上市了!")



本文将介绍一种 Flux Images Generation API 对接说明,它是可以通过输入自定义参数来生成 Flux 官方的图片。
申请流程
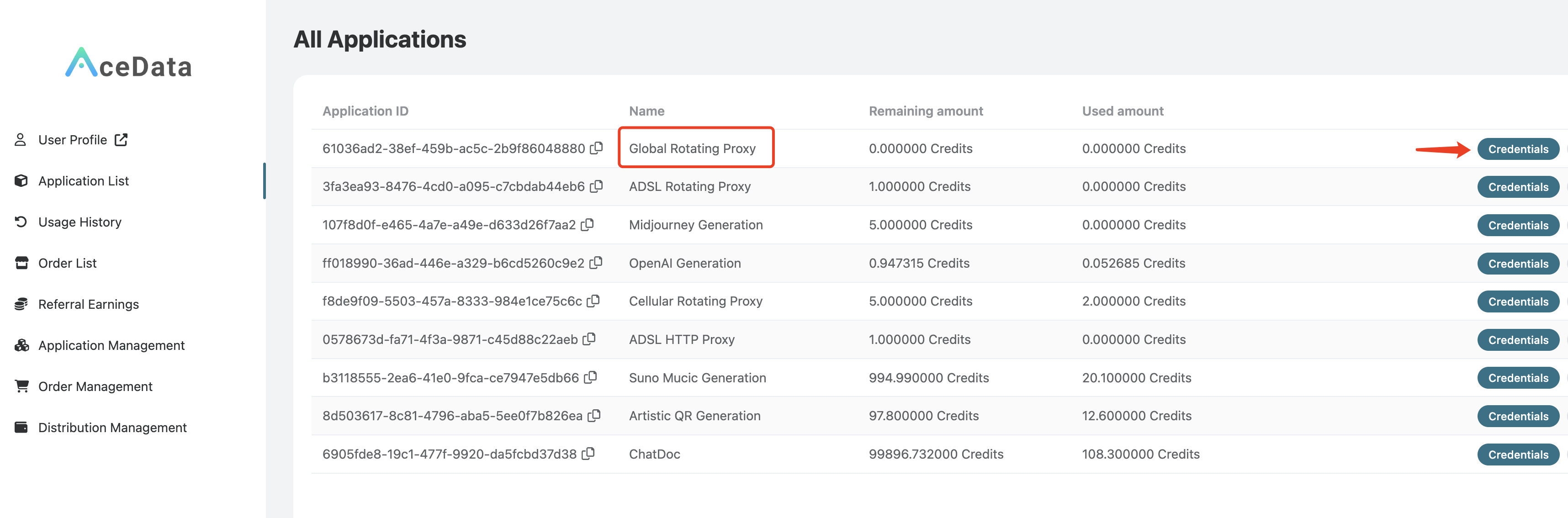
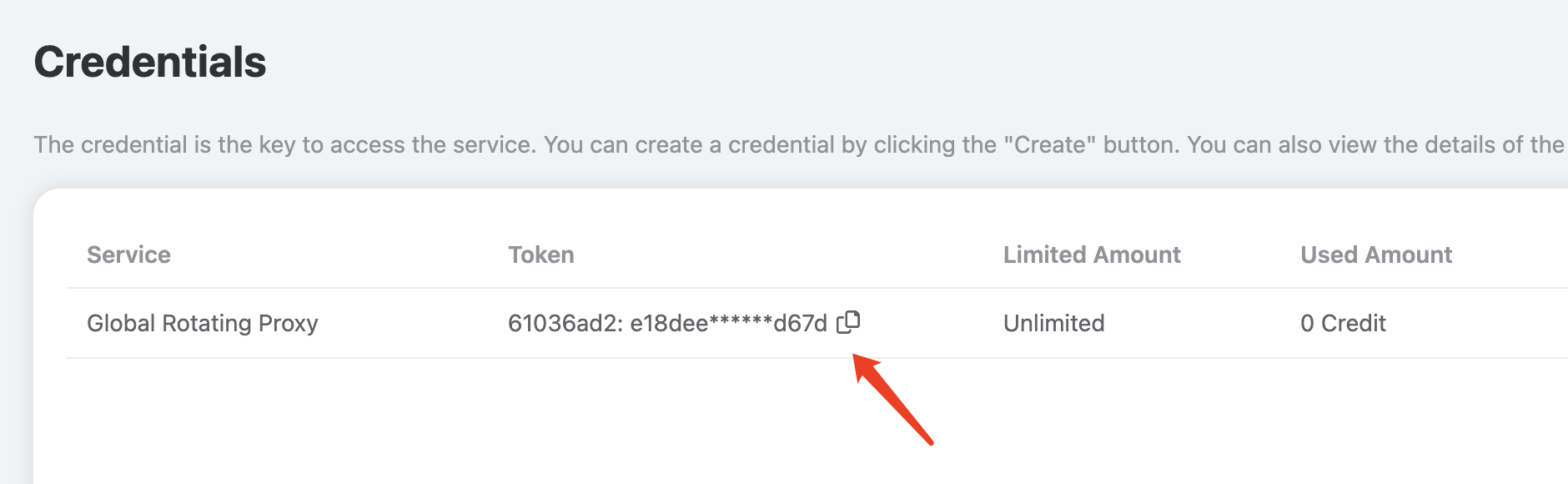
要使用 Flux Images Generation API,首先到 Ace Data Cloud 控制台 获取您的 API Token,留作备用。
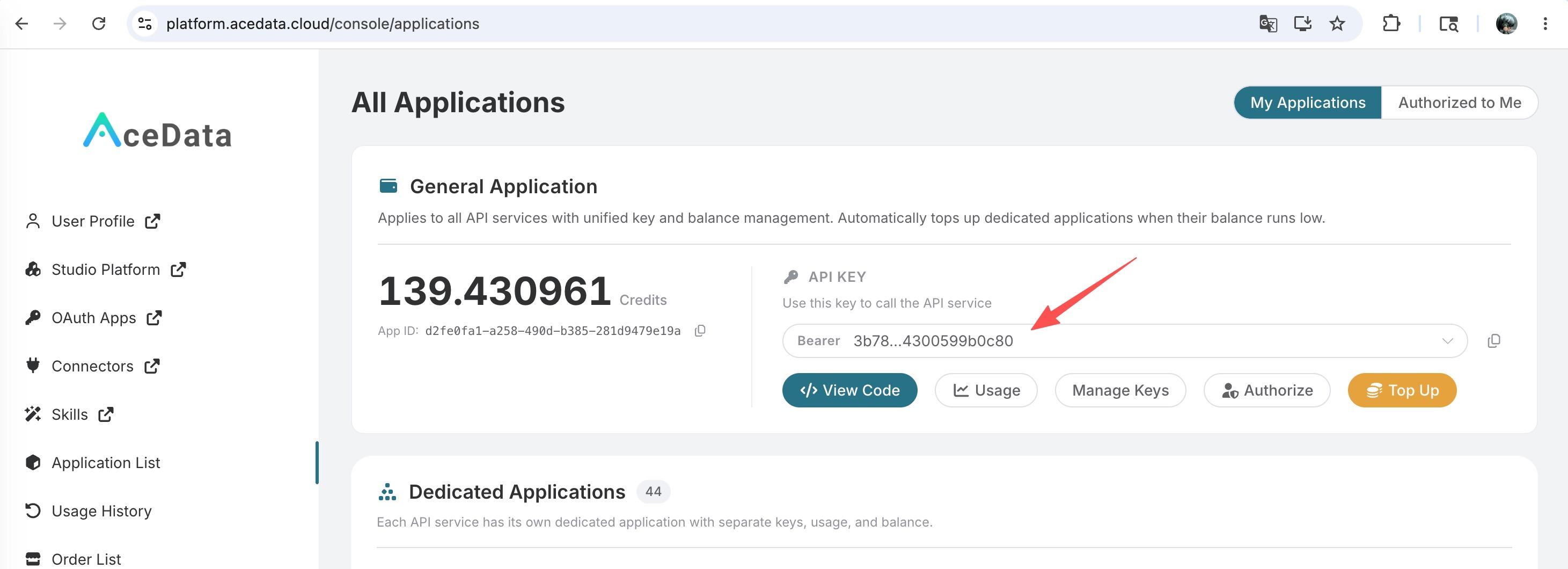
如果你尚未登录或注册,会自动跳转到登录页面邀请你注册和登录,完成后会自动返回当前页面。
一个 API Token 即可调用平台所有服务,无需为每个服务单独申请。 首次申请会赠送免费额度,可免费体验;额度不足时可在 控制台 充值通用余额。
📘 完整文档:Flux Images Generation API →
基本使用
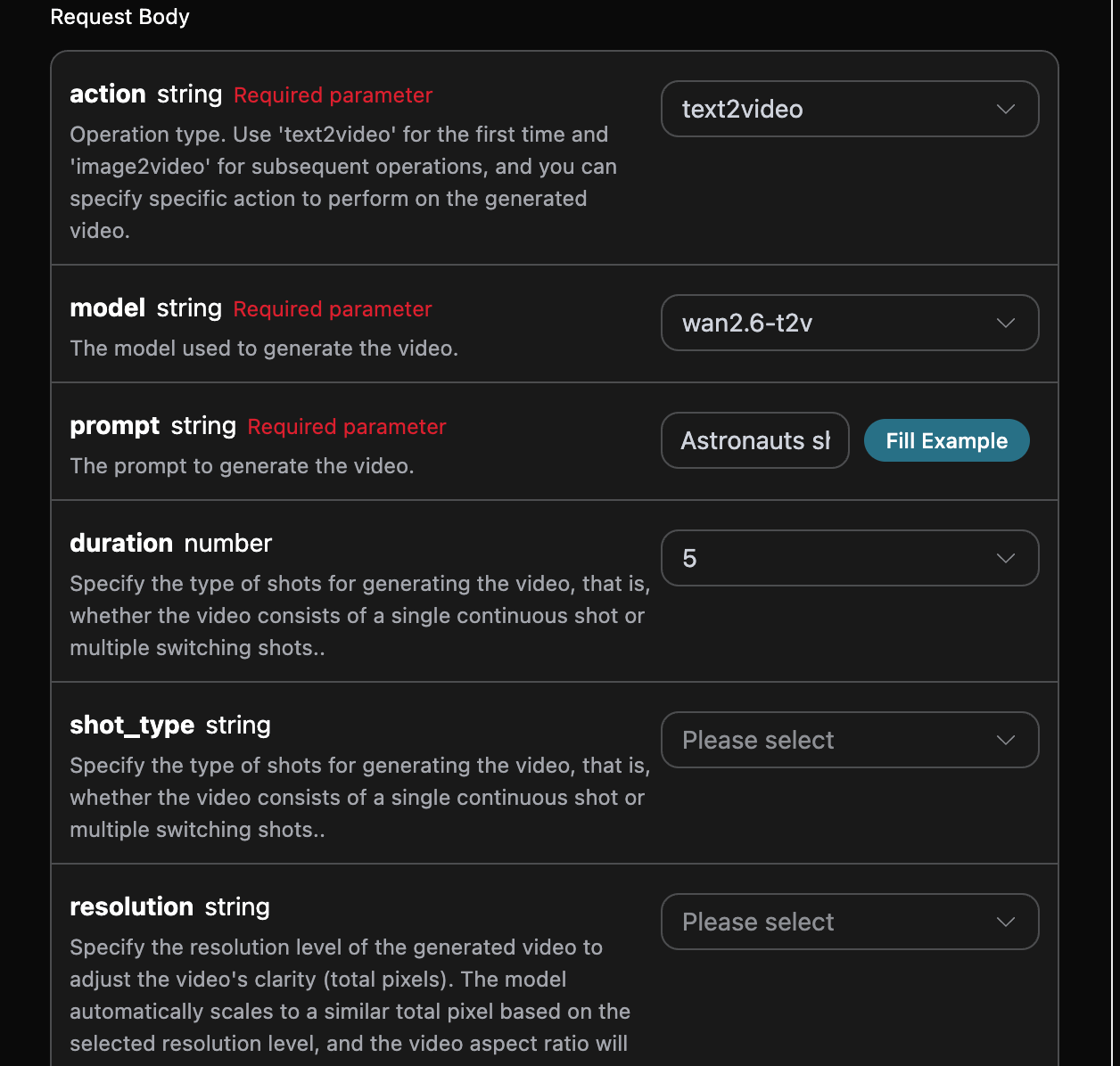
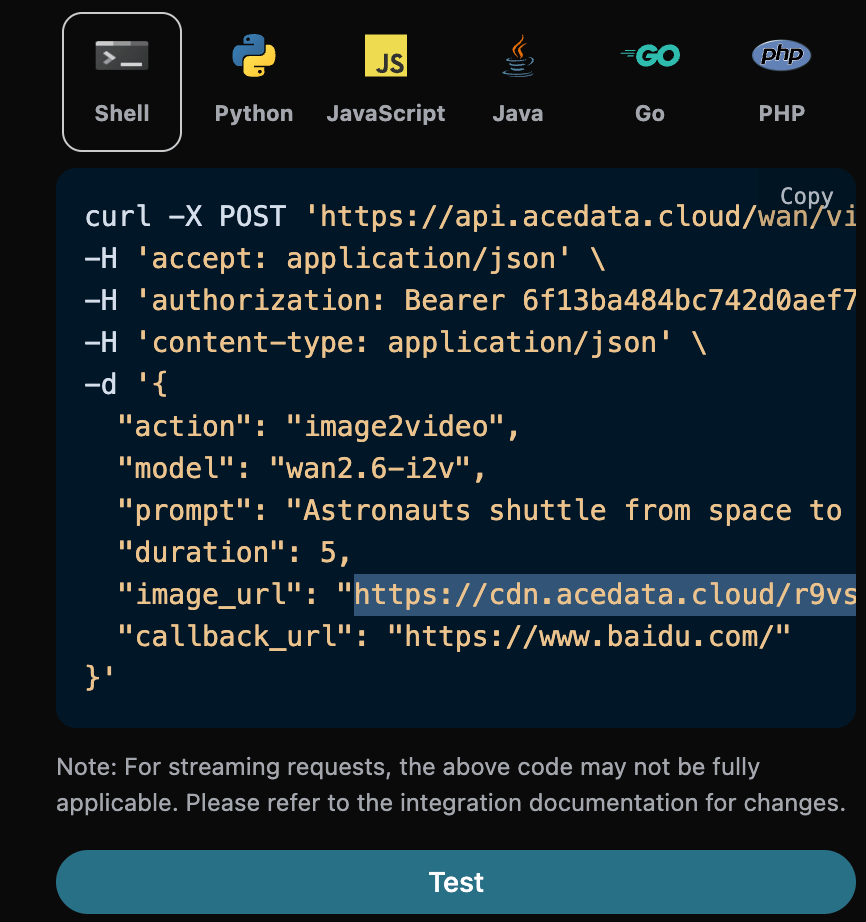
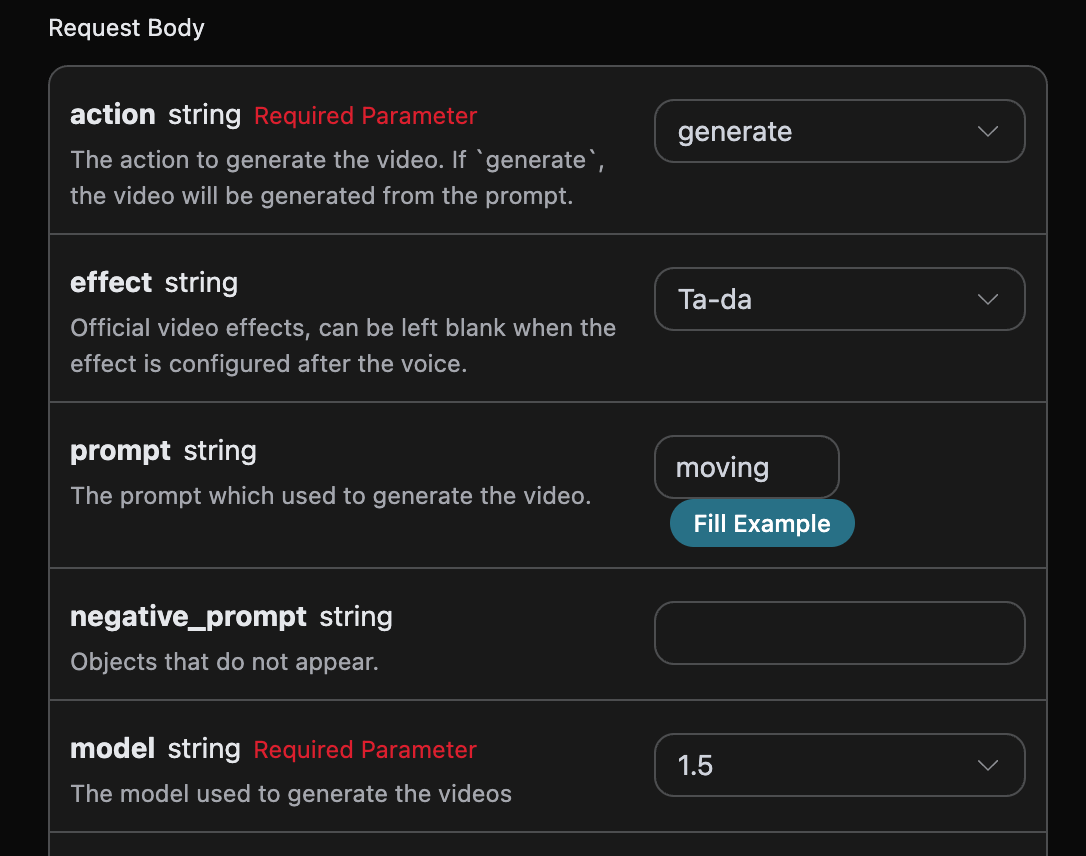
