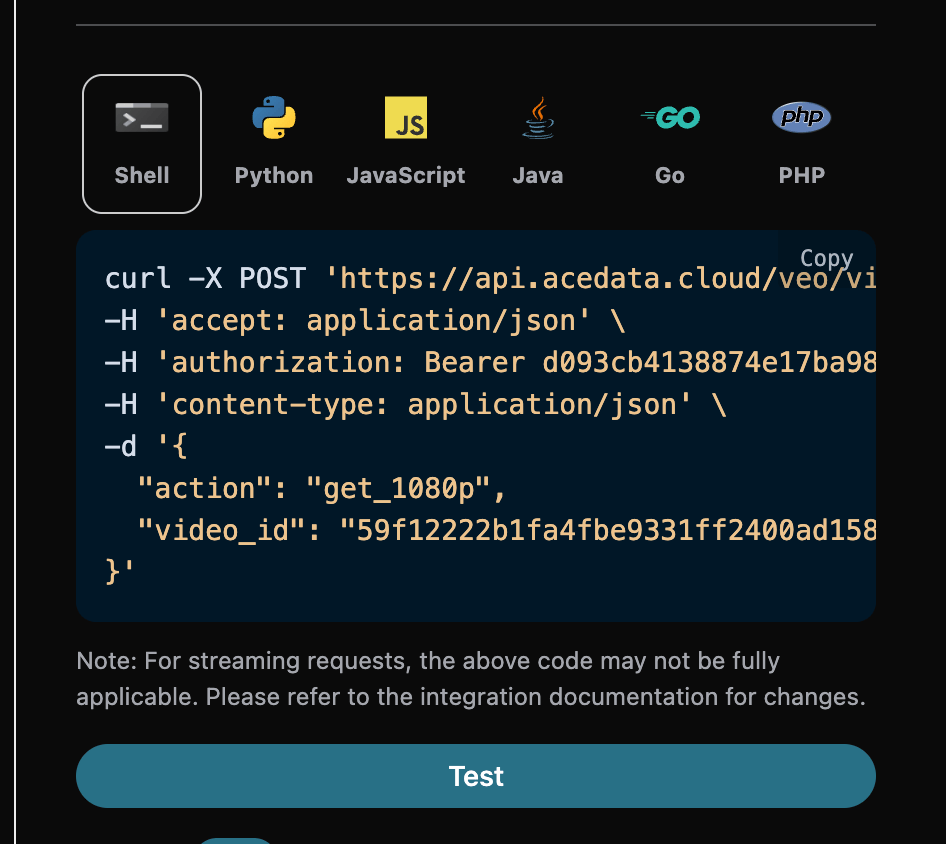
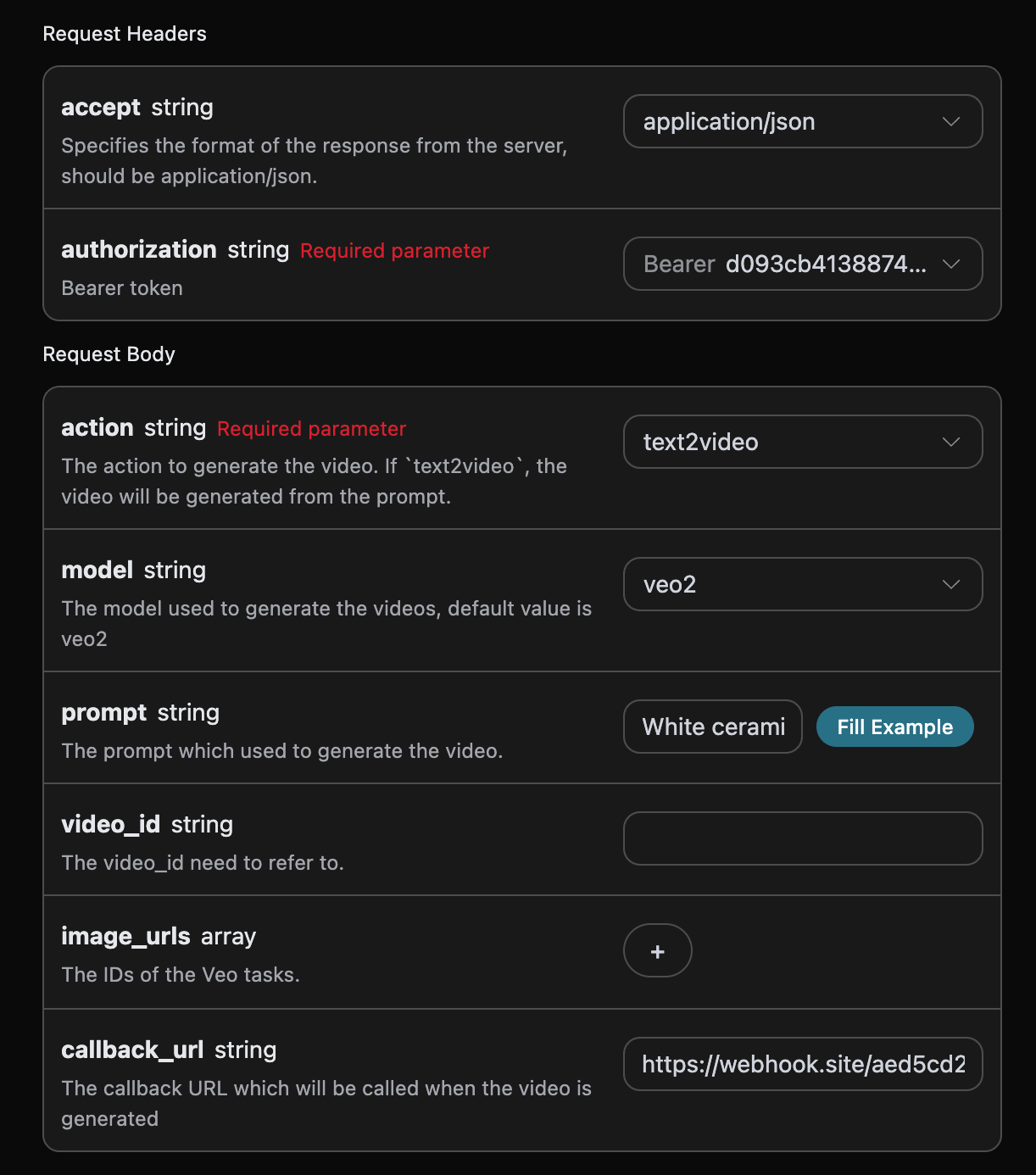
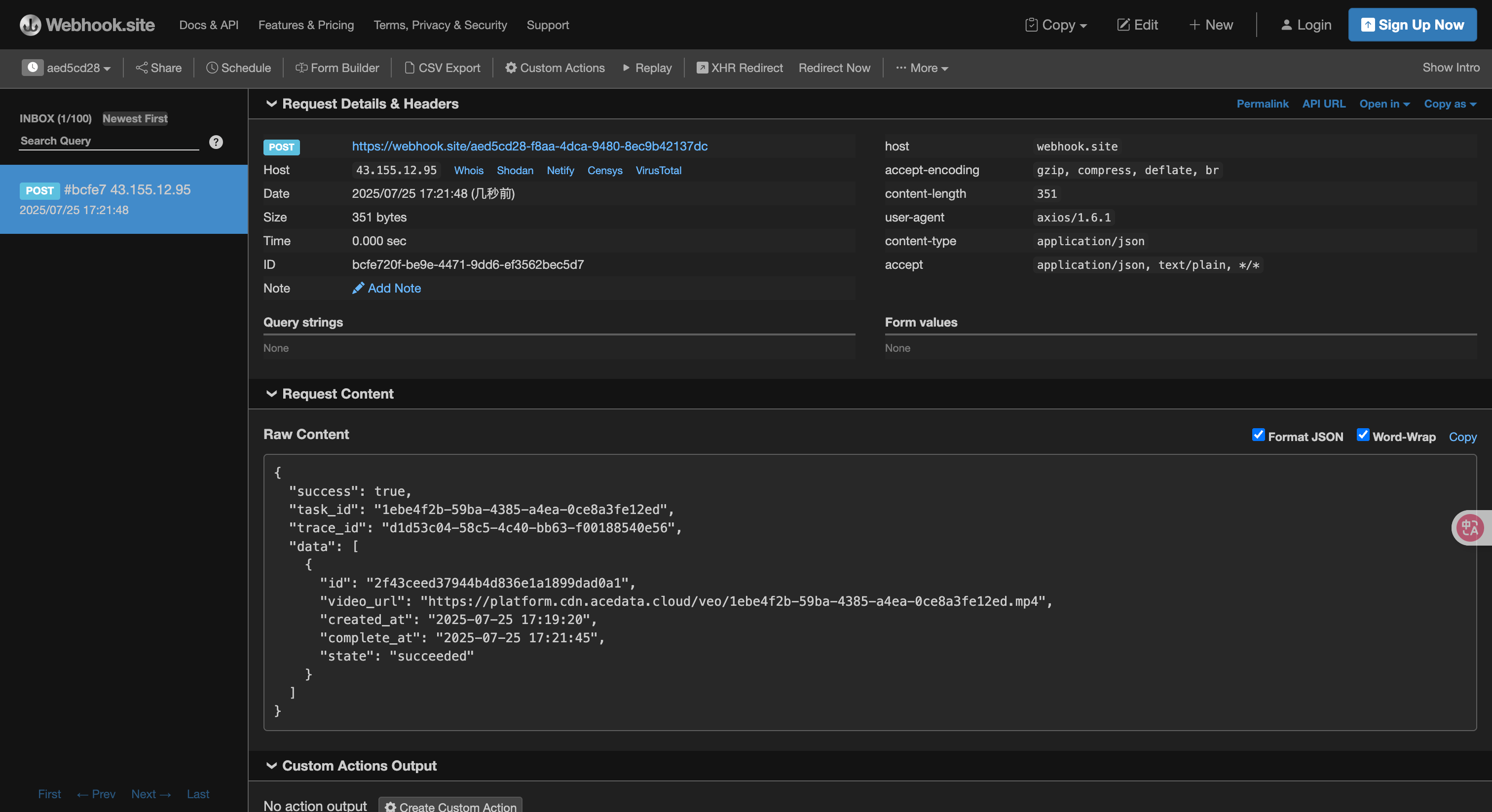
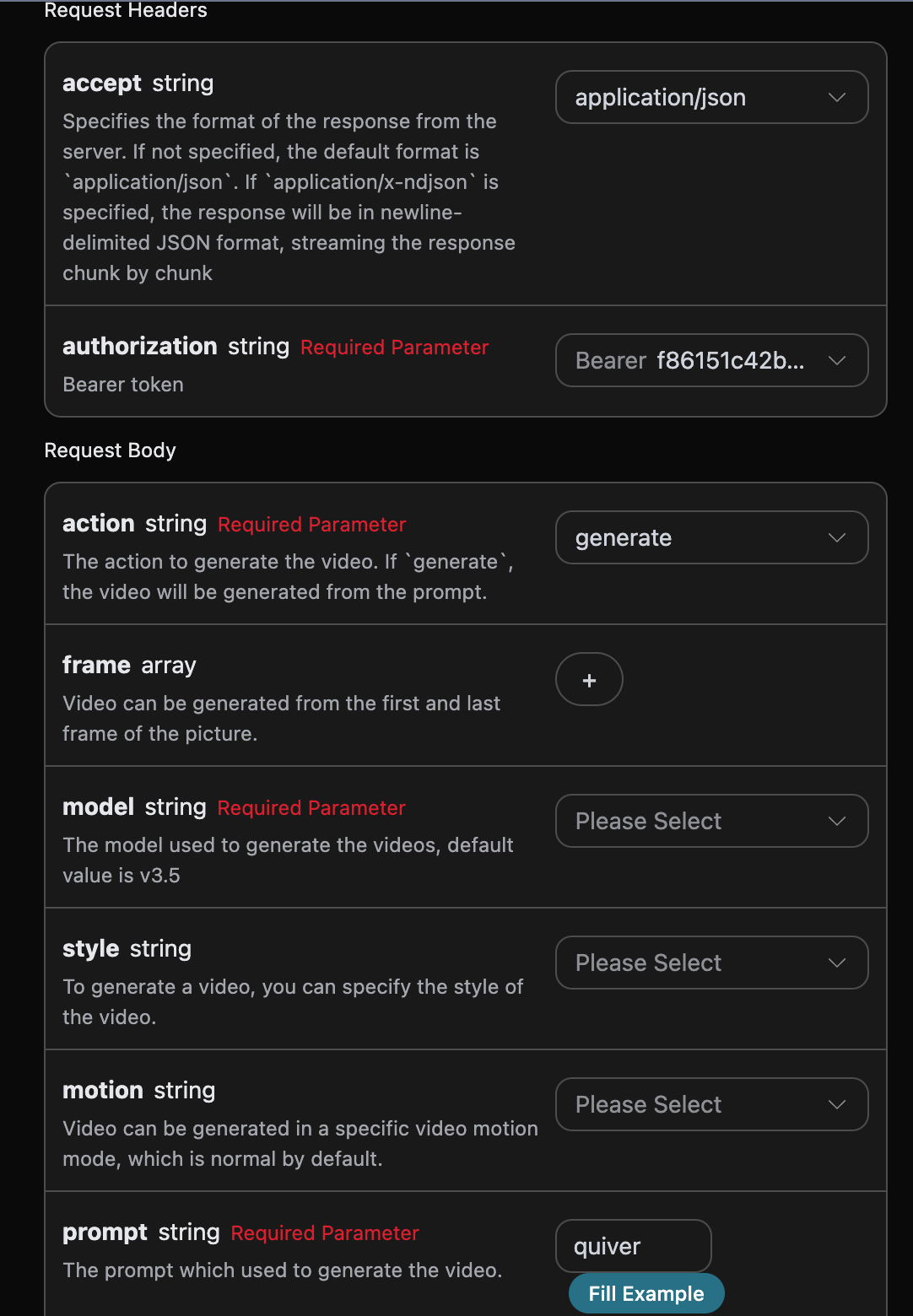
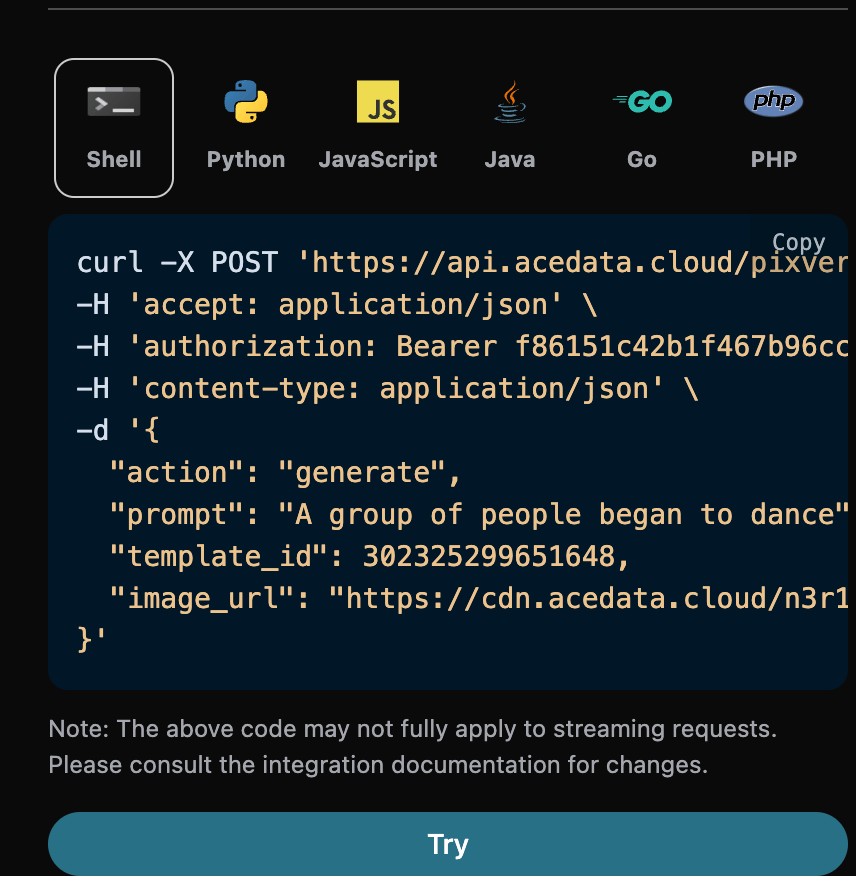
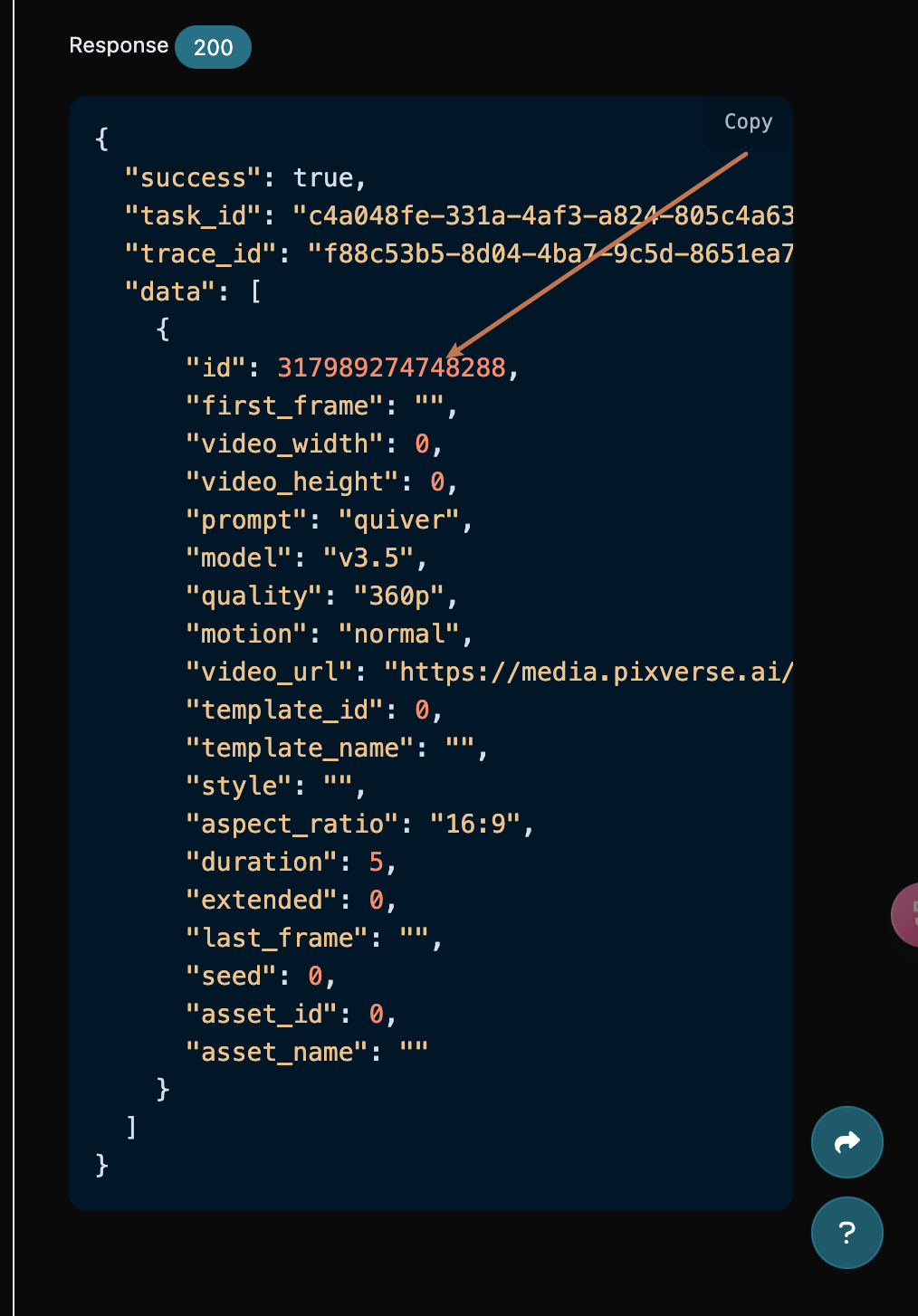
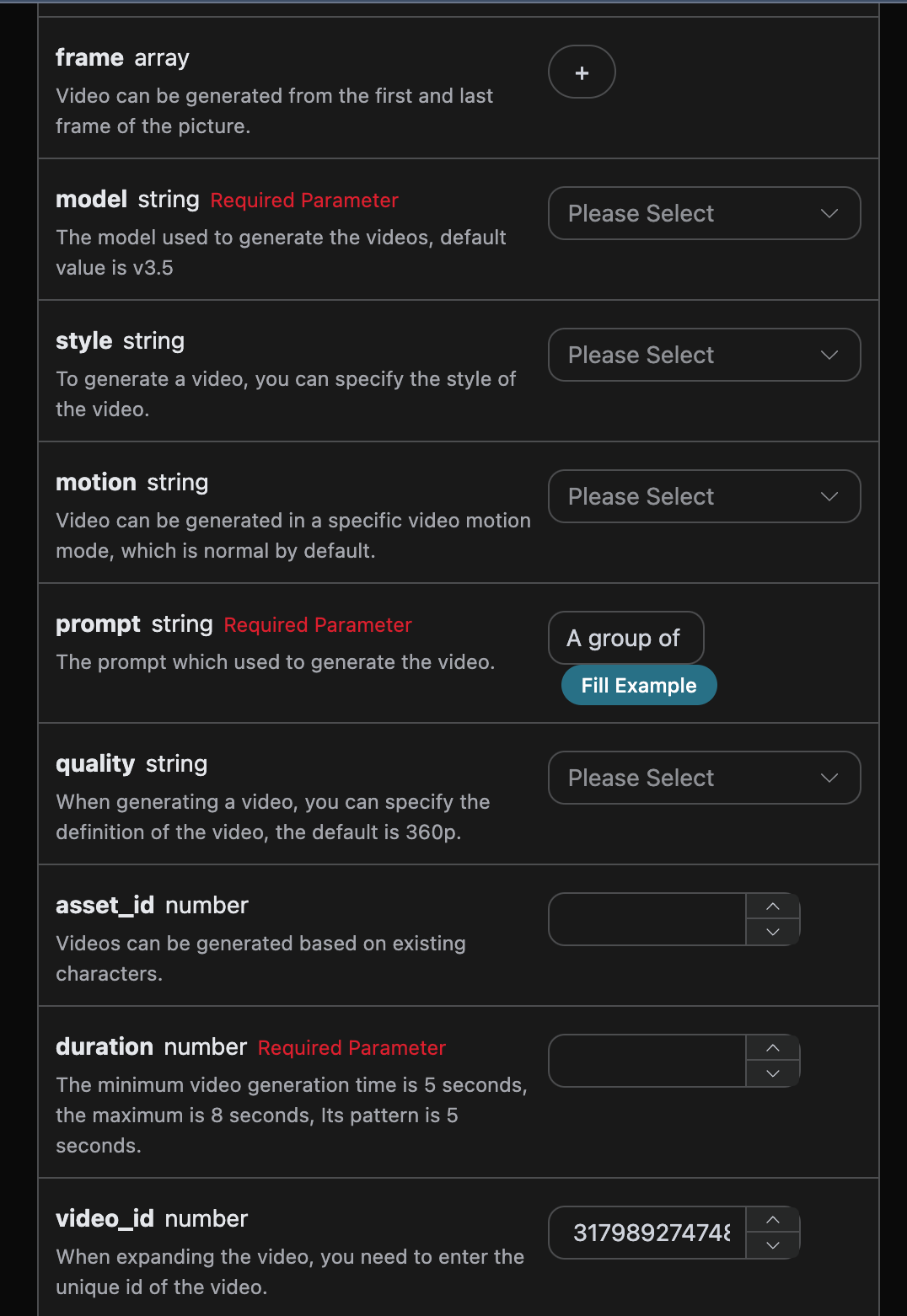
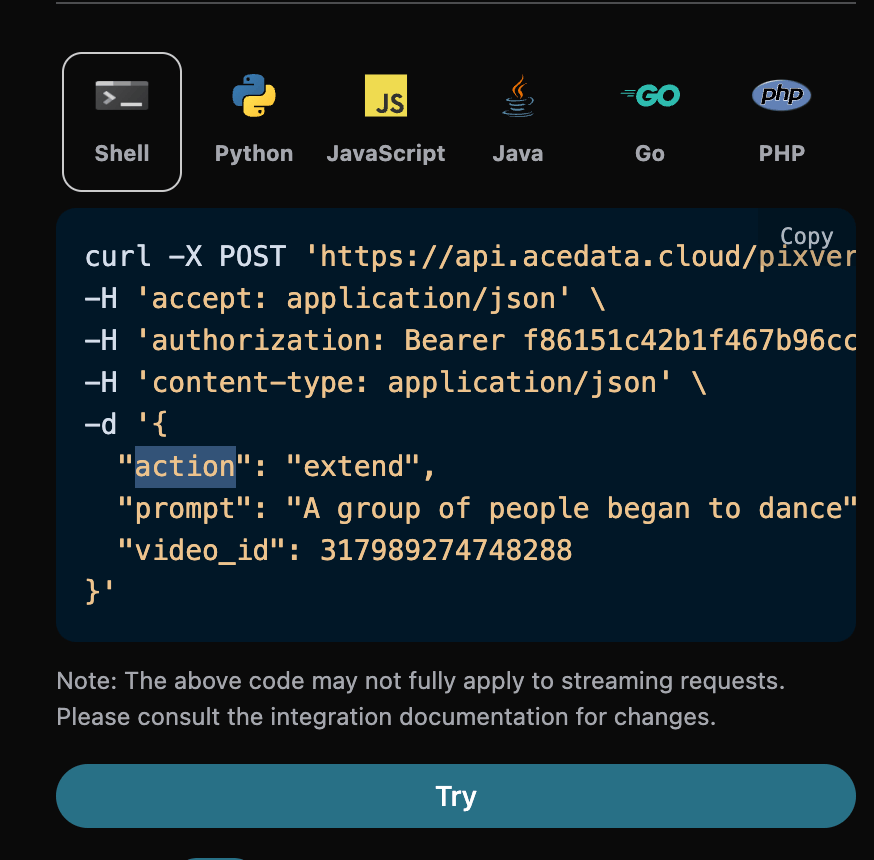
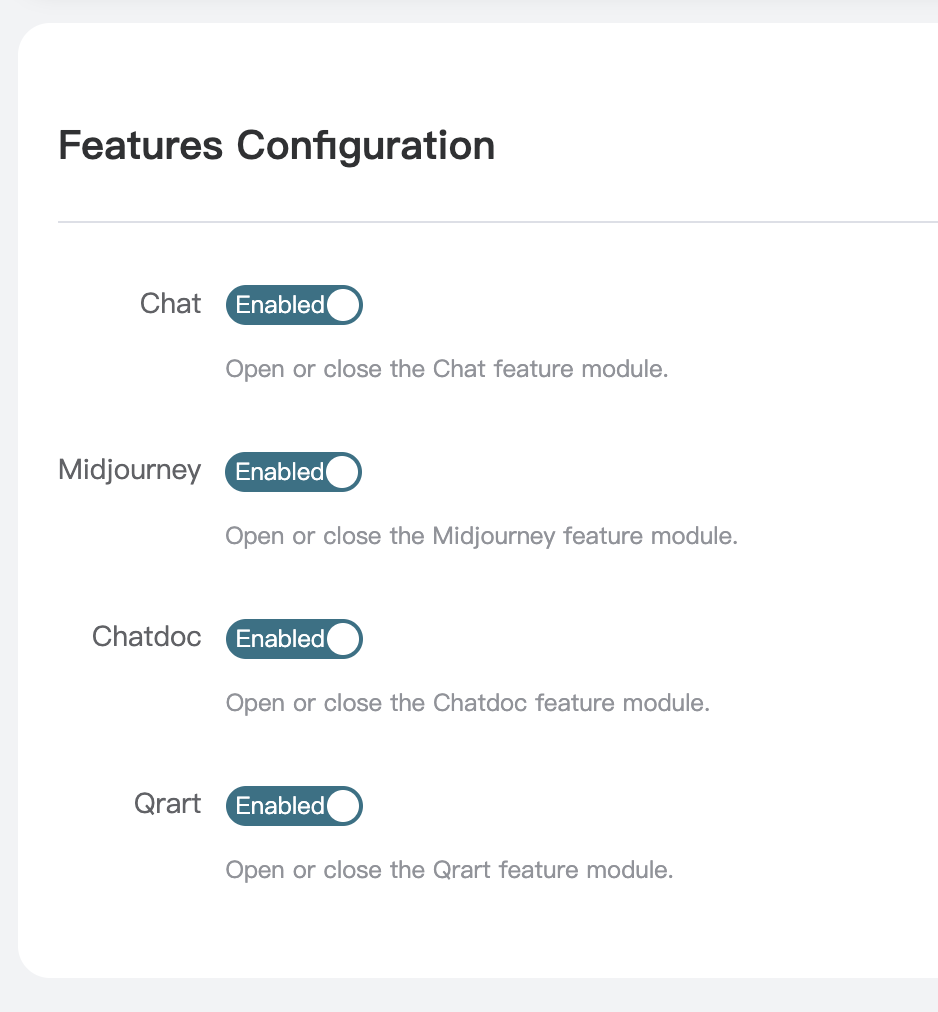
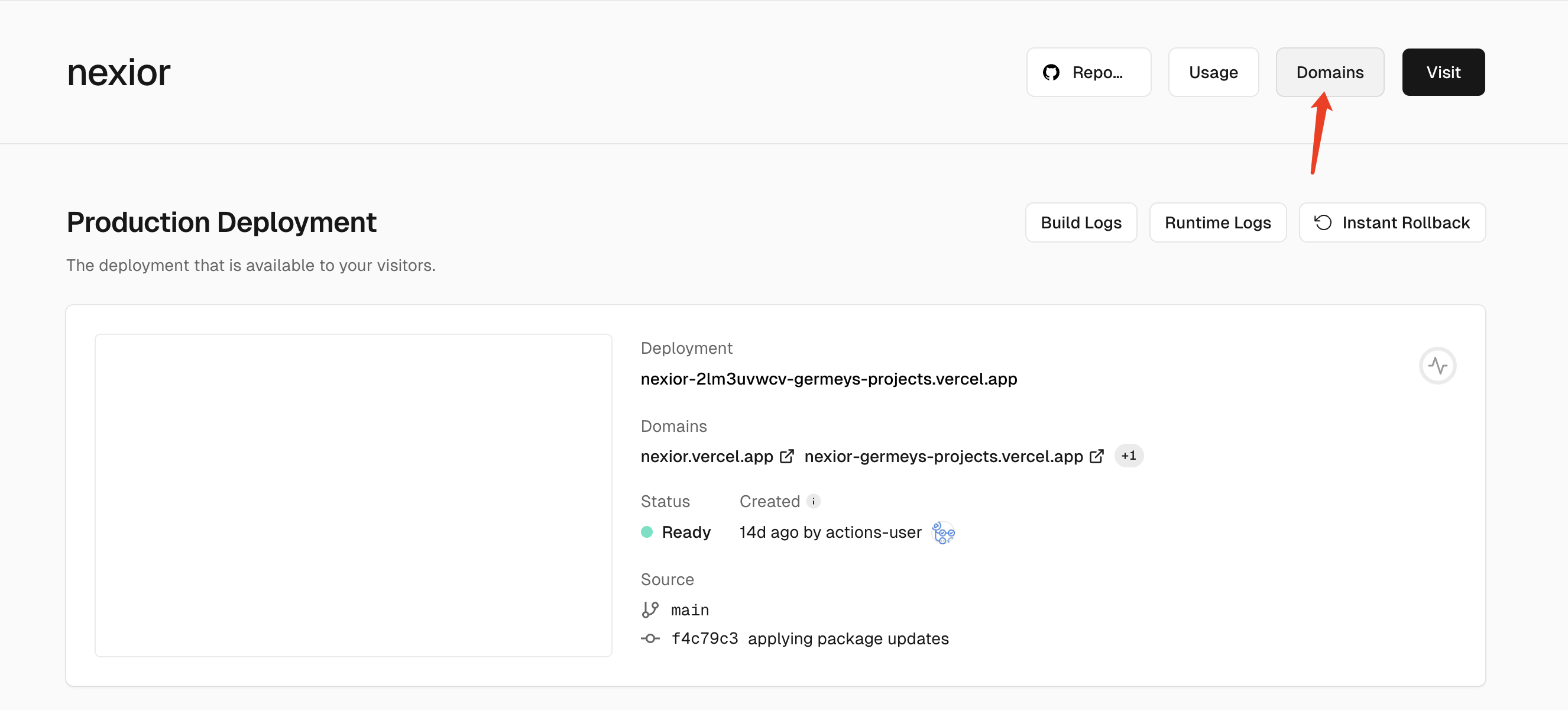
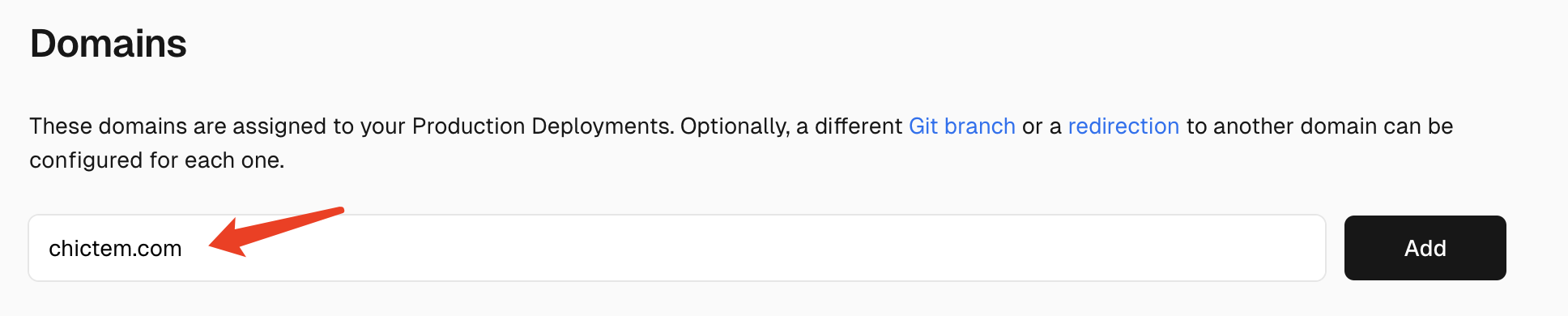
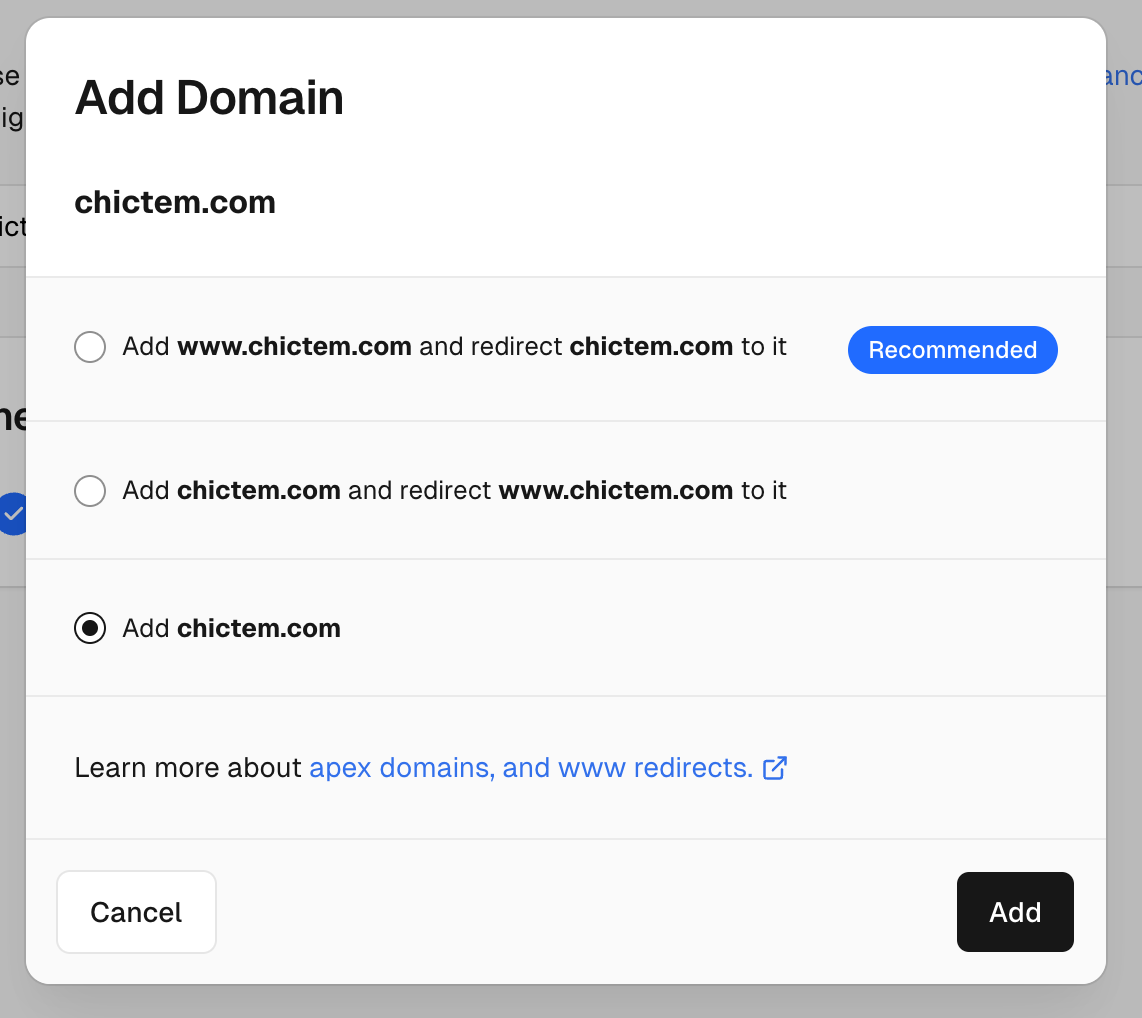
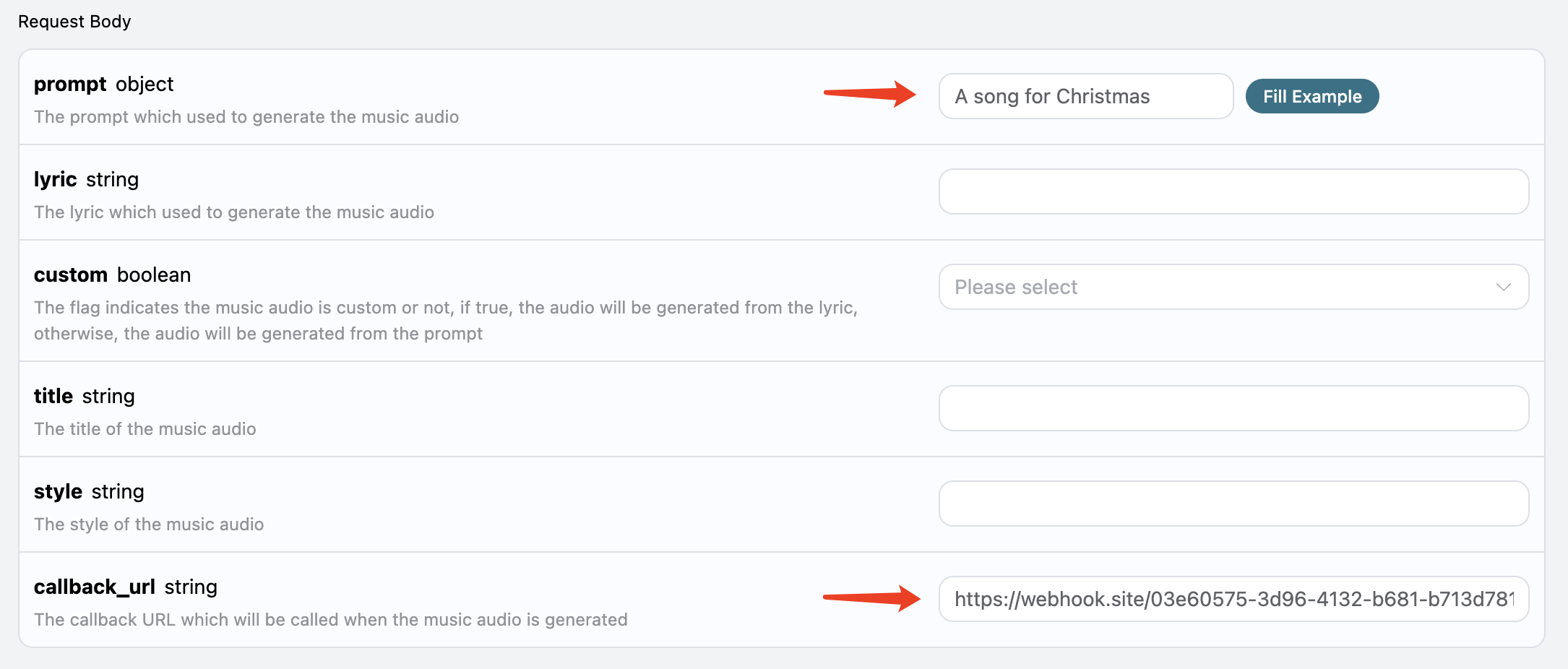
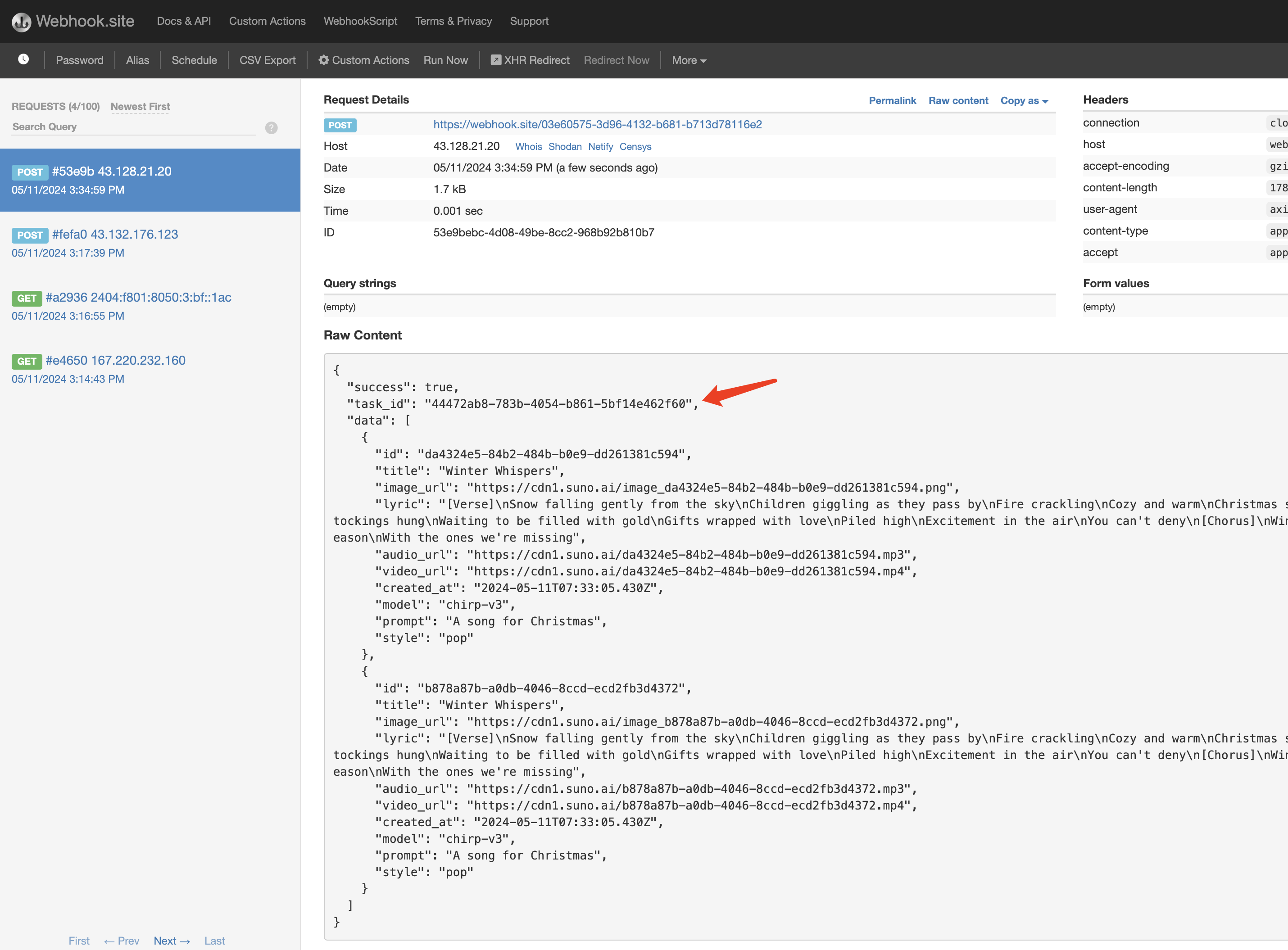
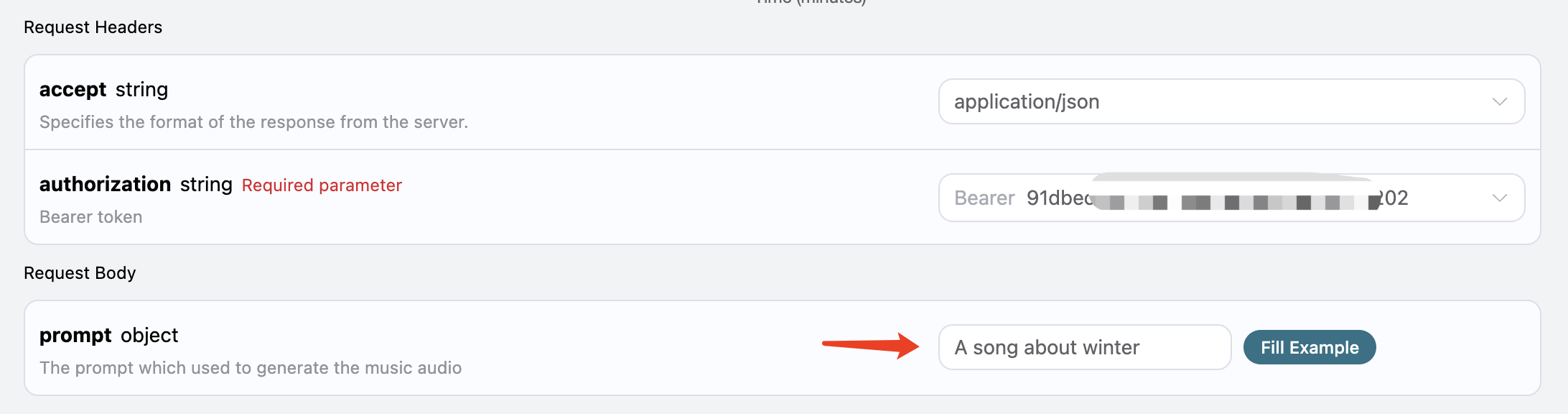
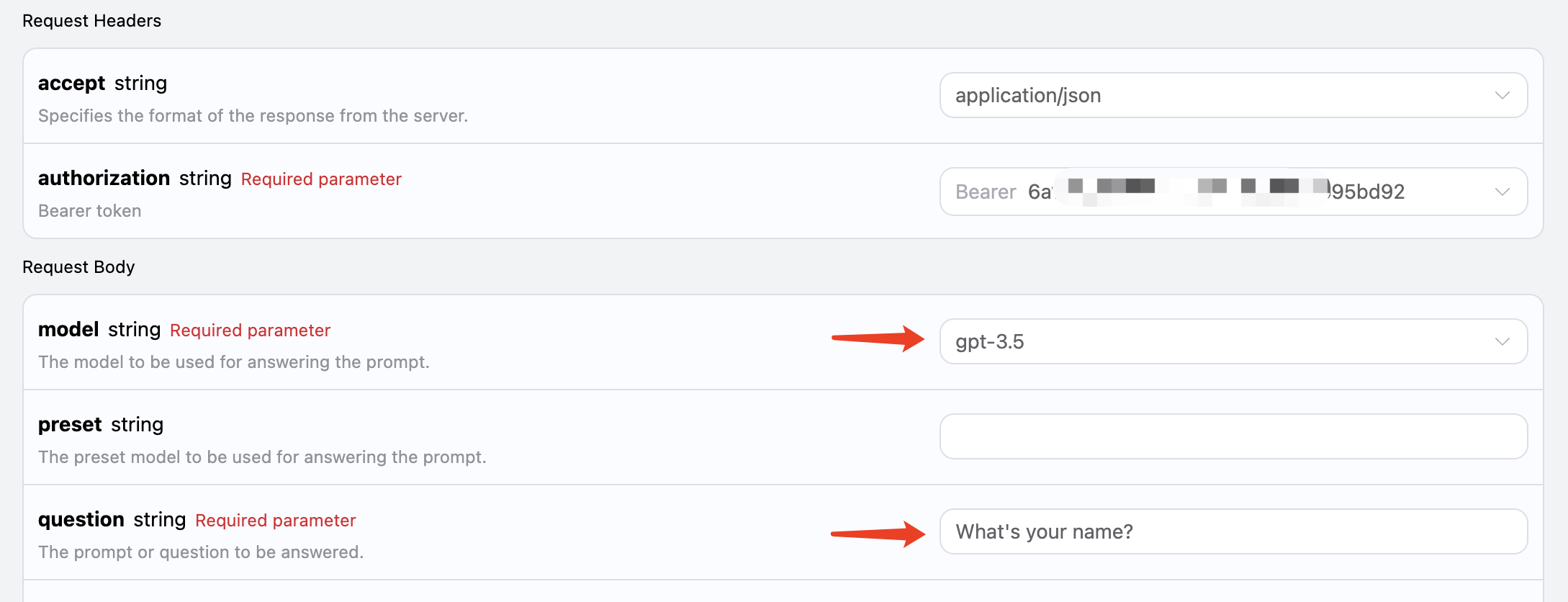
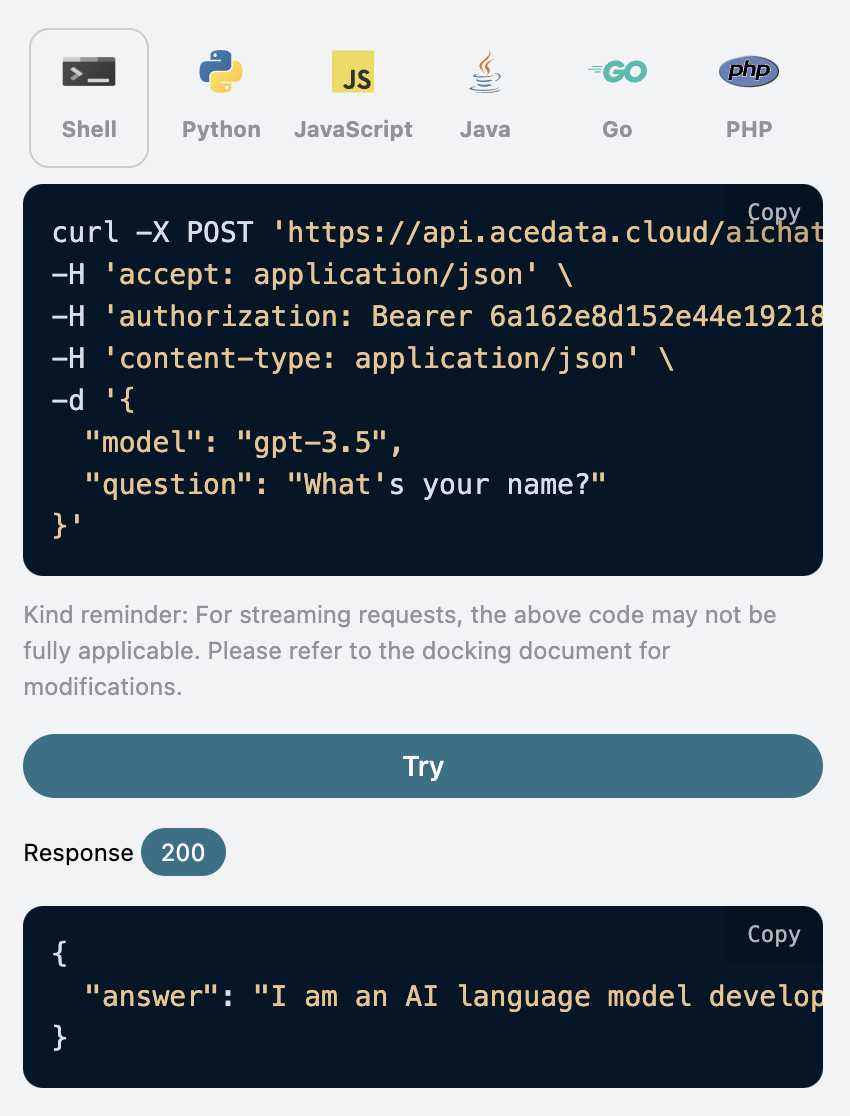
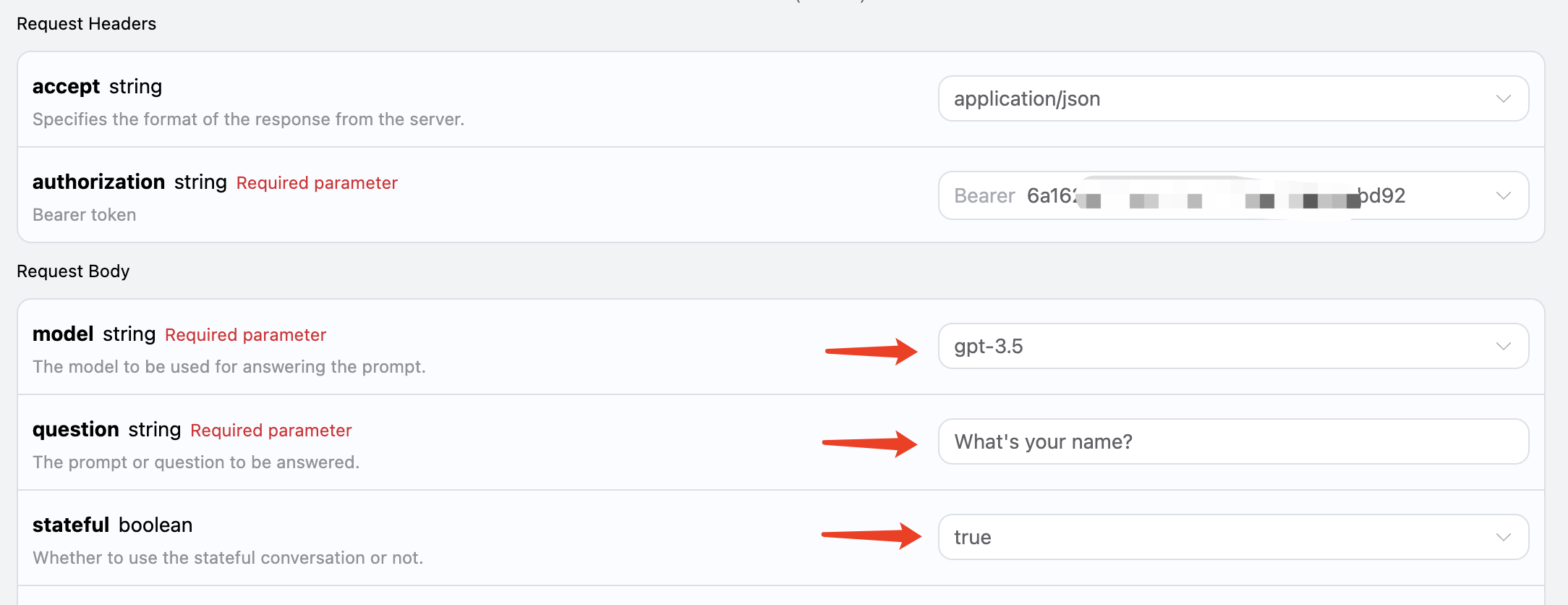
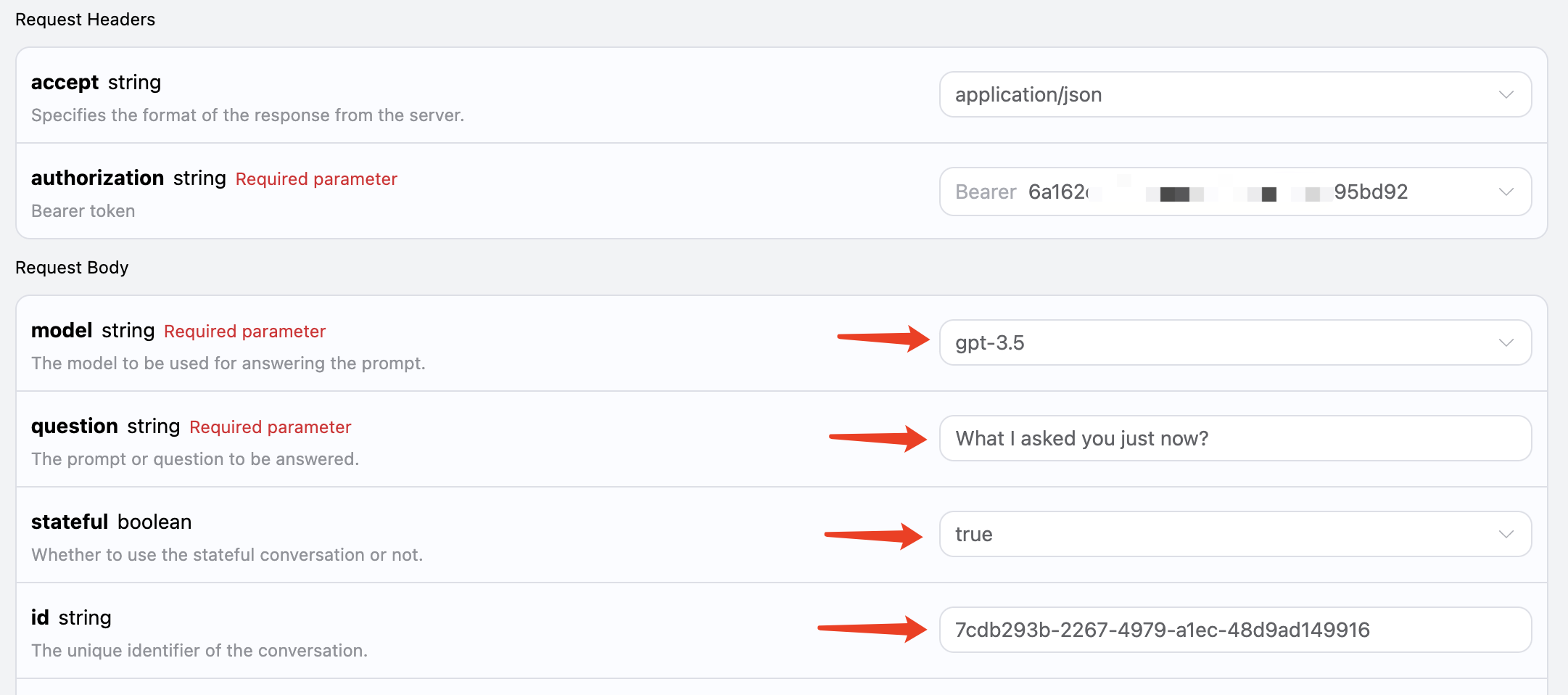
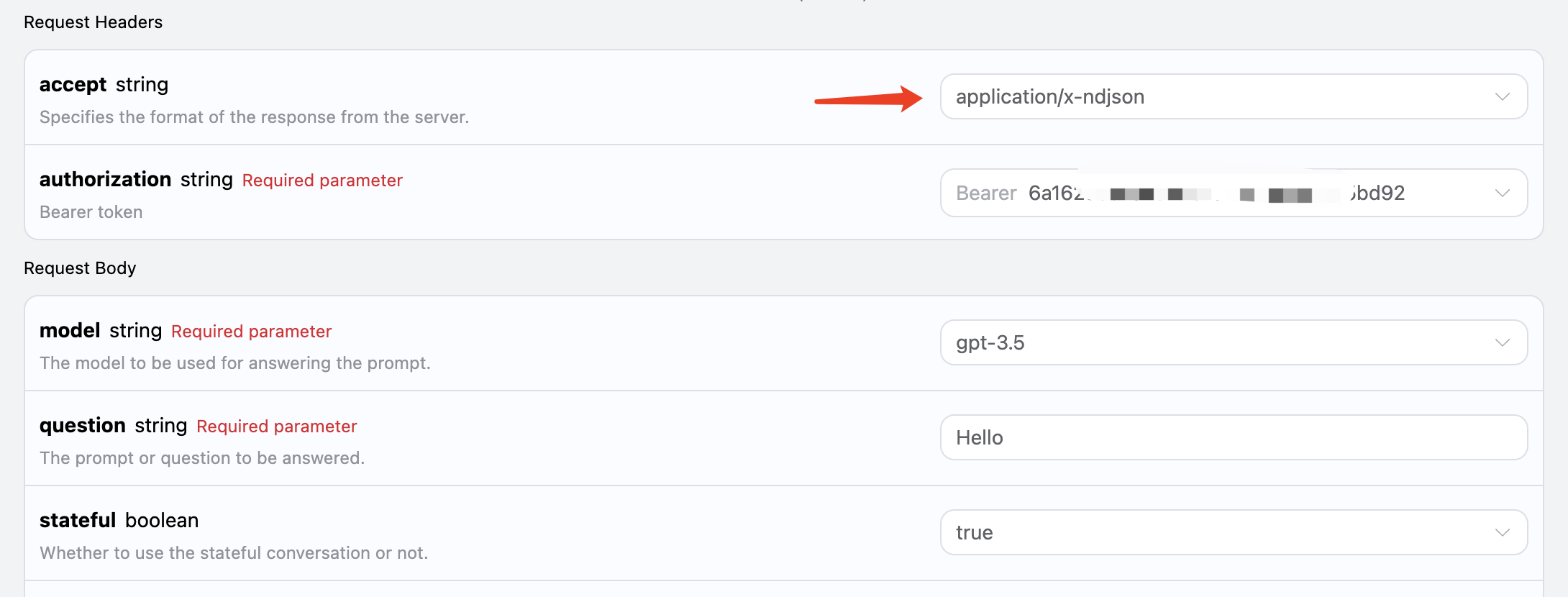
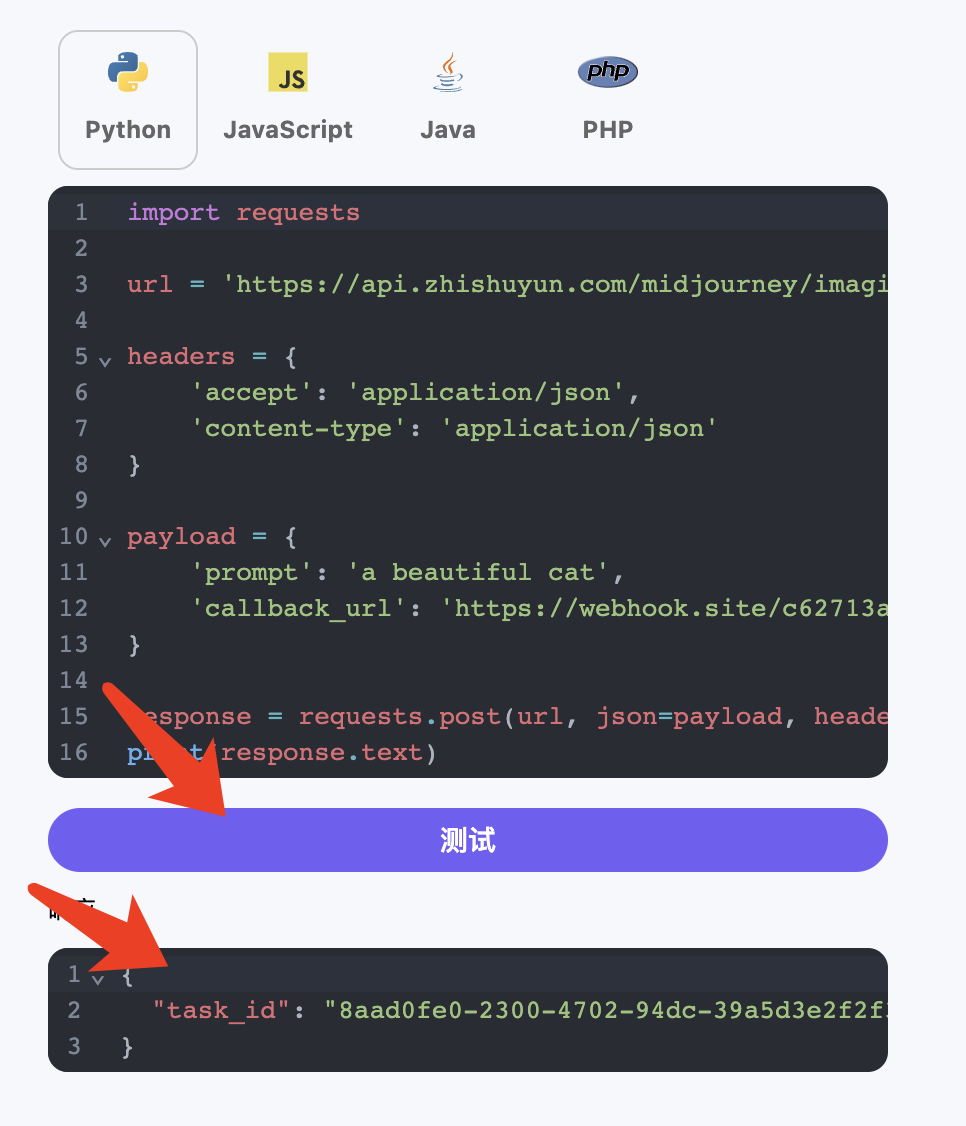
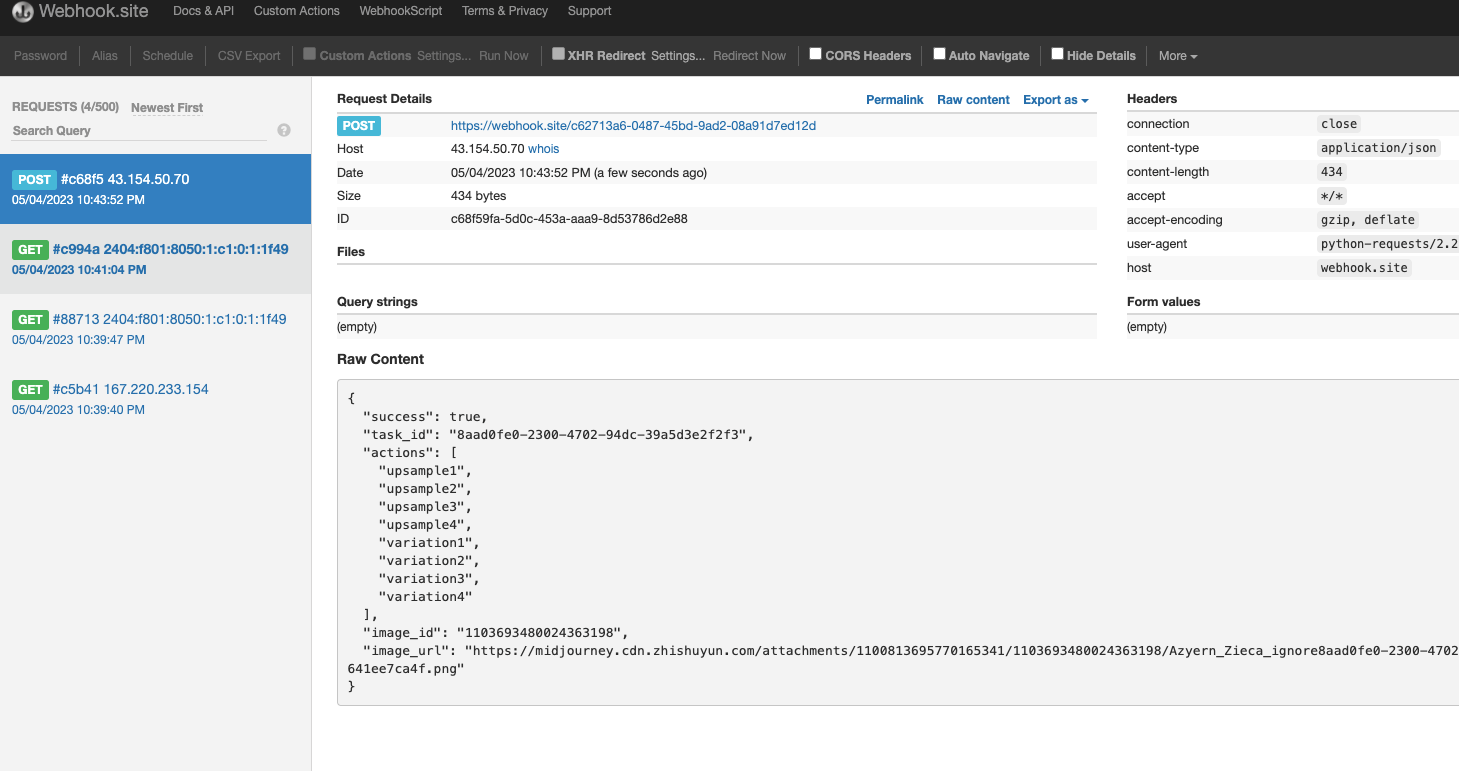
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
|
[
{
"display_name": "Muscle Surge",
"workflow_tag": "muscle_241128",
"template_id": 308621408717184,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fwithbaby.gif",
"thumbnail_video_path": "",
"marker": "hot",
"created_at": "2024-11-28T17:53:21Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "Show off your strong muscles and have everyone hooked.",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"成为肌肉猛男\",\"display_prompt\":\"体验猛男快乐\"}}",
"example_list": "[{\"img_id\":113750602,\"img_url\":\"https://media.pixverse.ai/upload%2F920dc791-8c9f-4518-8761-82958a827190.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"},{\"img_id\":113750791,\"img_url\":\"https://media.pixverse.ai/upload%2Ff2853009-8238-4e0f-93ec-cfc68fee28b7.png\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Hug Your Love",
"workflow_tag": "hug_love_241030",
"template_id": 303624424723200,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fhug2.gif",
"thumbnail_video_path": "",
"marker": "hot",
"created_at": "2024-10-31T12:07:47Z",
"updated_at": "2025-01-06T05:32:42Z",
"display_prompt": "Hug each other\t",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"爱的抱抱\",\"display_prompt\":\"互相拥抱在一起\"}}",
"example_list": "[{\"img_id\":113741803,\"img_url\":\"https://media.pixverse.ai/upload%2Fb2626bc2-050d-4ea6-a864-e2054c012df5.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Alive Art",
"workflow_tag": "alive_art_241028",
