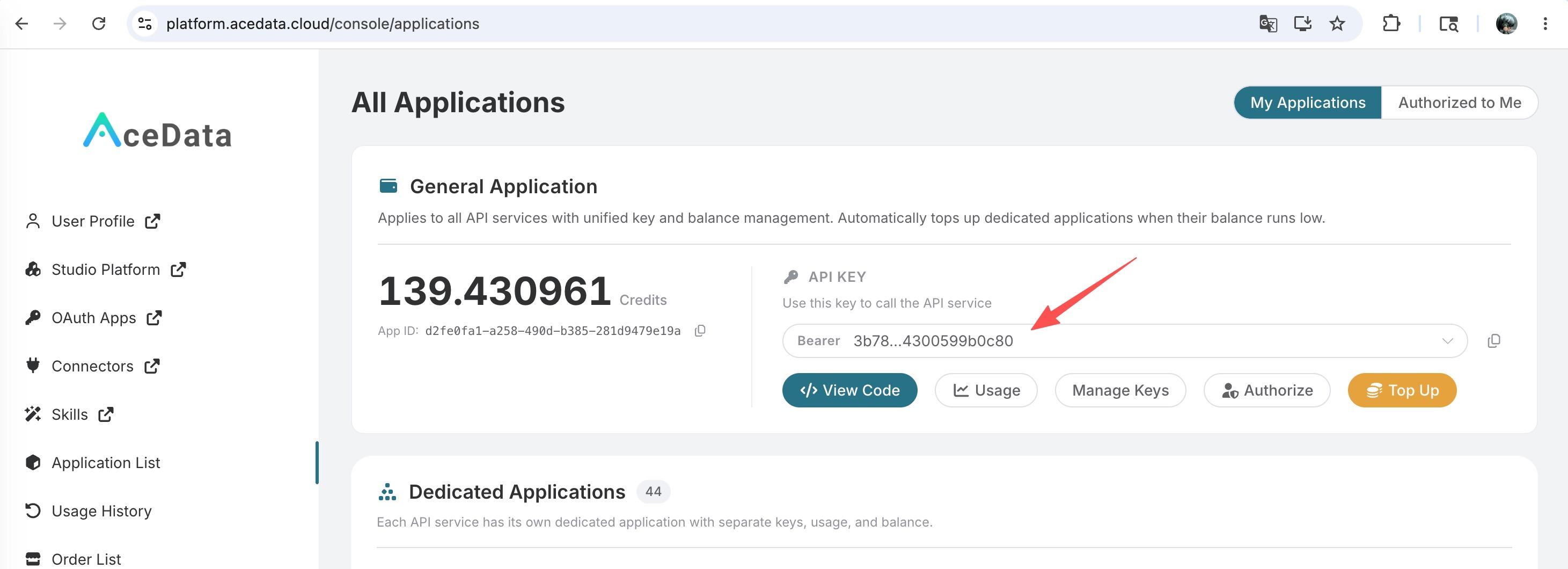
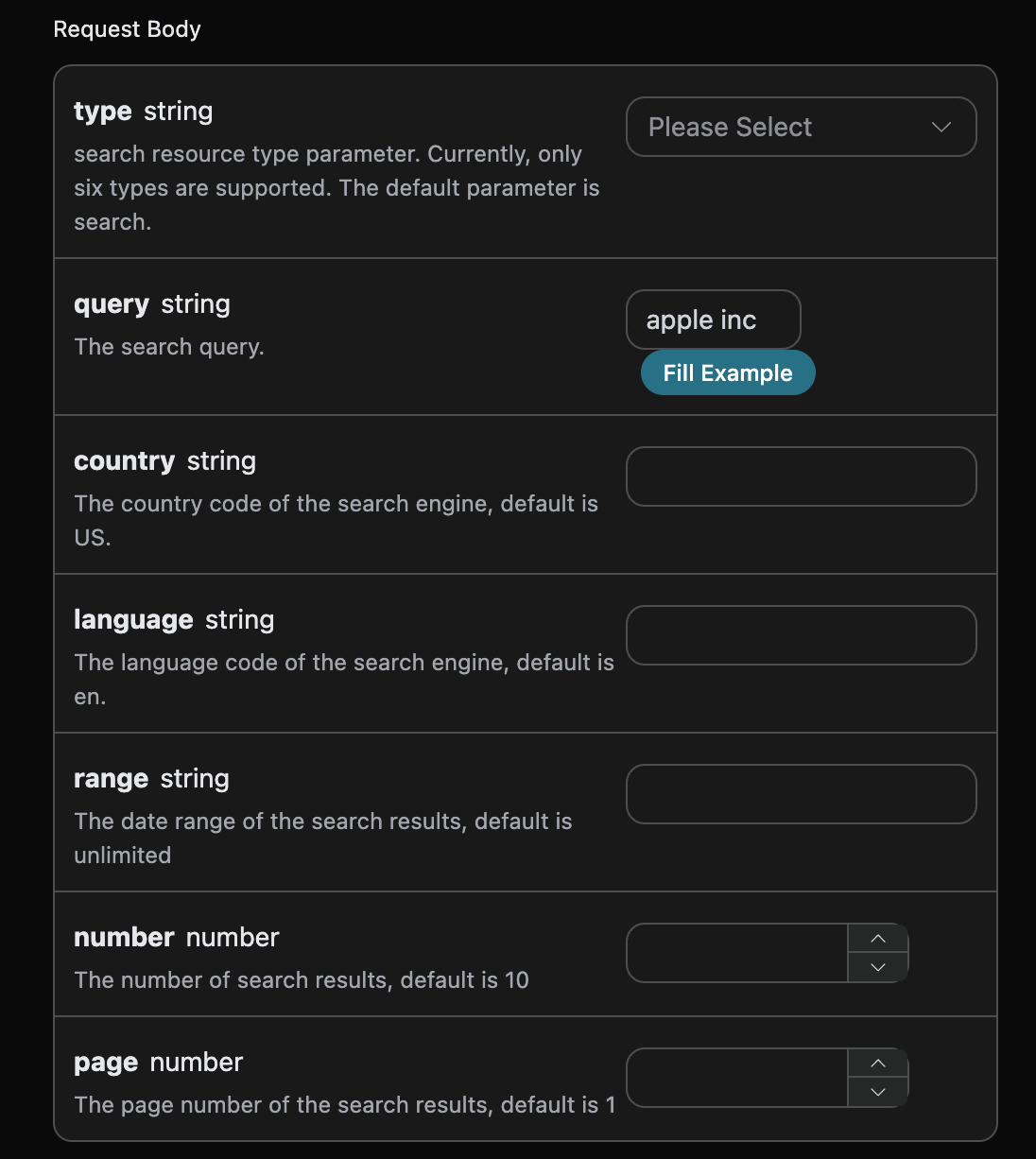
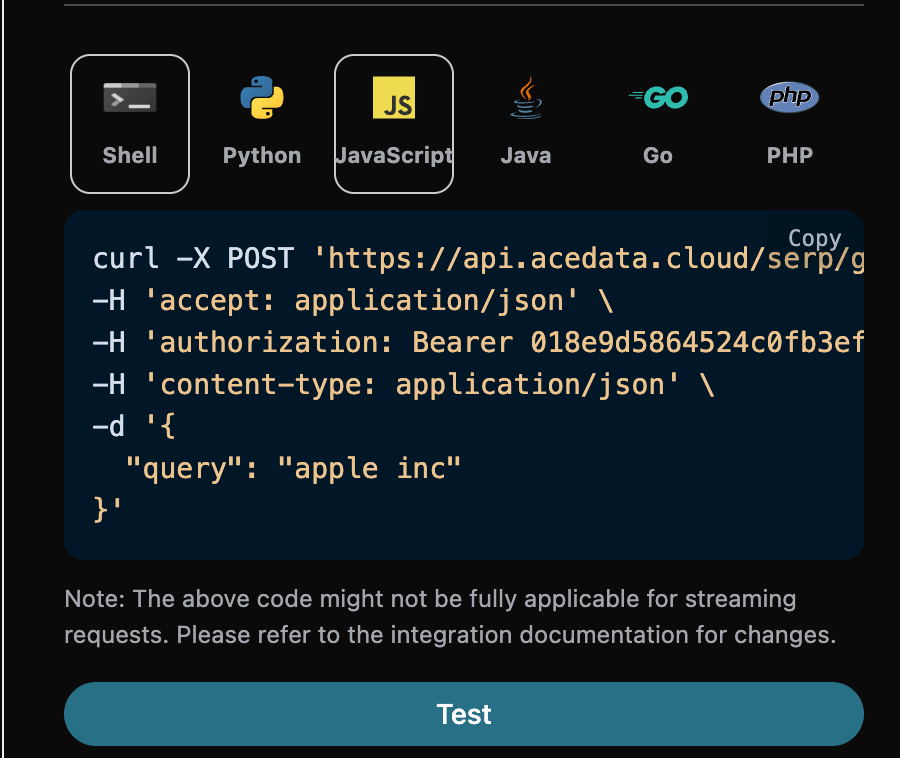
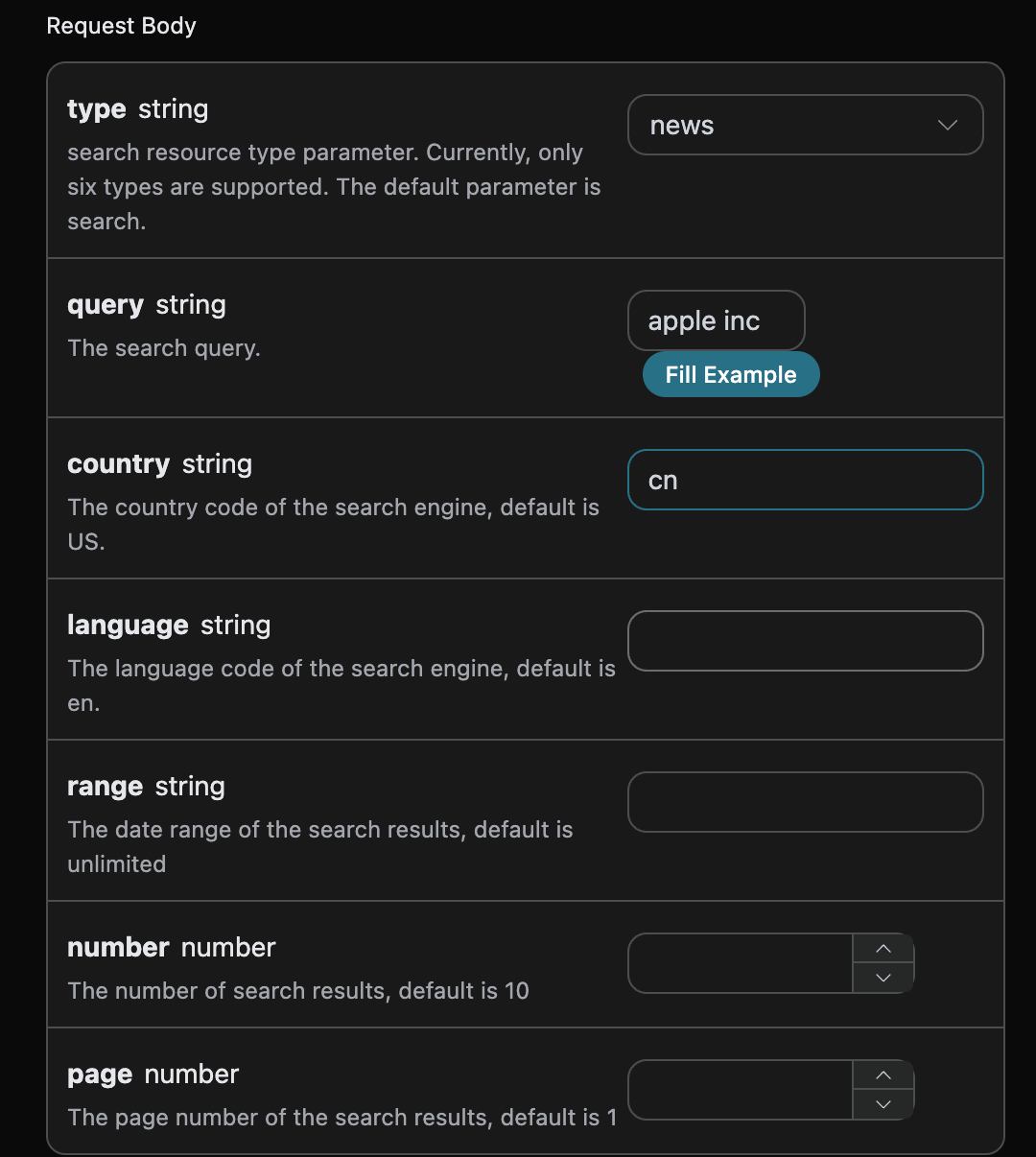
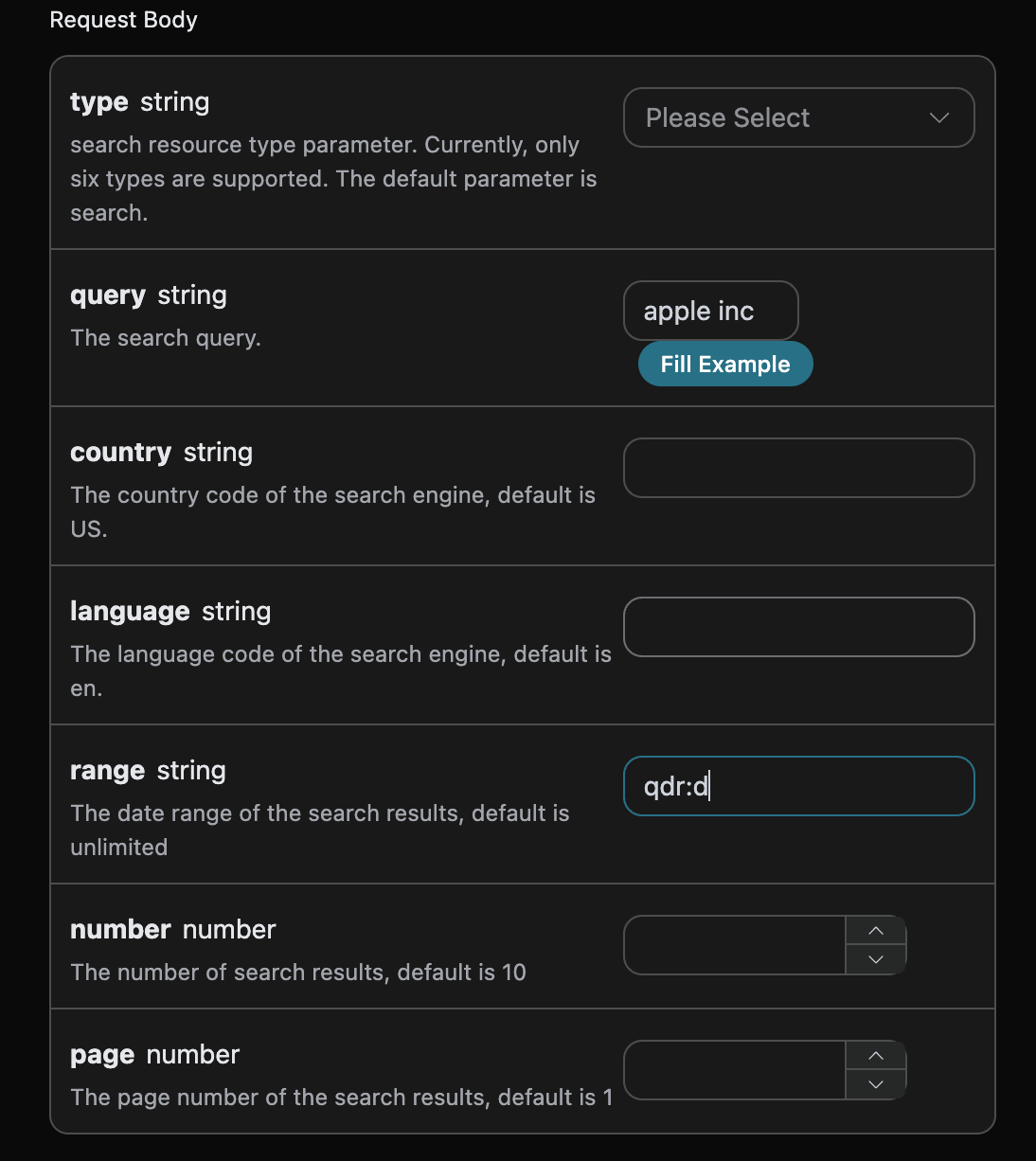
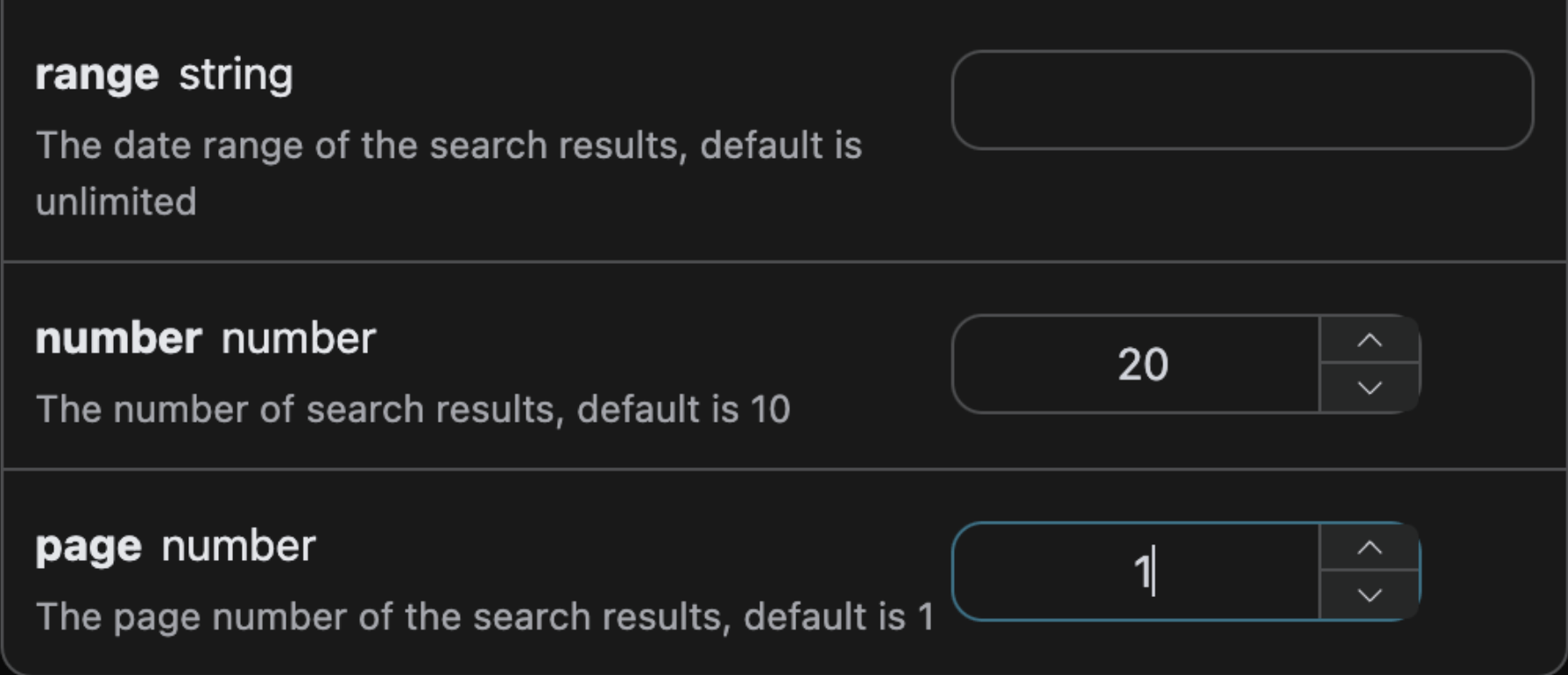