首先先了解下基本的使用方式,就是输入提示词 prompt、 生成行为 action、图片尺寸 size,便可获得处理后的结果,首先需要简单地传递一个 action 字段,它的值为 generate,然后我们还需要输入提示词,具体的内容如下:
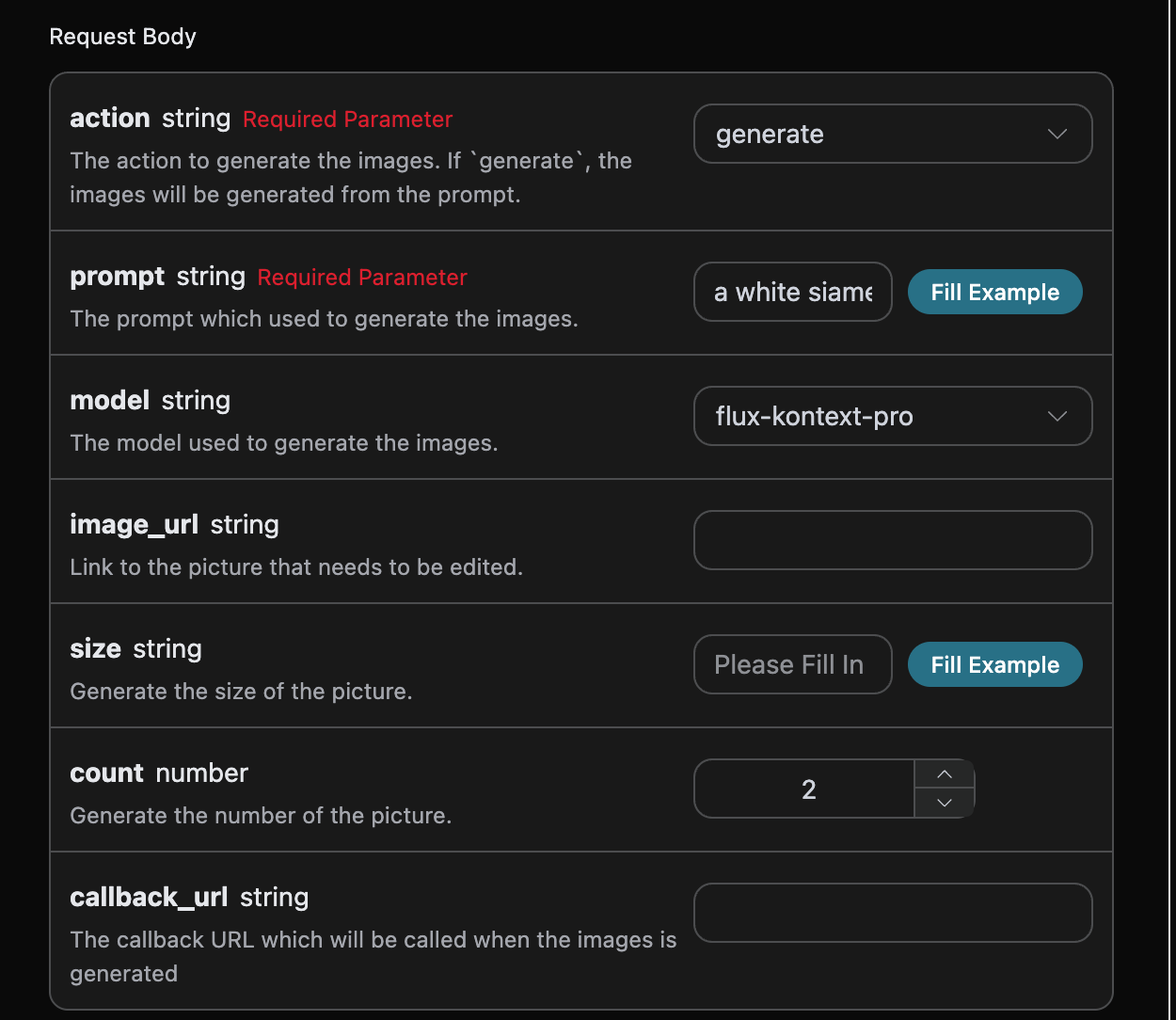
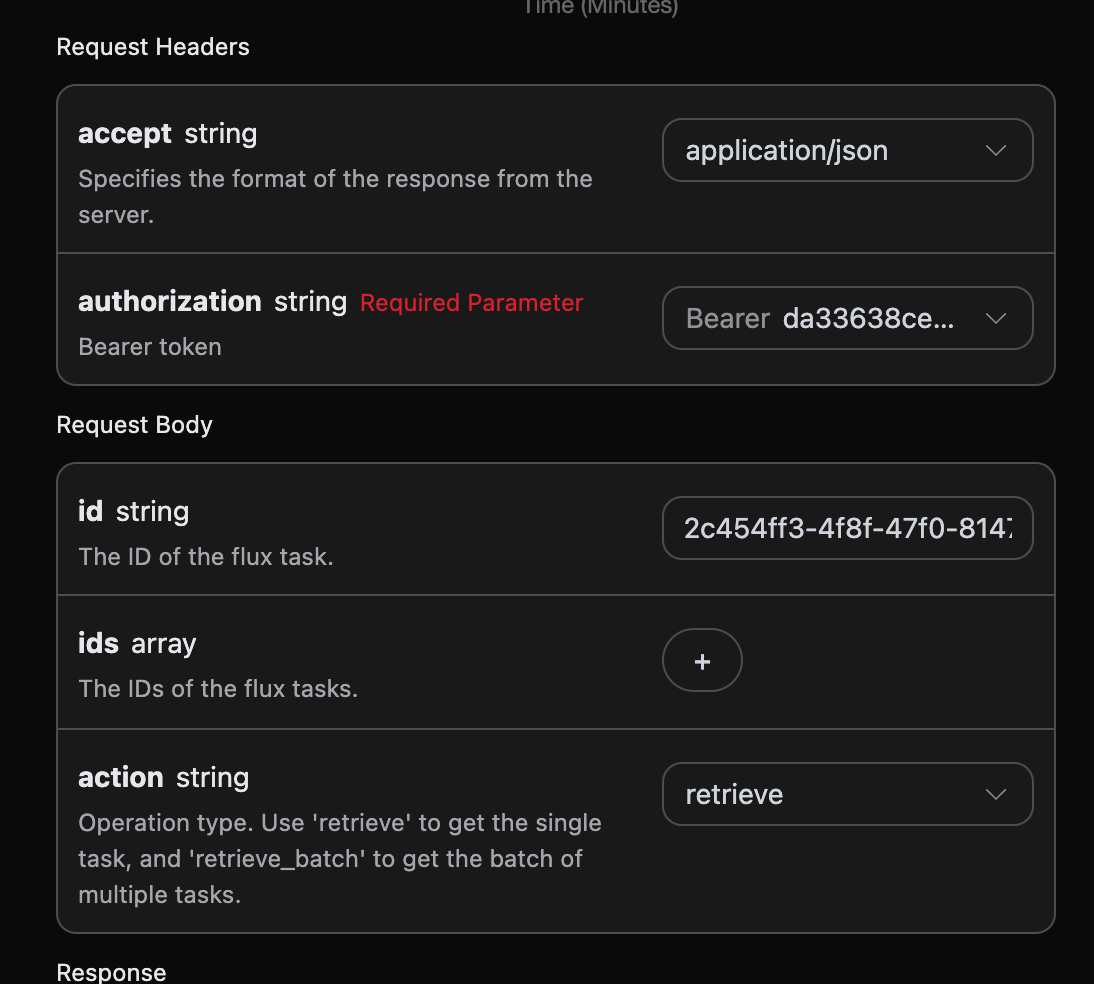
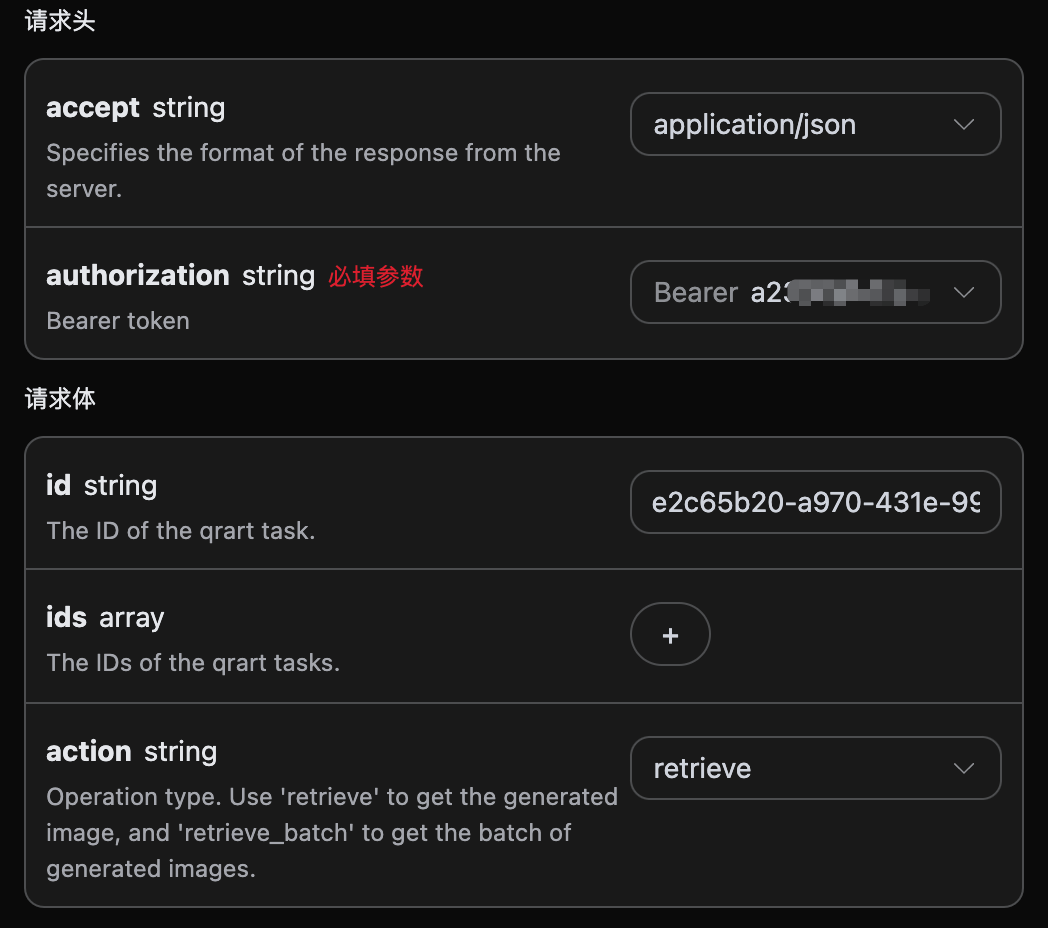
可以看到这里我们设置了 Request Headers,包括:
accept:想要接收怎样格式的响应结果,这里填写为application/json,即 JSON 格式。authorization:调用 API 的密钥,申请之后可以直接下拉选择。
另外设置了 Request Body,包括:
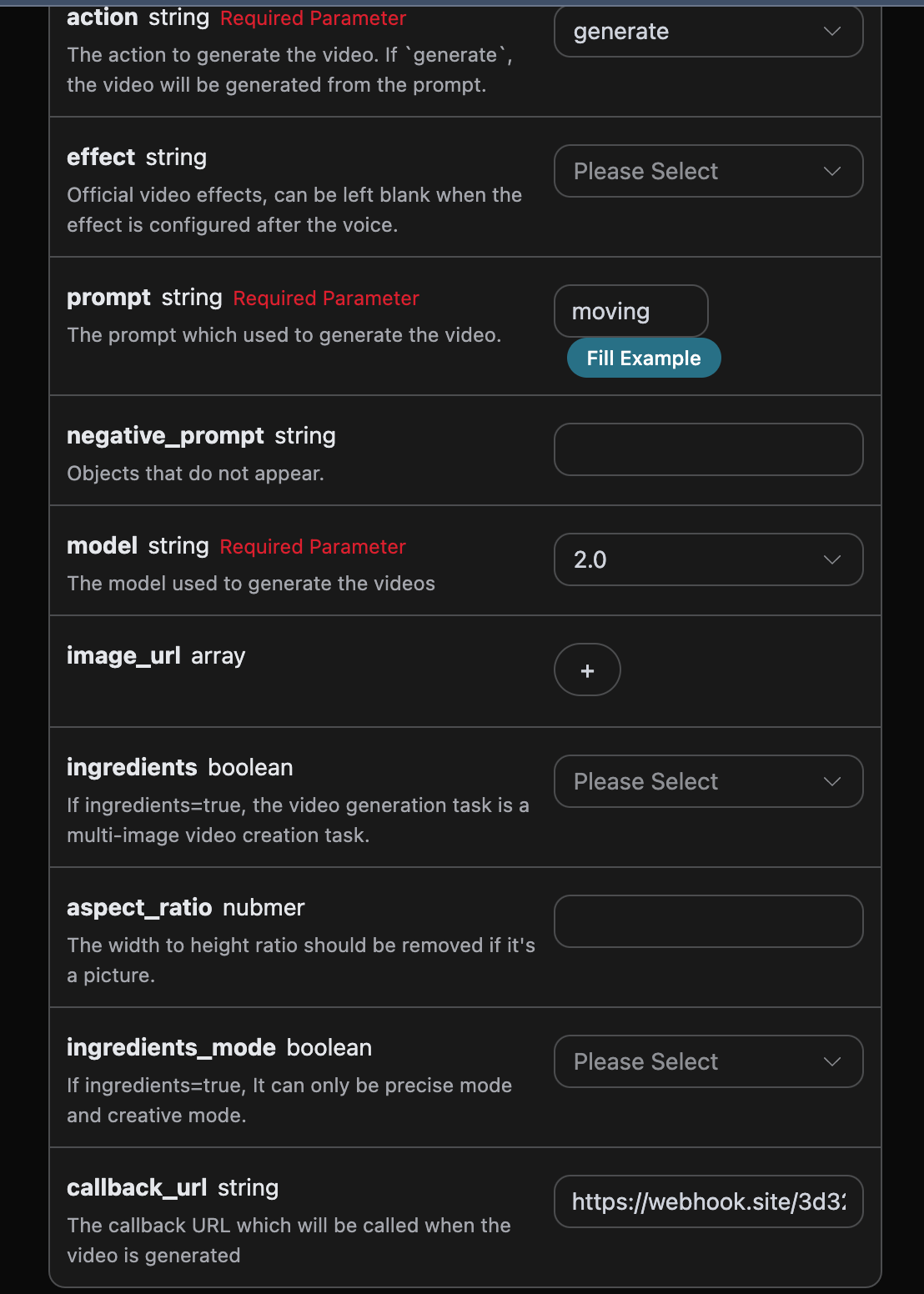
action:此次图片生成任务的行为。size:图片生成结果的尺寸大小。flux-2-flex/flux-2-pro/flux-2-max系列必须传入图片比例(如1:1、16:9),不接受1024x1024这类像素尺寸,缺省会返回 400。