"template_id": 302325299721280,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Faliveart.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-10-24T03:55:29Z",
"updated_at": "2025-01-06T05:32:53Z",
"display_prompt": "The [OBJECT] comes to life and walks out of the [SCENE]",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"活灵活现\",\"display_prompt\":\"它活了!\"}}",
"example_list": "",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Sheep Curls",
"workflow_tag": "sheep_241208",
"template_id": 310371322329472,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2FSheepCurls.gif",
"thumbnail_video_path": "",
"marker": "new",
"created_at": "2024-12-08T15:14:11Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "Change hairstyle for a better mood",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"万物皆可羊毛卷\",\"display_prompt\":\"心情不好,换个发型看看\"}}",
"example_list": "[{\"img_id\":113741803,\"img_url\":\"https://media.pixverse.ai/upload%2Fb2626bc2-050d-4ea6-a864-e2054c012df5.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Sailor Moon",
"workflow_tag": "meishaonv_241225",
"template_id": 313359138372032,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fmeishaonv2.gif",
"thumbnail_video_path": "",
"marker": "",
"created_at": "2024-12-25T12:29:05Z",
"updated_at": "2025-01-06T05:32:33Z",
"display_prompt": "Moon Prism Power, Make Up!",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"成为美少女战士\",\"display_prompt\":\"月之水晶力量,变身!\"}}",
"example_list": "",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Black Myth: Wukong",
"workflow_tag": "heiwukong_241225",
"template_id": 313359209531840,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fmonkey.gif",
"thumbnail_video_path": "",
"marker": "",
"created_at": "2024-12-25T12:29:40Z",
"updated_at": "2025-01-06T05:32:25Z",
"display_prompt": "I am Sun Wukong, the Victorious Fighting Buddha!",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"黑悟空引擎\",\"display_prompt\":\"放马西行,直面天命!\"}}",
"example_list": "",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Santa's Secret Gifts",
"workflow_tag": "santa_gift_241213",
"template_id": 311521768592256,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fgift111.gif",
"thumbnail_video_path": "",
"marker": "new",
"created_at": "2024-12-15T03:16:32Z",
"updated_at": "2024-12-30T06:08:16Z",
"display_prompt": "I want a:",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"圣诞礼物盲盒\",\"display_prompt\":\"我想要:\"}}",