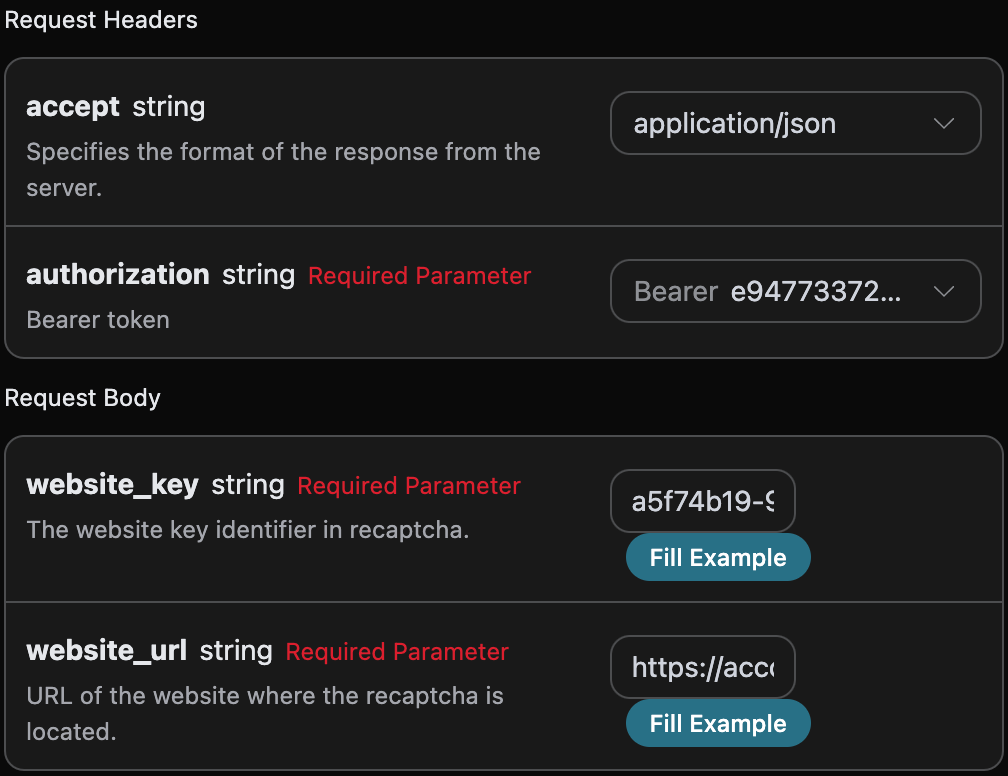
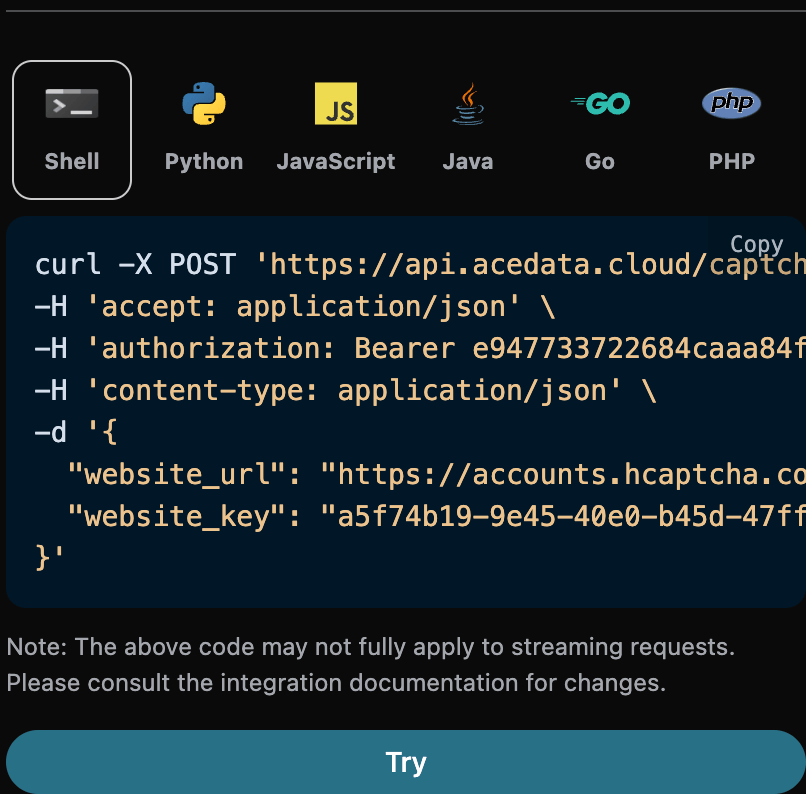
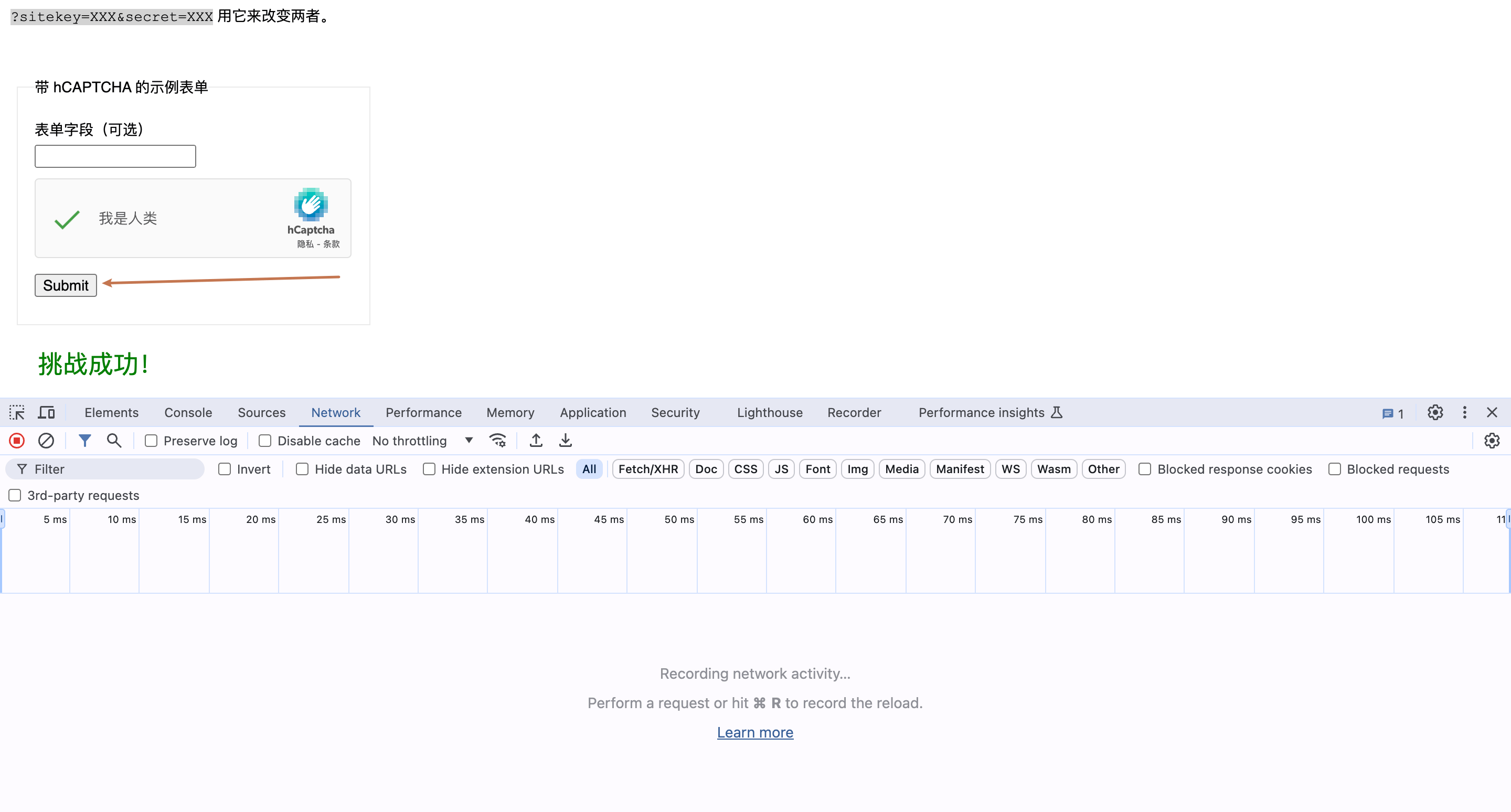
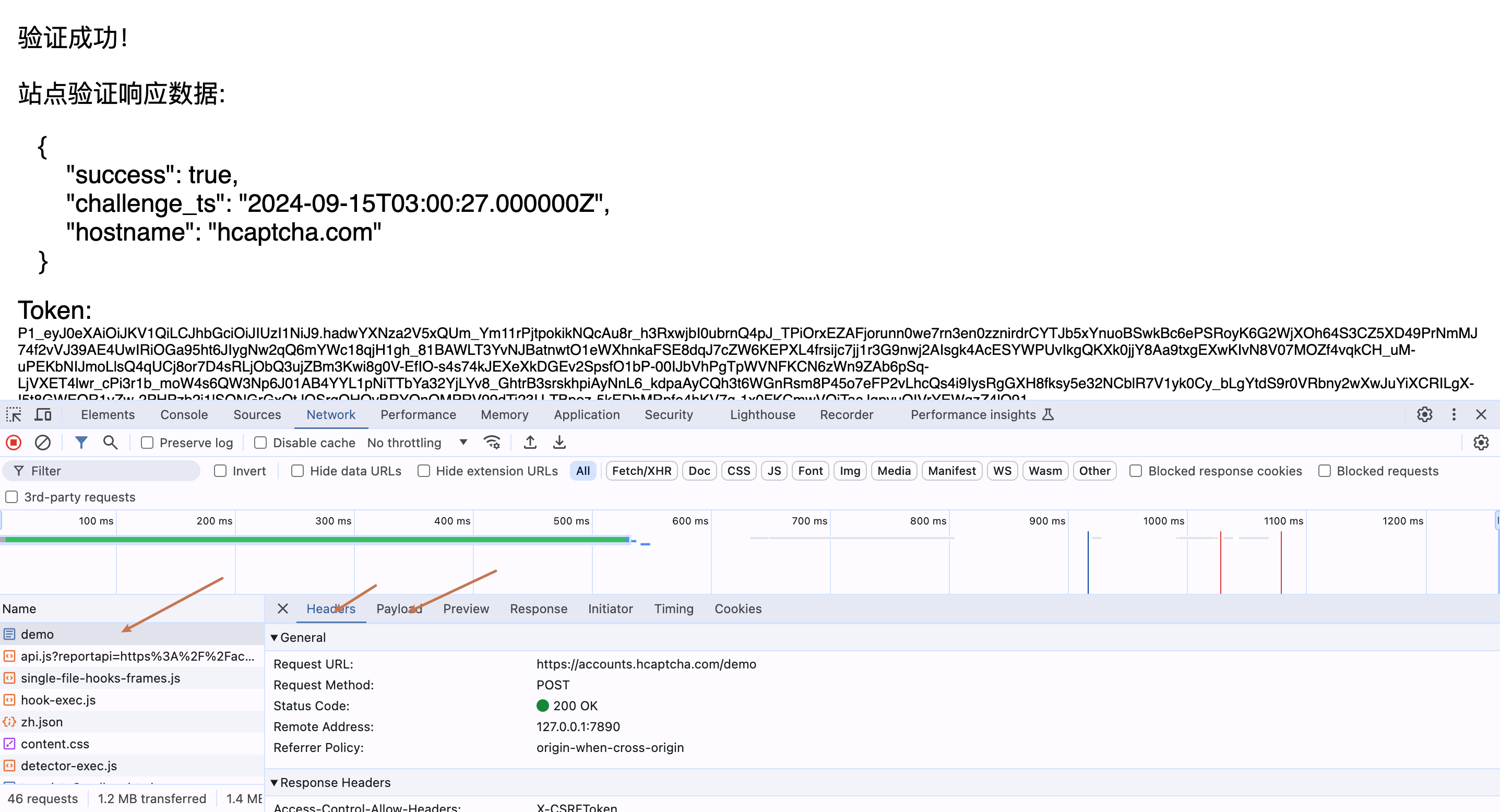
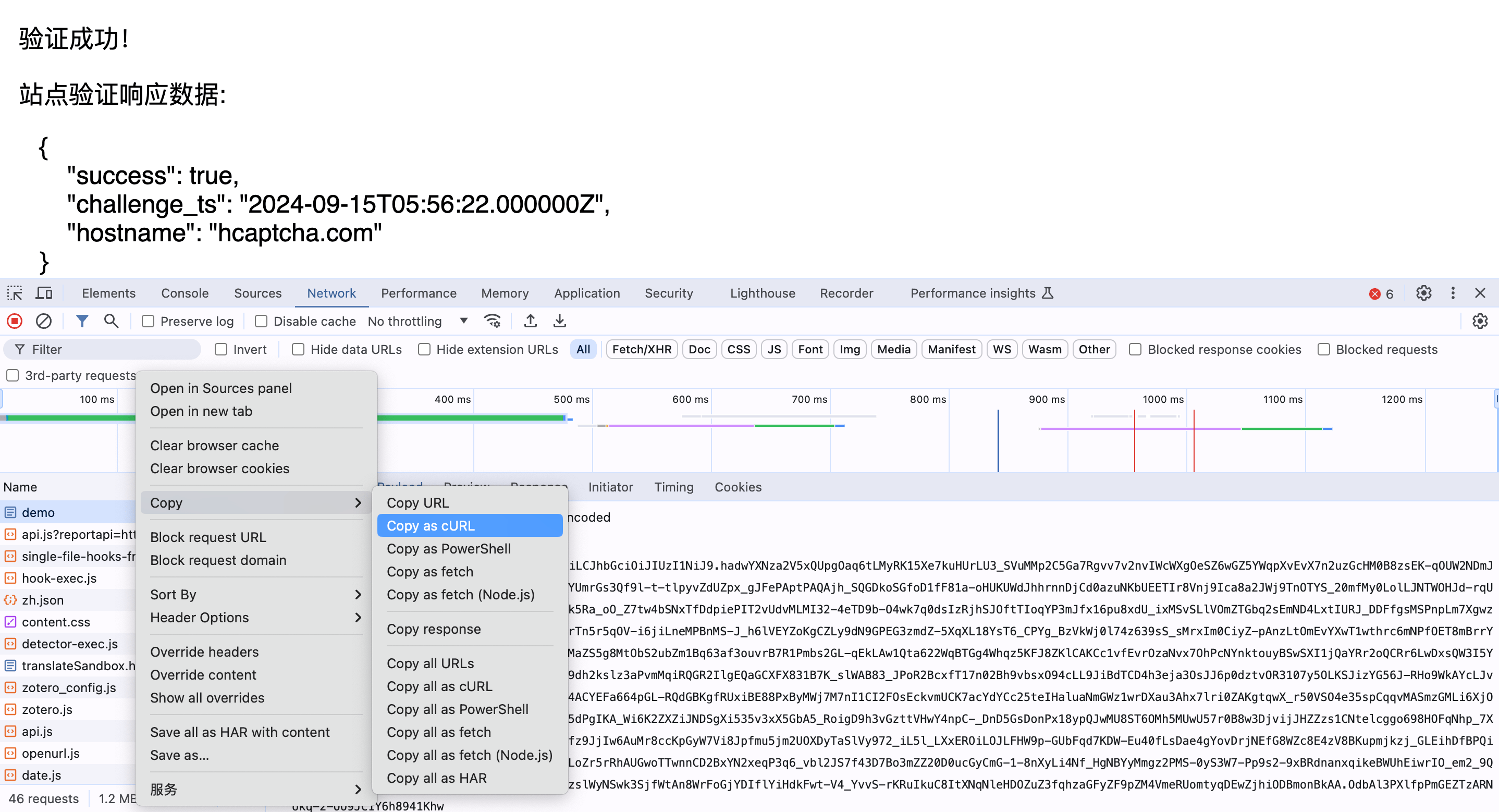
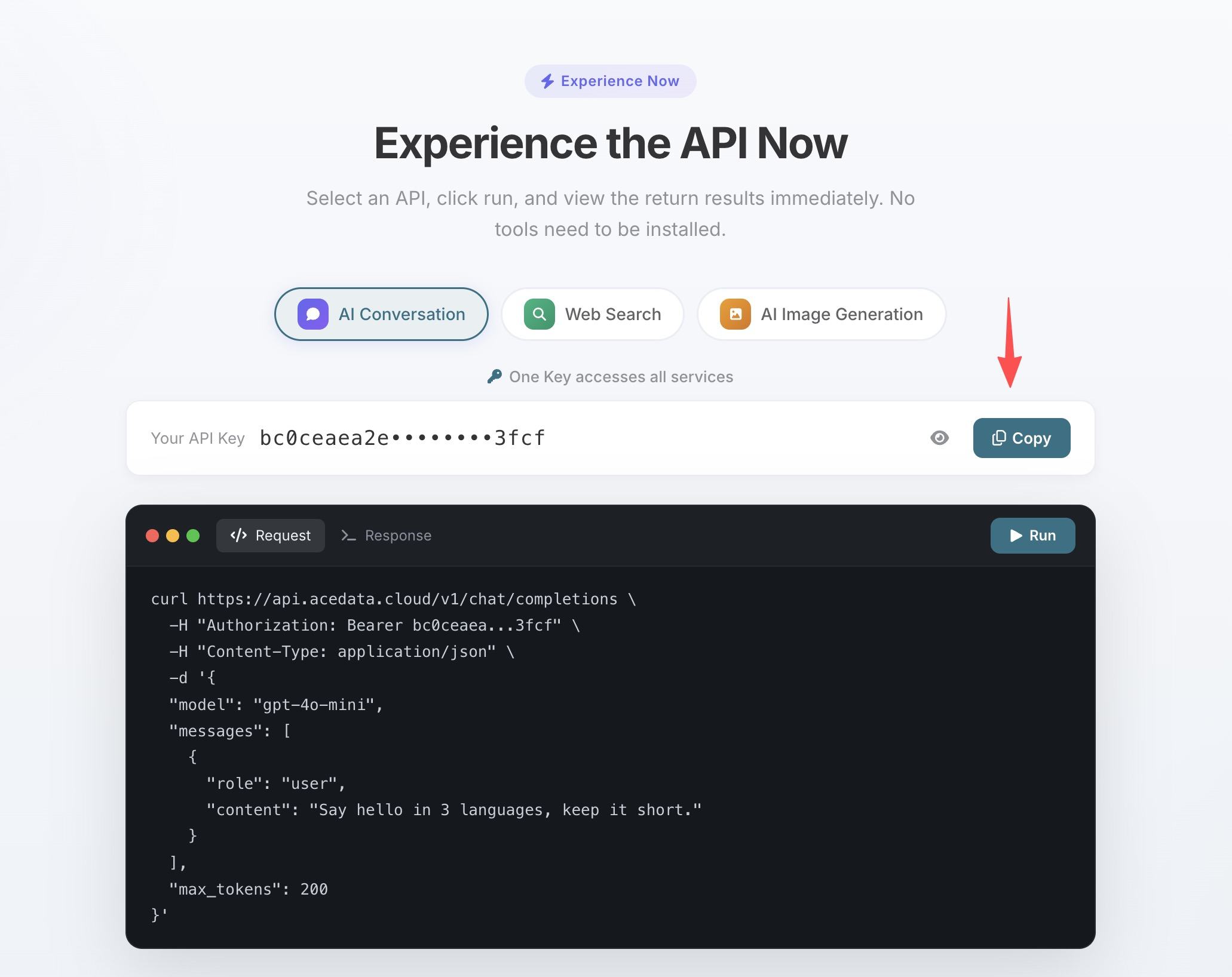
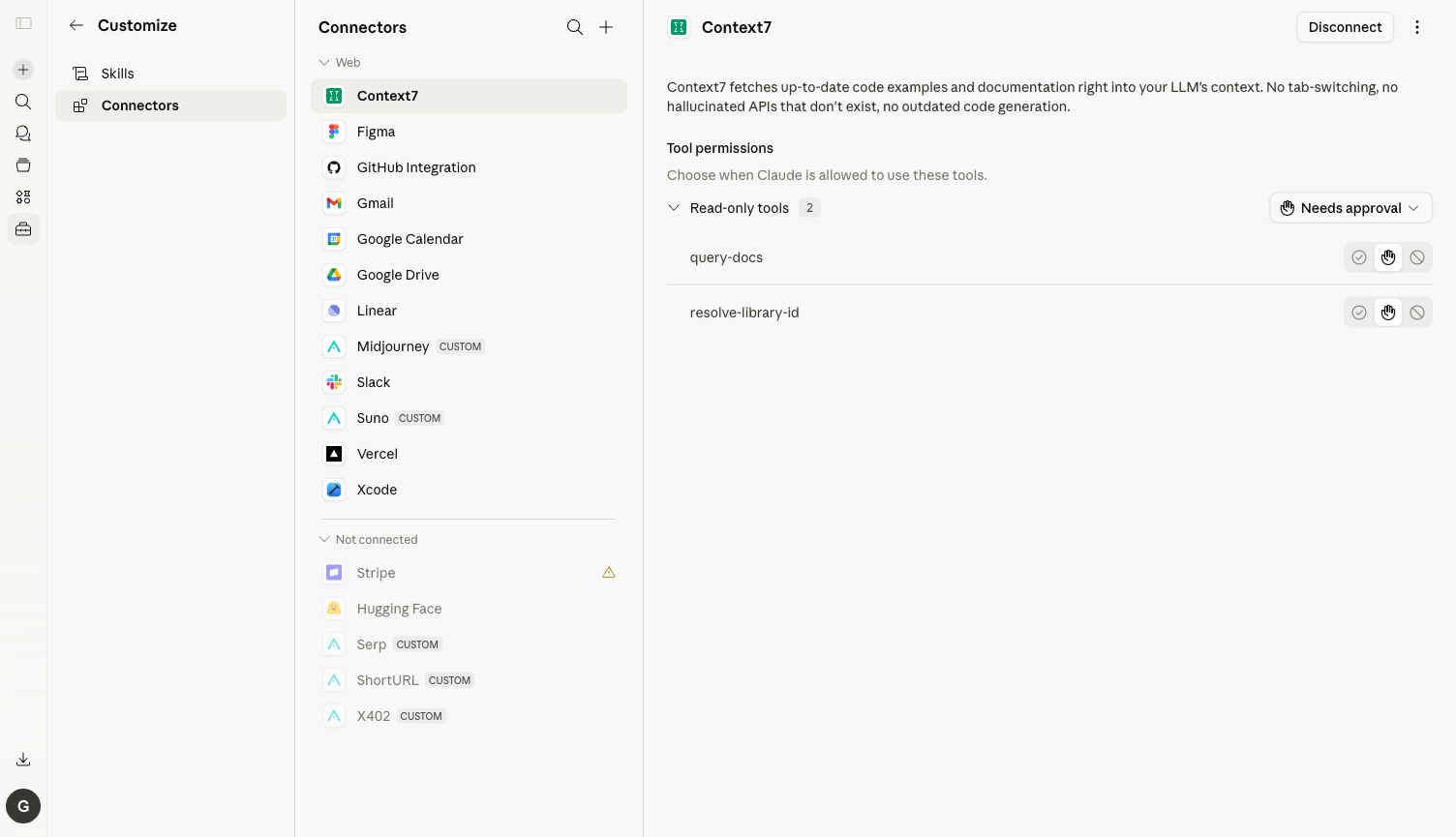