count:生成图片的数量,默认值是 1,该参数只有在生成图片任务有效,编辑任务是无效的。prompt:提示词。model:生成模型,默认flux-dev;最新旗舰为flux-2-pro、flux-2-max(画质更高,需配合图片比例size)。callback_url:需要回调结果的 URL。async:可选,设为true时接口立即返回task_id,无需提供callback_url,随后通过对应的任务查询接口轮询获取结果。
参数 size有一些特别限制,主要分为width x height宽高比例、x:y 图片比例俩种类型,具体的如下:
| 模型 | 范围 |
|---|---|
| flux-dev | 支持宽高比例 1024x1024、1024x1792、1792x1024,或图片比例 |
| flux-pro | 支持宽高比例 1024x1024、1024x1792、1792x1024,或图片比例 |
| flux-2-flex | 仅支持图片比例 |
| flux-2-pro | 仅支持图片比例 |
| flux-2-max | 仅支持图片比例 |
| flux-kontext-pro | 仅支持图片比例 |
| flux-kontext-max | 仅支持图片比例 |
参考的图片比例: “21:9”, “16:9”, “4:3”, “3:2”, “1:1”, “2:3”, “3:4”, “9:16”, “9:21”。
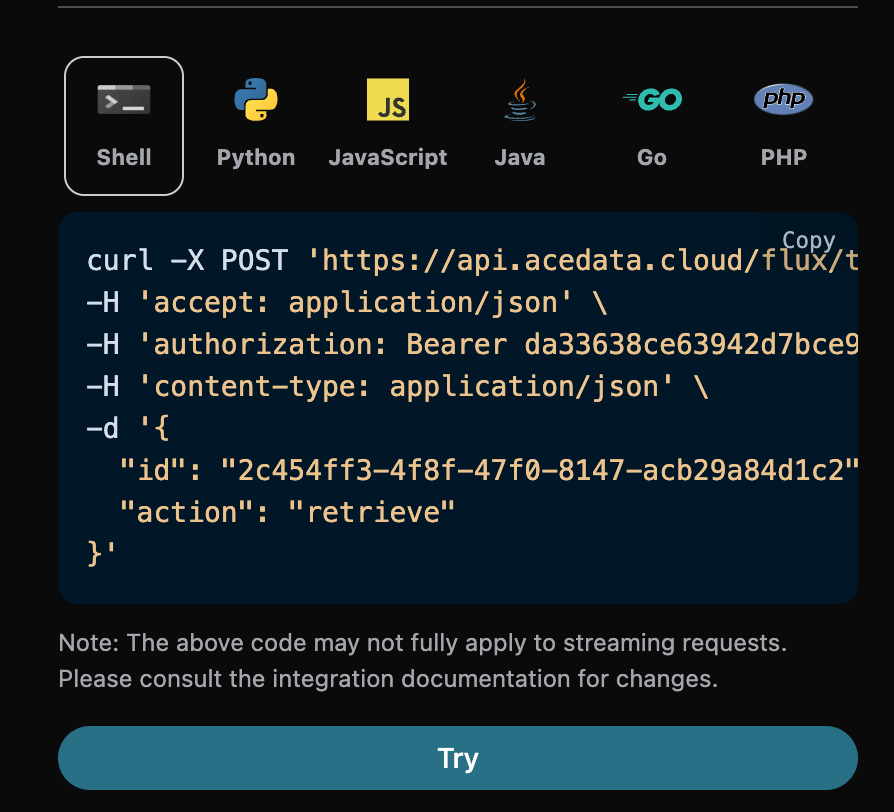
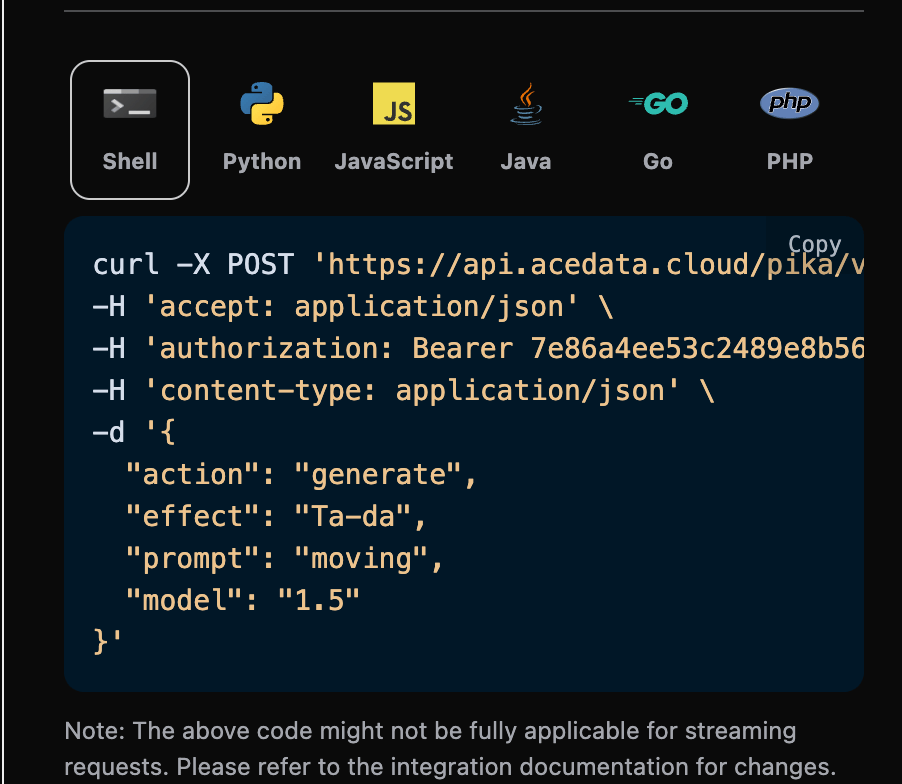
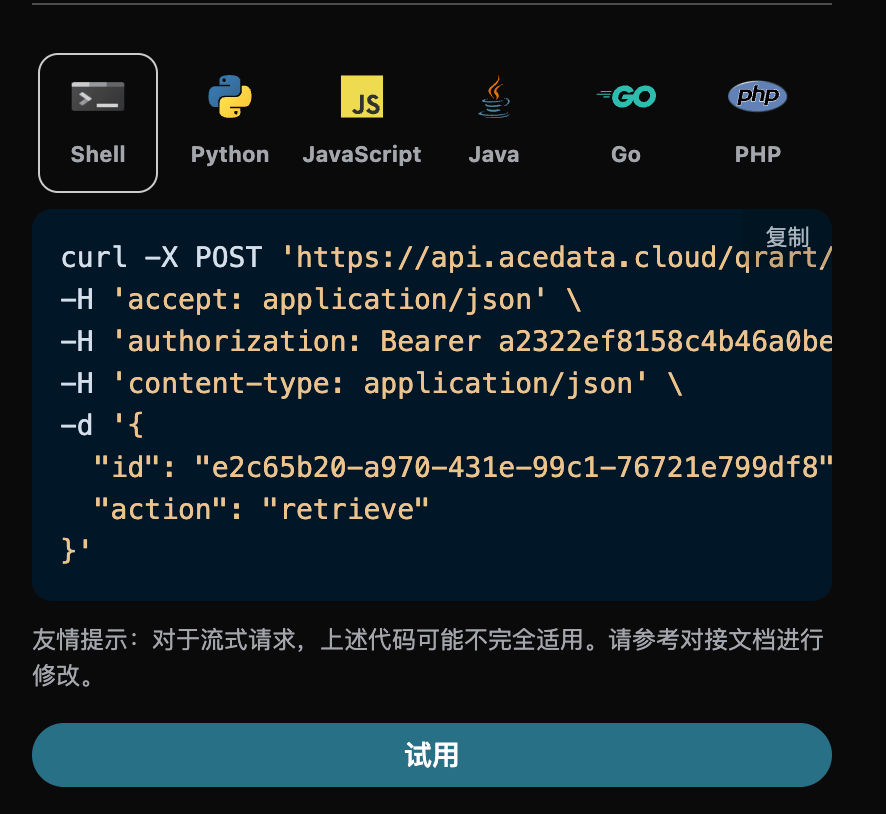
选择之后,可以发现右侧也生成了对应代码,如图所示:
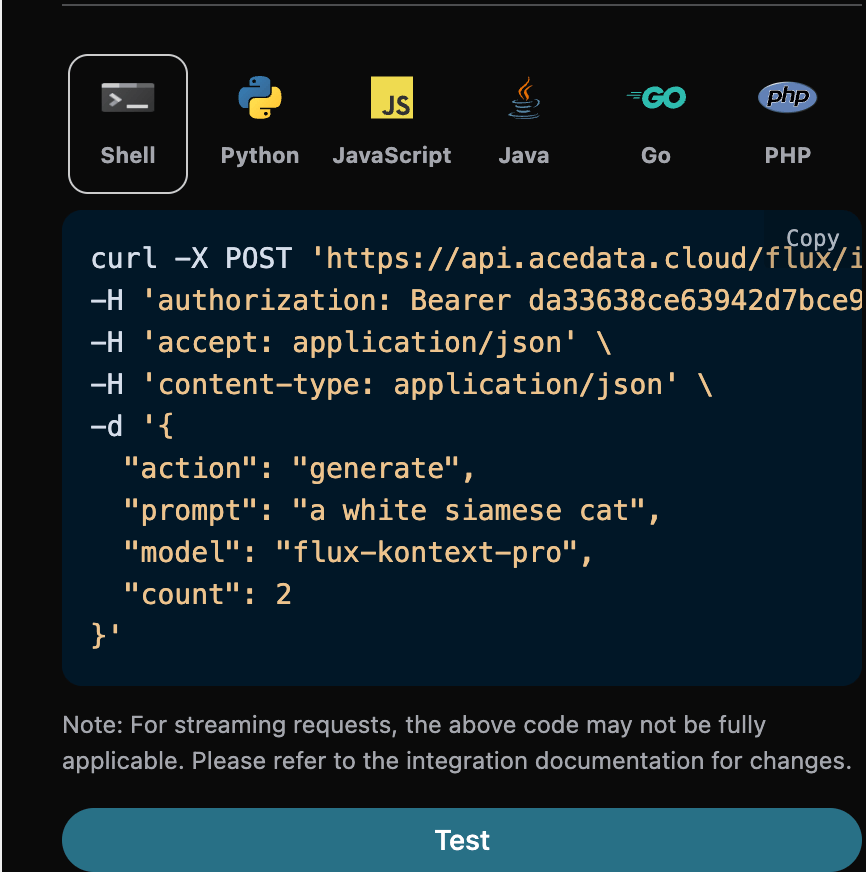
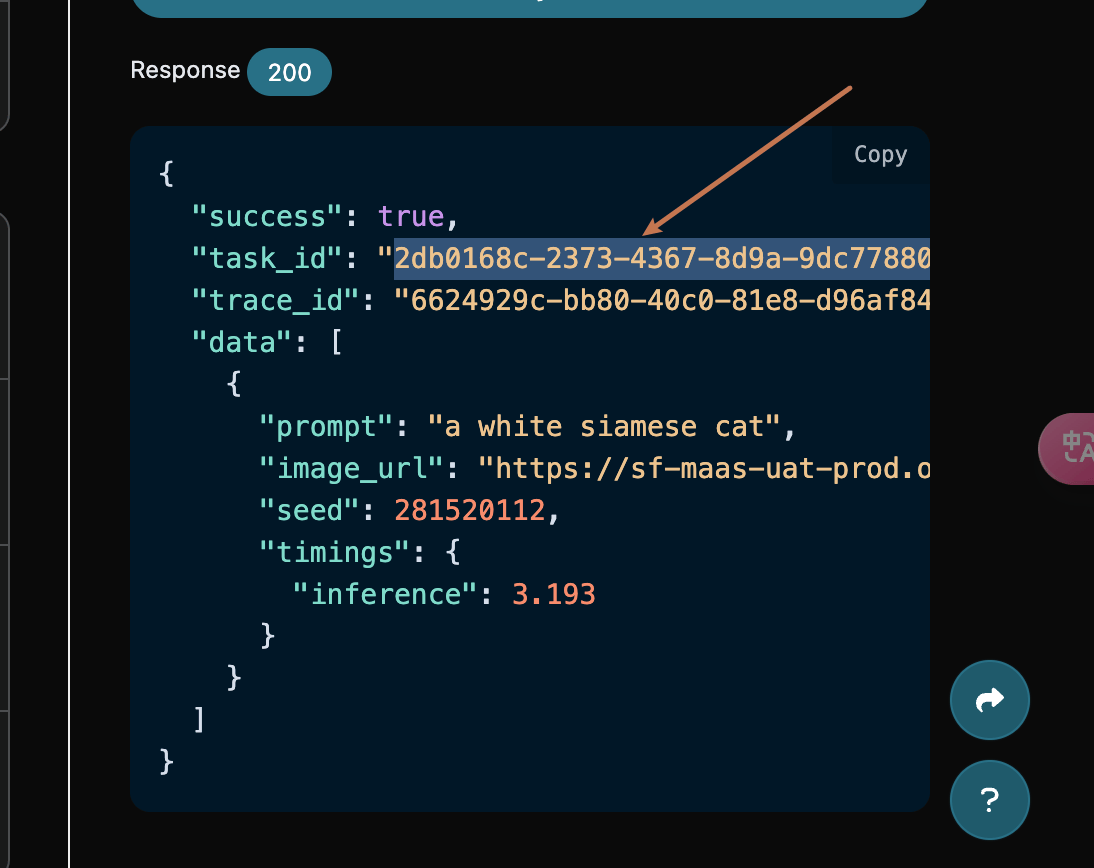
点击「Try」按钮即可进行测试,如上图所示,这里我们就得到了如下结果:
1 |
{ |
返回结果一共有多个字段,介绍如下:
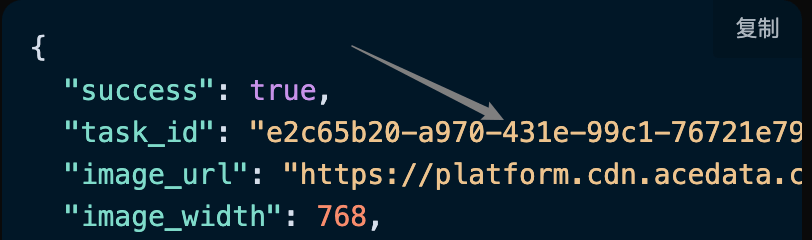
success,此时视频生成任务的状态情况。task_id,此时视频生成任务 ID。trace_id,此时视频生成跟踪 ID。data,此时图像生成任务的结果列表。image_url,此时图片生成任务的链接。prompt,提示词。