"example_list": "[{\"img_id\":113741803,\"img_url\":\"https://media.pixverse.ai/upload%2Fb2626bc2-050d-4ea6-a864-e2054c012df5.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Where is Santa?",
"workflow_tag": "where_is_santa_241213",
"template_id": 311521879229312,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fwheresanta.gif",
"thumbnail_video_path": "",
"marker": "new",
"created_at": "2024-12-15T03:17:26Z",
"updated_at": "2024-12-30T06:08:24Z",
"display_prompt": "Discovering Santa Claus in the parallel world!",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"圣诞老人藏在哪?\",\"display_prompt\":\"“发现”世界各处的圣诞老人\"}}",
"example_list": "[{\"img_id\":119280295,\"img_url\":\"https://media.pixverse.ai/upload%2Fde34a072-325e-4d86-88d9-2daef292e1b4.jpeg\"},{\"img_id\":119280616,\"img_url\":\"https://media.pixverse.ai/upload%2F5b4da0a2-86c3-4204-adda-74bfa7c3d0d1.jpg\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Christmas OOTD",
"workflow_tag": "tobe_santa_241219",
"template_id": 312314911869312,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fbesanta33.gif",
"thumbnail_video_path": "",
"marker": "new",
"created_at": "2024-12-19T14:51:09Z",
"updated_at": "2024-12-30T06:08:08Z",
"display_prompt": "Dress up as a Christmas star",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"圣诞战袍\",\"display_prompt\":\"测测什么圣诞装适合你\"}}",
"example_list": "[{\"img_id\":113741803,\"img_url\":\"https://media.pixverse.ai/upload%2Fb2626bc2-050d-4ea6-a864-e2054c012df5.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "We Are Venom!",
"workflow_tag": "venom_241030",
"template_id": 303624537709312,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2FWeAreVenom.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-10-31T12:08:42Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "Transform into a [BLACK] Venom",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"毒液变身!\",\"display_prompt\":\"变身成为【黑色】毒液\"}}",
"example_list": "[{\"img_id\":113750602,\"img_url\":\"https://media.pixverse.ai/upload%2F920dc791-8c9f-4518-8761-82958a827190.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"},{\"img_id\":113750791,\"img_url\":\"https://media.pixverse.ai/upload%2Ff2853009-8238-4e0f-93ec-cfc68fee28b7.png\"}]",
"qualities": [
"360p",
"540p"
]
},
{
"display_name": "Hot Harley Quinn",
"workflow_tag": "harley_quinn_241121",