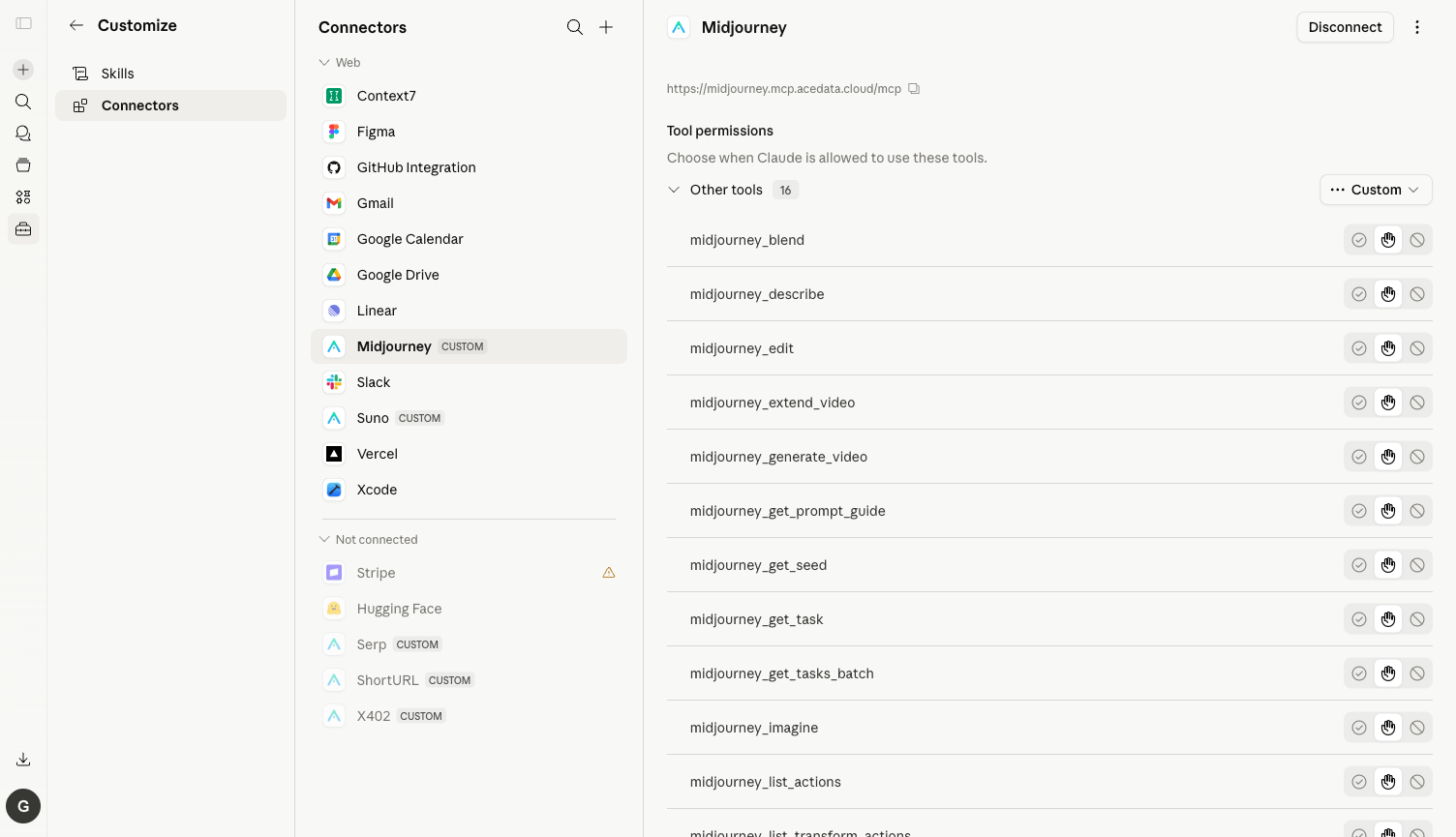
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
|
{
"knowledge_graph": {
"title": "Apple",
"type": "Technology company",
"image_url": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSHmAG45NsvdRfYlNghHFvinM0w2mqjd8A0lXKU2LA&usqp=CAE&s",
"attributes": {
"Customer service": "1 (800) 275-2273",
"Founders": "Steve Jobs, Steve Wozniak, Ronald Wayne",
"Founded": "April 1, 1976, Los Altos, CA",
"Stock price": "AAPL (NASDAQ) $198.42 +1.97 (+1.00%)Jun 16, 4:00 PM EDT - Disclaimer",
"Headquarters": "Cupertino, CA",
"CEO": "Tim Cook (Aug 24, 2011–)"
}
},
"organic": [
{
"title": "Apple",
"link": "https://www.apple.com/",
"snippet": "Discover the innovative world of Apple and shop everything iPhone, iPad, Apple Watch, Mac, and Apple TV, plus explore accessories, entertainment, ...",
"sitelinks": [
{
"title": "Support",
"link": "https://support.apple.com/",
"snippet": "iPhone Support - Contact - Billing and Subscriptions - Apple Repair"
},
{
"title": "Career Opportunities",
"link": "https://www.apple.com/careers/us/",
"snippet": "Work at Apple - Software and Services - Support and Service"
},
{
"title": "Business",
"link": "https://www.apple.com/business/",
"snippet": "Small Business - Enterprise - Shop for Business - Apple at Work - ..."