可以看到我们得到了满意的图片信息,我们只需要根据结果中 data 的图片链接地址获取生成的 Flux 图片即可。
另外如果想生成对应的对接代码,可以直接复制生成,例如 CURL 的代码如下:
1 |
curl -X POST 'https://api.acedata.cloud/flux/images' \ |
编辑图片任务
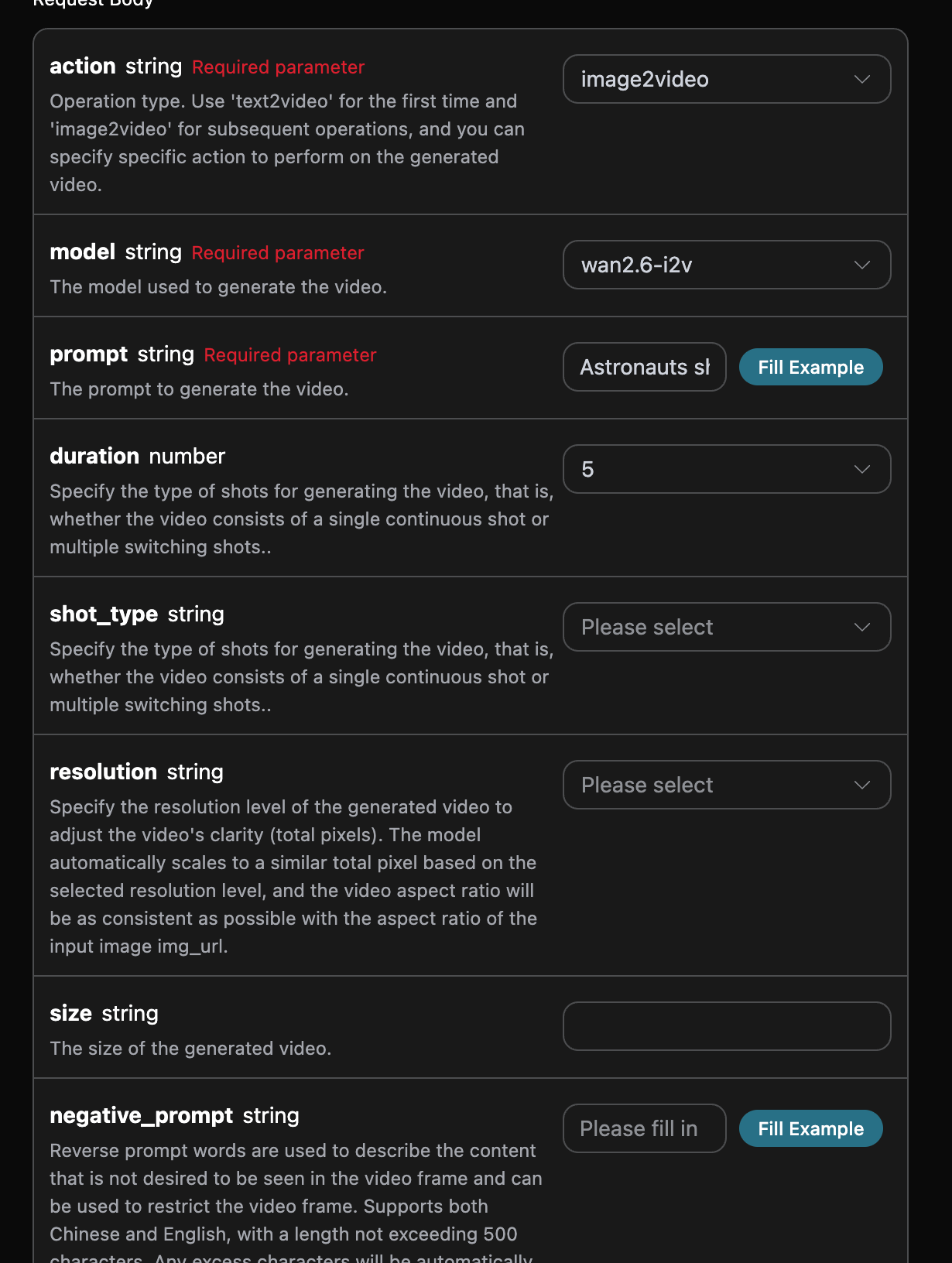
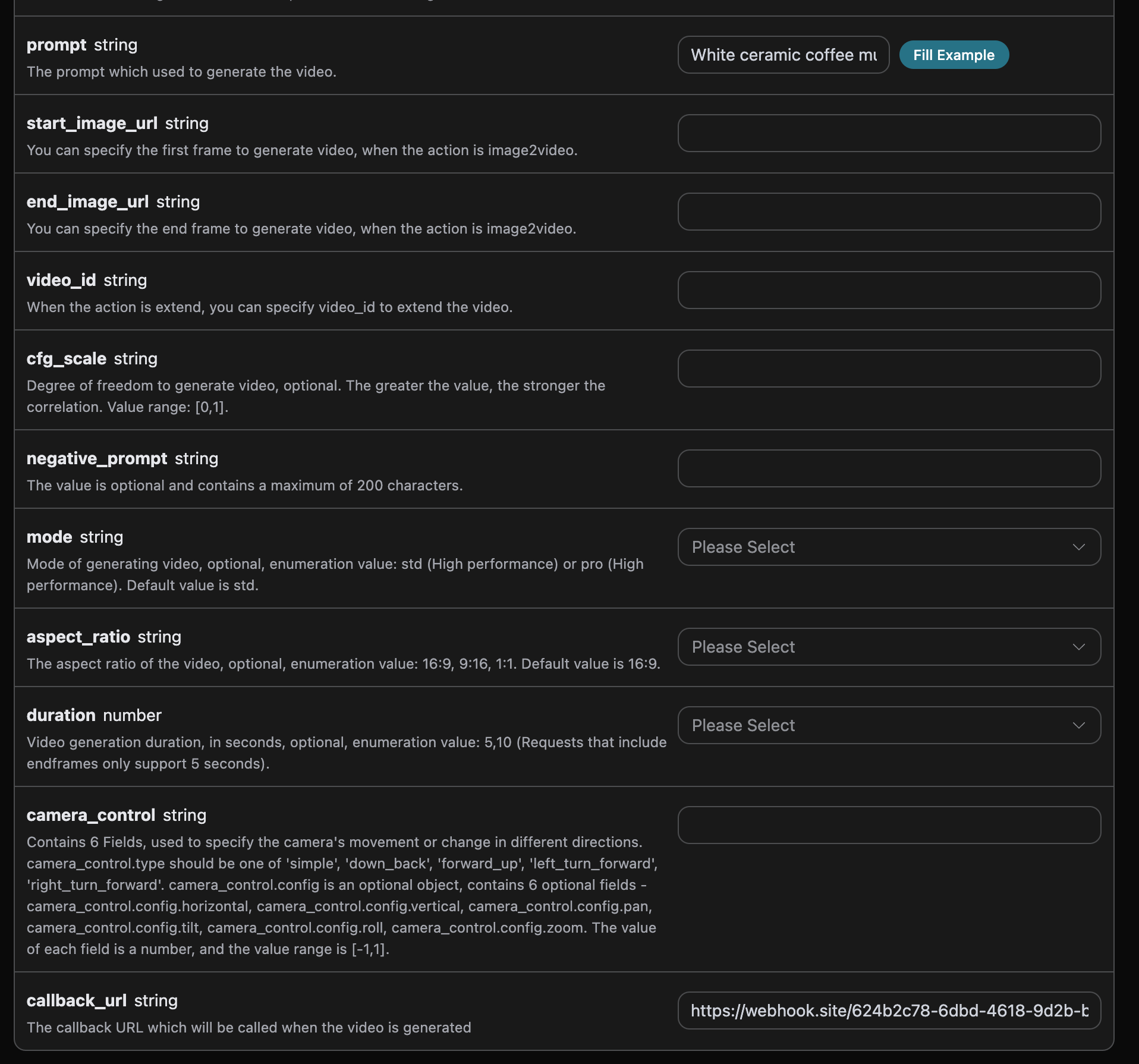
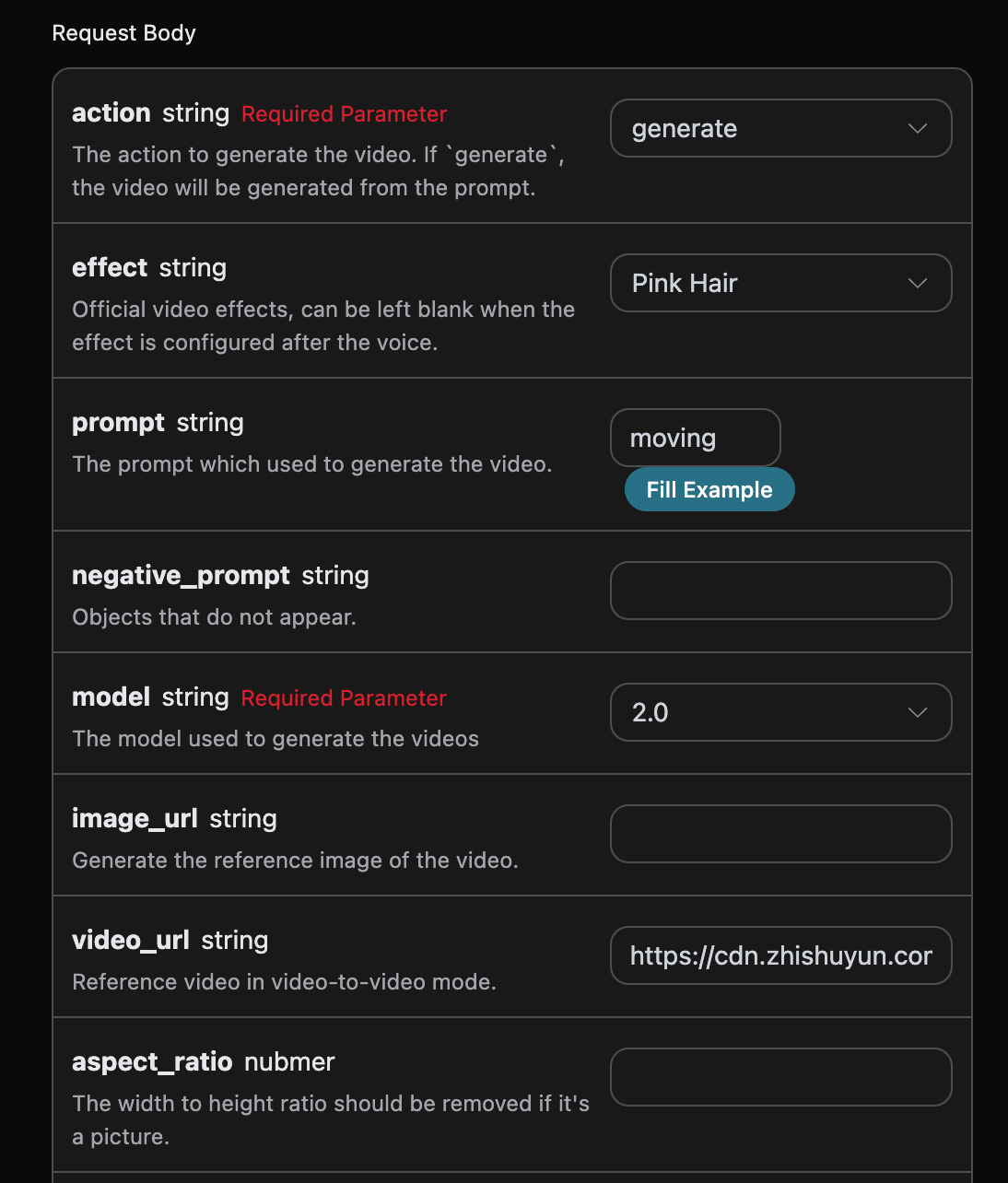
如果想对某张图片进行编辑的话, 首先参数image_url必须传入需要编辑的图片链接,此时 action 只支持 edit,就可以指定如下内容:
- model:此次编辑图片任务所采用的模型,支持
flux-dev、flux-pro、flux-kontext-pro、flux-kontext-max、flux-2-flex、flux-2-pro、flux-2-max。 - image_url:上传需要编辑的图片。
填写样例如下:
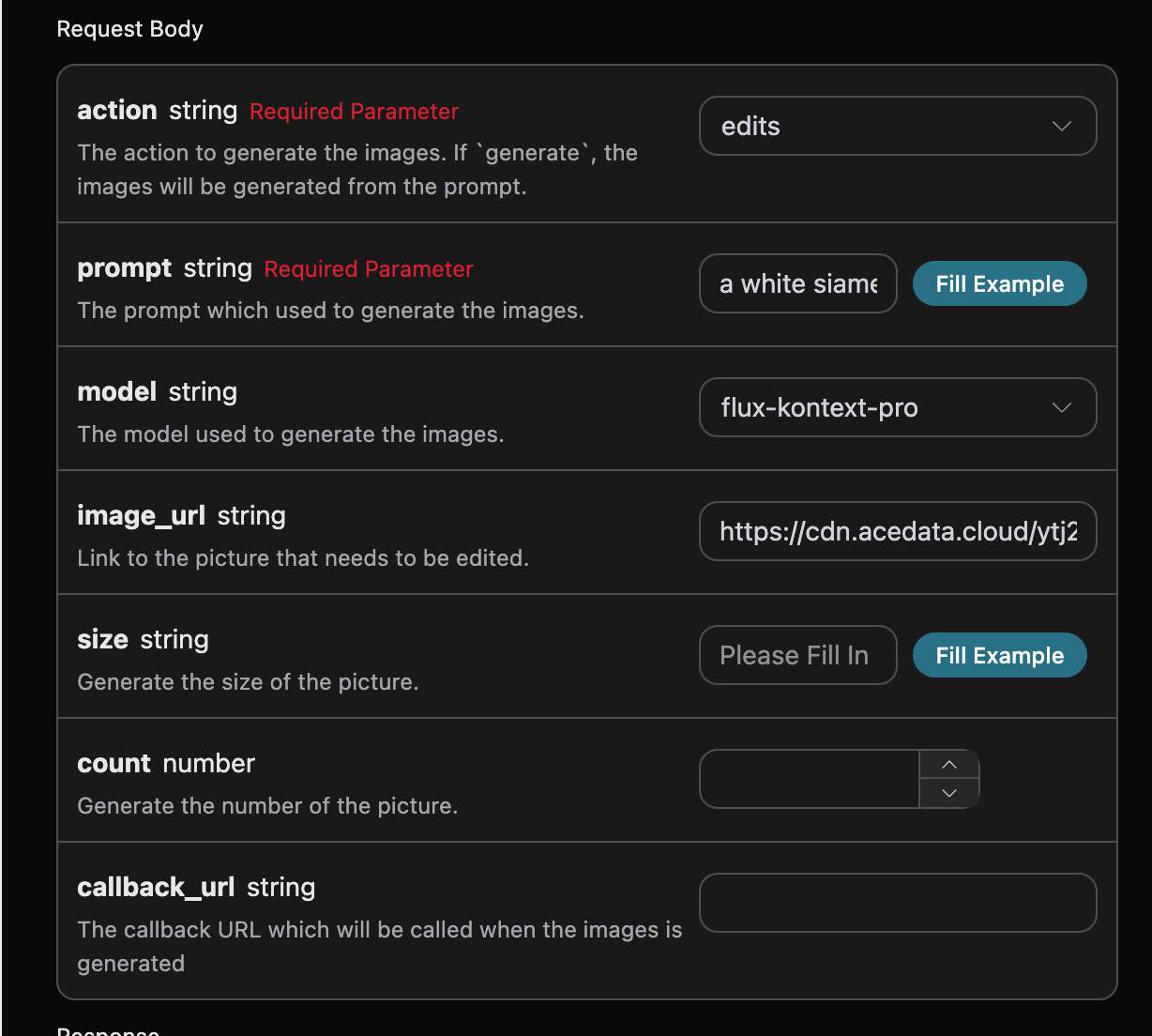
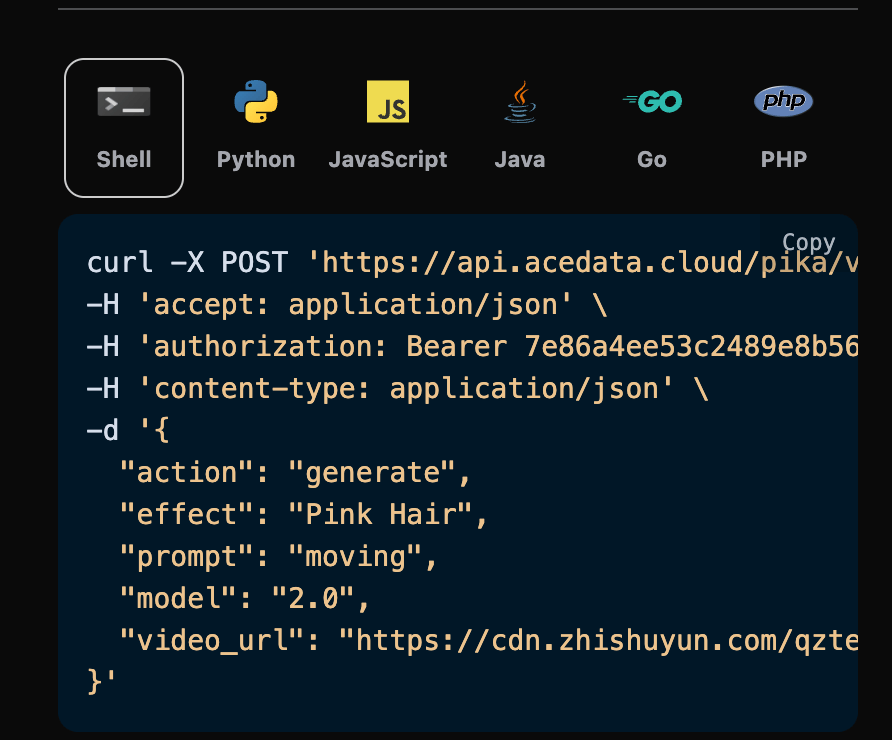