"template_id": 307489434436288,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2FHotHarleyQuinn.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-11-22T08:21:19Z",
"updated_at": "2024-12-26T07:40:43Z",
"display_prompt": "Transform into Harley Quinn, mastering allure and chaos",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"小丑女哈莉·奎茵变身\",\"display_prompt\":\"化身小丑女哈莉·奎茵,掌控魅惑与疯狂\"}}",
"example_list": "[{\"img_id\":113741803,\"img_url\":\"https://media.pixverse.ai/upload%2Fb2626bc2-050d-4ea6-a864-e2054c012df5.png\"},{\"img_id\":113742000,\"img_url\":\"https://media.pixverse.ai/upload%2F19090035-612e-40ed-9c8d-a7aaf781d492.png\"},{\"img_id\":113742074,\"img_url\":\"https://media.pixverse.ai/upload%2F50ed9020-7b58-4dd9-aa39-ff06b9e0df12.png\"}]",
"qualities": [
"360p",
"540p"
]
},
{
"display_name": "Crazy Cat Woman",
"workflow_tag": "cat_woman_241121",
"template_id": 307489548427968,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2FCrazyCatWoman.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-11-22T08:22:15Z",
"updated_at": "2024-12-26T07:40:24Z",
"display_prompt": "Transform into a Crazy Cat Woman and slay",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"疯狂猫女变身\",\"display_prompt\":\"变身妖娆猫女,撩翻全场!\"}}",
"example_list": "[{\"img_id\":113742074,\"img_url\":\"https://media.pixverse.ai/upload%2F50ed9020-7b58-4dd9-aa39-ff06b9e0df12.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"},{\"img_id\":113750791,\"img_url\":\"https://media.pixverse.ai/upload%2Ff2853009-8238-4e0f-93ec-cfc68fee28b7.png\"}]",
"qualities": [
"360p",
"540p"
]
},
{
"display_name": "Wonder Woman",
"workflow_tag": "wonder_woman_241202",
"template_id": 309283958194560,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2FWonderWoman.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-12-02T11:45:11Z",
"updated_at": "2024-12-26T07:40:35Z",
"display_prompt": "Transform into Wonder Woman and conquer the impossible",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"神奇女侠变身\",\"display_prompt\":\"成为神奇女侠,征服一切不可能\"}}",
"example_list": "[{\"img_id\":113742074,\"img_url\":\"https://media.pixverse.ai/upload%2F50ed9020-7b58-4dd9-aa39-ff06b9e0df12.png\"},{\"img_id\":113750791,\"img_url\":\"https://media.pixverse.ai/upload%2Ff2853009-8238-4e0f-93ec-cfc68fee28b7.png\"}]",
"qualities": [
"360p",
"540p"
]
},
{
"display_name": "Hulk",
"workflow_tag": "hulk_241106",
"template_id": 304826314164992,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2FHulk.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-11-07T07:08:47Z",
"updated_at": "2024-12-26T07:38:48Z",
"display_prompt": "Unleash the Beast",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"召唤绿巨人\",\"display_prompt\":\"变身成绿巨人并捶爆一切\"}}",
"example_list": "[{\"img_id\":113750602,\"img_url\":\"https://media.pixverse.ai/upload%2F920dc791-8c9f-4518-8761-82958a827190.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"},{\"img_id\":113750791,\"img_url\":\"https://media.pixverse.ai/upload%2Ff2853009-8238-4e0f-93ec-cfc68fee28b7.png\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Joker's Rebirth",
"workflow_tag": "joker_241106",
"template_id": 304826126435072,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_joker.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-11-07T07:07:16Z",
"updated_at": "2024-12-26T07:38:54Z",
"display_prompt": "Transform into a Joker",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"小丑重生\",\"display_prompt\":\"变身成小丑,诡异地微笑\"}}",
"example_list": "[{\"img_id\":113750602,\"img_url\":\"https://media.pixverse.ai/upload%2F920dc791-8c9f-4518-8761-82958a827190.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"},{\"img_id\":113750791,\"img_url\":\"https://media.pixverse.ai/upload%2Ff2853009-8238-4e0f-93ec-cfc68fee28b7.png\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Batman",
"workflow_tag": "bat_man_241106",
"template_id": 304826374632192,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_batman.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-11-07T07:09:17Z",
"updated_at": "2024-12-26T07:39:00Z",
"display_prompt": "Transform into a Batman and embrace the night",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"蝙蝠侠归来\",\"display_prompt\":\"变身成蝙蝠侠并守护黑夜\"}}",
"example_list": "[{\"img_id\":113741803,\"img_url\":\"https://media.pixverse.ai/upload%2Fb2626bc2-050d-4ea6-a864-e2054c012df5.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Iron Man",
"workflow_tag": "iron_man_241106",
"template_id": 304826054394624,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_ironman.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-11-07T07:06:40Z",
"updated_at": "2024-12-26T07:39:06Z",
"display_prompt": "Activate Iron Mode",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"钢铁侠变身\",\"display_prompt\":\"激活钢铁模式\"}}",