填写完毕之后自动生成了代码如下:
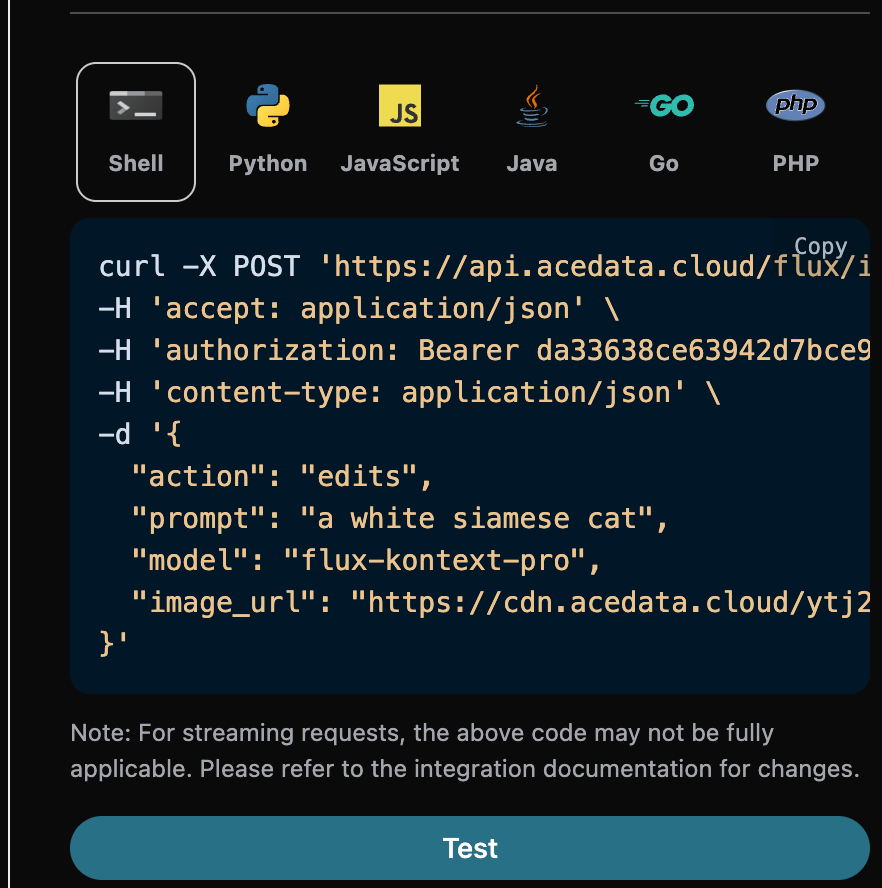
对应的代码:
1 |
import requests |
点击运行,可以发现会立即得到一个结果,如下:
1 |
{ |
可以看到,生成的效果是对原图片进行编辑的效果,结果与上文类似。
异步回调
由于 Flux Images Generation API 生成的时间相对较长,大约需要 1-2 分钟,如果 API 长时间无响应,HTTP 请求会一直保持连接,导致额外的系统资源消耗,所以本 API 也提供了异步回调的支持。
整体流程是:客户端发起请求的时候,额外指定一个 callback_url 字段,客户端发起 API 请求之后,API 会立马返回一个结果,包含一个 task_id 的字段信息,代表当前的任务 ID。当任务完成之后,生成图片的结果会通过 POST JSON 的形式发送到客户端指定的 callback_url,其中也包括了 task_id 字段,这样任务结果就可以通过 ID 关联起来了。
下面我们通过示例来了解下具体怎样操作。
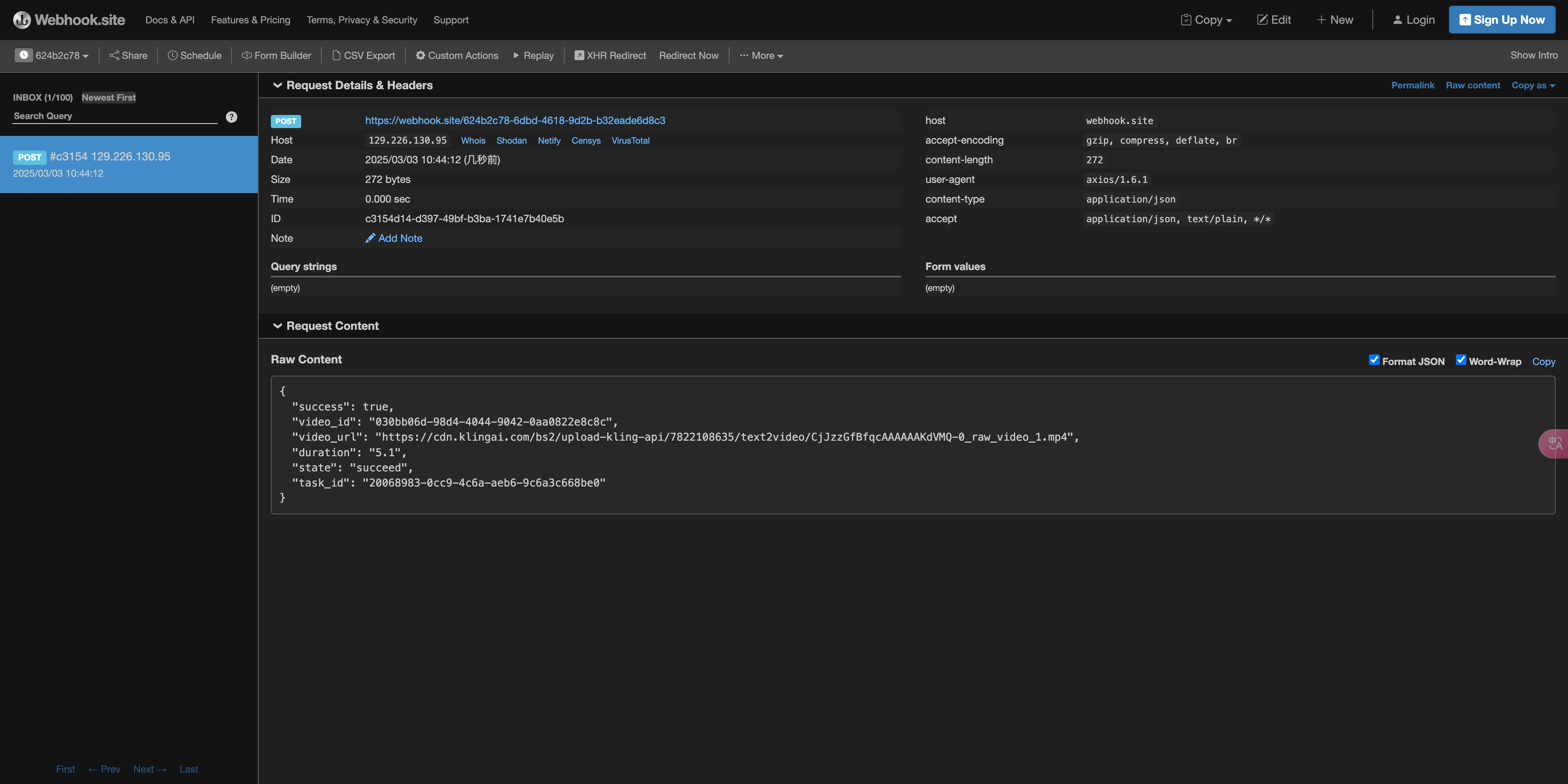