"example_list": "[{\"img_id\":113741803,\"img_url\":\"https://media.pixverse.ai/upload%2Fb2626bc2-050d-4ea6-a864-e2054c012df5.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Hair Growth Magic",
"workflow_tag": "hair_magic_241128",
"template_id": 308552687706496,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_hairgrowth.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-11-28T08:34:06Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "Grow lots of hair. Never be bald.",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"发量王者\",\"display_prompt\":\"长出迷人秀发,永无秃头困扰。\"}}",
"example_list": "[{\"img_id\":113750602,\"img_url\":\"https://media.pixverse.ai/upload%2F920dc791-8c9f-4518-8761-82958a827190.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"},{\"img_id\":113750791,\"img_url\":\"https://media.pixverse.ai/upload%2Ff2853009-8238-4e0f-93ec-cfc68fee28b7.png\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "COLORFUL Venom!",
"workflow_tag": "random_venom_241104",
"template_id": 304358279051648,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_colorfulvenom.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-11-04T15:39:54Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "Transform into a [COLORFUL] Venom",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"毒液!(彩色盲盒版)\",\"display_prompt\":\"变身成为【彩色】毒液\"}}",
"example_list": "[{\"img_id\":113741803,\"img_url\":\"https://media.pixverse.ai/upload%2Fb2626bc2-050d-4ea6-a864-e2054c012df5.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"}]",
"qualities": [
"360p",
"540p"
]
},
{
"display_name": "Who is Venom?",
"workflow_tag": "who_is_venom_241112",
"template_id": 305714097668480,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_whoisvenom.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-11-12T07:33:35Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "Which one of you guys is Venom? ",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"测测谁是毒液?\",\"display_prompt\":\"两人之中,必有一毒,速速现出原形\"}}",
"example_list": "[{\"img_id\":111917190,\"img_url\":\"https://media.pixverse.ai/upload%2F6a6a0f6a-99be-4eac-83a1-9d265ca65823.png\"},{\"img_id\":111917753,\"img_url\":\"https://media.pixverse.ai/upload%2F079945d6-01aa-4688-9e9a-02e308c01db5.png\"},{\"img_id\":111917942,\"img_url\":\"https://media.pixverse.ai/upload%2F814307ed-4123-4f6b-a32e-4072b55378cb.png\"}]",
"qualities": [
"360p",
"540p"
]
},
{
"display_name": "Get a Venom buddy",
"workflow_tag": "baby_venom_241114",
"template_id": 306059795500352,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_venombuddy.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-11-14T06:26:53Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "Your Venom buddy appears and gives you a hug",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"召唤毒液兄弟\",\"display_prompt\":\"你的毒液兄弟回到你身边,并与你深情相拥\"}}",
"example_list": "[{\"img_id\":113741803,\"img_url\":\"https://media.pixverse.ai/upload%2Fb2626bc2-050d-4ea6-a864-e2054c012df5.png\"},{\"img_id\":113750690,\"img_url\":\"https://media.pixverse.ai/upload%2Fddd29e75-beeb-461c-9388-3e14c2709e73.png\"}]",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Wicked Shots",
"workflow_tag": "wicked_paintings_241028",
"template_id": 303788802773760,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_wickedshot.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-11-01T10:25:30Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "The [SUBJECT] in the picture smiles wickedly and starts firing",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"扫射一切\",\"display_prompt\":\"邪魅一笑,并掏出一把机关枪开始扫射\"}}",
"example_list": "",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Squish It",
"workflow_tag": "squish_it_241028",
"template_id": 302325299692608,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_squishit.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-10-24T03:55:29Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "A pair of hands appears and squishes the [OBJECT] as if it's slime",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"捏捏更解压\",\"display_prompt\":\"变成可以捏捏的软泥\"}}",
"example_list": "",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Lego Blast",
"workflow_tag": "lego_blast_241028",
"template_id": 302325299702848,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_legoblast.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-10-24T03:55:29Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "The [OBJECT] shatters into pieces of Legos",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"乐高大爆炸\",\"display_prompt\":\"爆炸并碎裂成一片片乐高积木\"}}",
"example_list": "",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Leggy Run",
"workflow_tag": "leggy_run_241028",
"template_id": 302325299711040,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_leggyrun.gif",
"thumbnail_video_path": "",
"marker": "hot",