首先,Webhook 回调是一个可以接收 HTTP 请求的服务,开发者应该替换为自己搭建的 HTTP 服务器的 URL。此处为了方便演示,使用一个公开的 Webhook 样例网站 https://webhook.site/,打开该网站即可得到一个 Webhook URL,如图所示:

将此 URL 复制下来,就可以作为 Webhook 来使用,此处的样例为 https://webhook.site/3d32690d-6780-4187-a65c-870061e8c8ab。
接下来,我们可以设置字段 callback_url 为上述 Webhook URL,同时填入相应的参数,具体的内容如图所示:
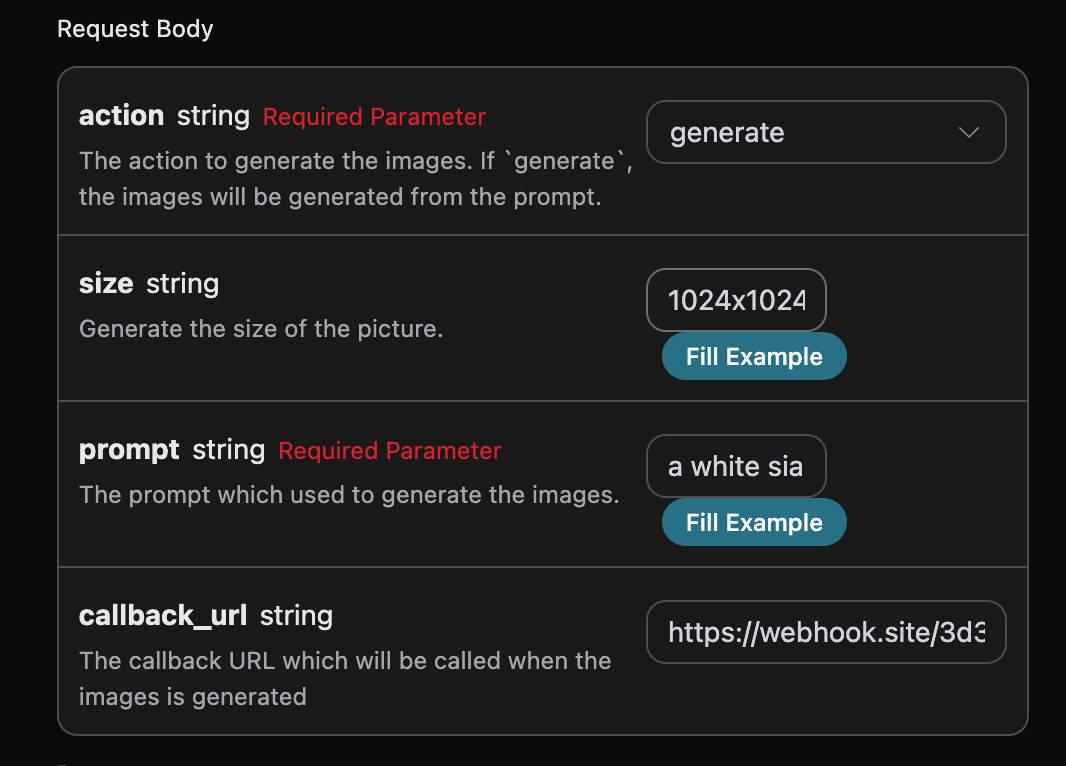
点击运行,可以发现会立即得到一个结果,如下:
1 |
{ |
稍等片刻,我们可以在 https://webhook.site/3d32690d-6780-4187-a65c-870061e8c8ab 上观察到生成图片的结果,如图所示:
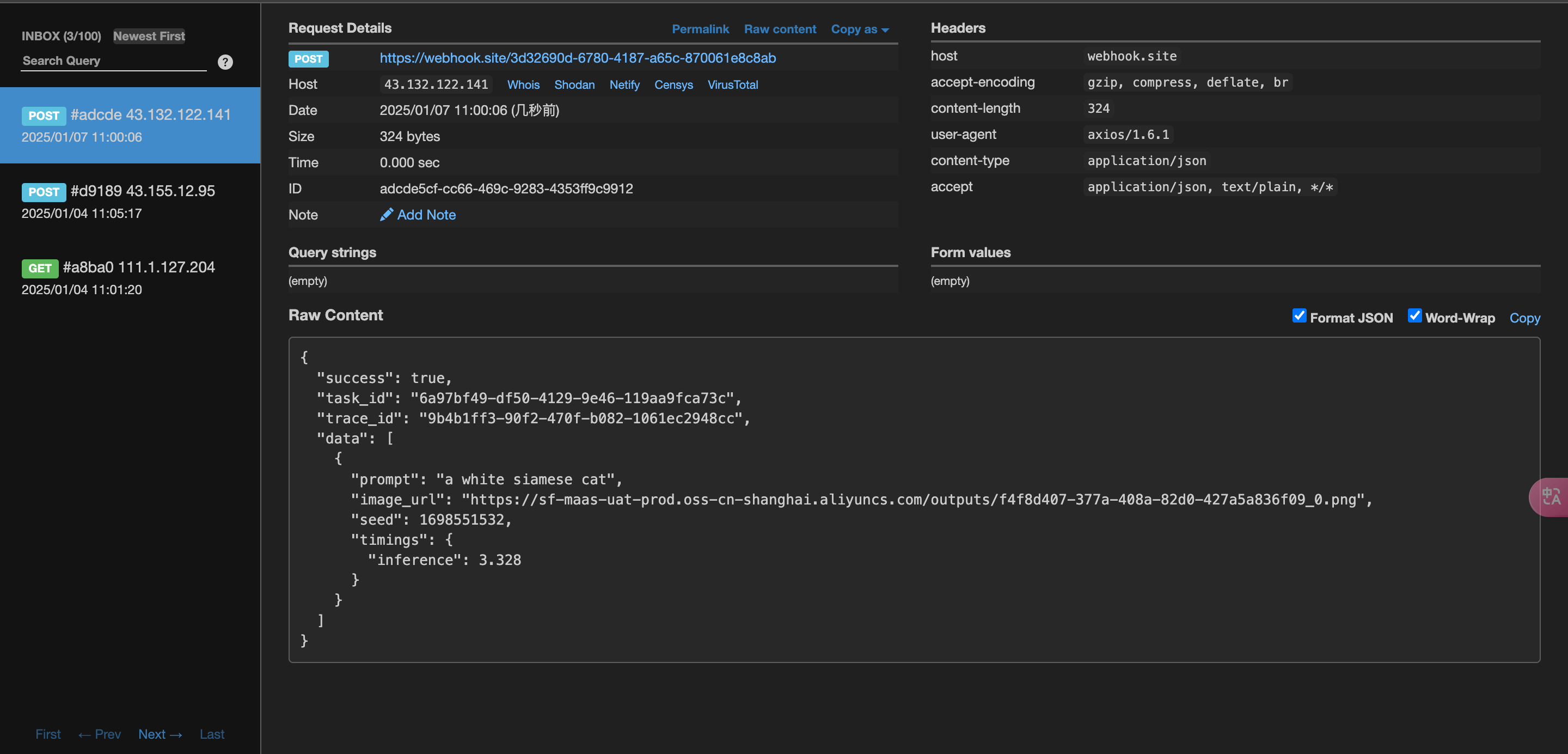
内容如下:
1 |
{ |
可以看到结果中有一个 task_id 字段,其他的字段都和上文类似,通过该字段即可实现任务的关联。
错误处理
在调用 API 时,如果遇到错误,API 会返回相应的错误代码和信息。例如:
400 token_mismatched:Bad request, possibly due to missing or invalid parameters.400 api_not_implemented:Bad request, possibly due to missing or invalid parameters.401 invalid_token:Unauthorized, invalid or missing authorization token.429 too_many_requests:Too many requests, you have exceeded the rate limit.500 api_error:Internal server error, something went wrong on the server.
错误响应示例
1 |
{ |
结论
通过本文档,您已经了解了如何使用 Flux Images Generation API 可通过输入提示词来生成图片。希望本文档能帮助您更好地对接和使用该 API。如有任何问题,请随时联系我们的技术支持团队。