"created_at": "2024-10-24T03:55:29Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "The [OBJECT] grows legs and runs away",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"全员腿精\",\"display_prompt\":\"长出了一双腿然后开始乱跑\"}}",
"example_list": "",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Monster Invades",
"workflow_tag": "monster_invasion_241028",
"template_id": 302325299682368,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_monster.gif",
"thumbnail_video_path": "",
"marker": "default",
"created_at": "2024-10-24T03:55:29Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "A monster suddenly appears in the [SCENE] and starts walking around",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"怪兽入侵\",\"display_prompt\":\"场景中突然出现了一只怪兽\"}}",
"example_list": "",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Wizard Hat",
"workflow_tag": "animal_wizard_241028",
"template_id": 302325299661888,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_wizardhat.gif",
"thumbnail_video_path": "",
"marker": "hot",
"created_at": "2024-10-24T03:55:29Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "The [SUBJECT] wears a magic wizard hat",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"戴上魔法帽\",\"display_prompt\":\"头顶出现了一顶可爱的魔法帽\"}}",
"example_list": "",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Zombie Hand",
"workflow_tag": "zombie_hand_241028",
"template_id": 302325299672128,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_weirdhand.gif",
"thumbnail_video_path": "",
"marker": "hot",
"created_at": "2024-10-24T03:55:29Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "A zombie hand appears in the [SCENE]",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"僵尸手出没\",\"display_prompt\":\"从图片中的场景中钻出一只僵尸的手\"}}",
"example_list": "",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
},
{
"display_name": "Zombie Mode",
"workflow_tag": "zombie_mode_241028",
"template_id": 302325299651648,
"thumbnail_path": "https://media.pixverse.ai/asset%2Ftemplate%2Fcapcut_zombiemode.gif",
"thumbnail_video_path": "",
"marker": "hot",
"created_at": "2024-10-24T03:55:29Z",
"updated_at": "2024-12-25T10:19:28Z",
"display_prompt": "The [SUBJECT] suddenly transforms into a zombie.",
"i18n_json": "{\"zh-CN\":{\"display_name\":\"坏了,我变僵尸了\",\"display_prompt\":\"突然变成僵尸\"}}",
"example_list": "",
"qualities": [
"360p",
"540p",
"720p",
"1080p"
]
}
]
|
上市了!")