},
{
"title": "Store",
"link": "https://www.apple.com/store",
"snippet": "Shop iPhone - Shop Mac - Shop iPad - App Store - ..."
},
{
"title": "Investor Relations",
"link": "https://investor.apple.com/investor-relations/default.aspx",
"snippet": "SEC Filings - Stock Price - Leadership and Governance"
}
],
"position": 1
},
{
"title": "Apple Inc.",
"link": "https://en.wikipedia.org/wiki/Apple_Inc.",
"snippet": "Apple Inc. is an American multinational corporation and technology company headquartered in Cupertino, California, in Silicon Valley.",
"position": 2
},
{
"title": "Apple Inc. | History, Products, Headquarters, & Facts",
"link": "https://www.britannica.com/money/Apple-Inc",
"snippet": "Apple Inc. is an American multinational technology company that revolutionized the technology sector through its innovation of computer software, personal ...",
"date": "7 days ago",
"position": 3
},
{
"title": "Apple Inc. (AAPL) Company Profile & Facts",
"link": "https://finance.yahoo.com/quote/AAPL/profile/",
"snippet": "Apple Inc. designs, manufactures, and markets smartphones, personal computers, tablets, wearables, and accessories worldwide.",
"position": 4
},
{
"title": "AAPL: Apple Inc Stock Price Quote - NASDAQ GS",
"link": "https://www.bloomberg.com/quote/AAPL:US",
"snippet": "Apple Inc. designs, manufactures, and markets smartphones, personal computers, tablets, wearables and accessories, and sells a variety of related accessories.",
"position": 5
},
{
"title": "Apple Inc. (AAPL) Stock Price Today",
"link": "https://www.wsj.com/market-data/quotes/AAPL?gaa_at=eafs&gaa_n=ASWzDAgqDxGuyZUvNqcmVhmXBoGHd3y-StLOZpo82befc3s9jFqSwwJzjPmn&gaa_ts=68514b6e&gaa_sig=a-sNk_J7mCIayZx21oIaY6Ge6vifnmxy7A4psXod_wP6ng9689uAwZYvUOUQPv_dxcArYe_RQbKxCkwngcK_bQ%3D%3D",
"snippet": "Apple Inc. engages in the design, manufacture, and sale of smartphones, personal computers, tablets, wearables and accessories, and other varieties of related ...",
"position": 6
},
{
"title": "Apple",
"link": "https://www.linkedin.com/company/apple",
"snippet": "External link for Apple. Industry: Computers and Electronics Manufacturing. Company size: 10,001+ employees. Headquarters: Cupertino, California. Type: Public ...",
"position": 7
},
{
"title": "Apple | AAPL Stock Price, Company Overview & News",
"link": "https://www.forbes.com/companies/apple/",
"snippet": "Apple Inc. engages in the design, manufacture, and sale of smartphones, personal computers, tablets, wearables and accessories, and other variety of related ...",
"position": 8
},
{
"title": "Apple Inc. (AAPL) Stock Price, News, Quote & History",
"link": "https://finance.yahoo.com/quote/AAPL/",
"snippet": "Find the latest Apple Inc. (AAPL) stock quote, history, news and other vital information to help you with your stock trading and investing.",
"position": 9
},
{
"title": "iCloud",
"link": "https://www.icloud.com/",
"snippet": "At iCloud.com, you can access your photos, files, and more from any web browser. Changes you make will sync to your iPhone and other devices.",
"position": 10
},
{
"title": "Apple Inc (AAPL) Stock Price & News - Google Finance",
"link": "https://www.google.com/finance/quote/AAPL:NASDAQ?hl=en",
"snippet": "Apple Inc. is an American multinational corporation and technology company headquartered in Cupertino, California, in Silicon Valley.",
"position": 11
},
{
"title": "Apple Inc Company Profile - GlobalData",
"link": "https://www.globaldata.com/company-profile/apple-inc/",
"snippet": "Apple Inc (Apple) designs, manufactures, and markets smartphones, tablets, personal computers, and wearable devices. The company offers software applications ...",
"position": 12
},
{
"title": "The Founding of Apple Computer, Inc. - This Month in ...",
"link": "https://guides.loc.gov/this-month-in-business-history/april/apple-computer-founded",
"snippet": "Apple Computer, Inc. was founded on April 1, 1976, by college dropouts Steve Jobs and Steve Wozniak, who brought to the new company a vision of changing the ...",
"position": 13
},
{
"title": "Apple Inc",
"link": "https://vimeo.com/appleinc",
"snippet": "Apple Inc is a member of Vimeo, the home for high quality videos and the people who love them.",
"position": 14
}
],
"people_also_ask": [
{
"question": "What is the Apple Inc?"
},
{
"question": "Who owns Apple Inc?"
},
{
"question": "What is Apple Inc. best known for?",
"title": "Apple Inc. - Wikipedia",
"snippet": "It is best known for its consumer electronics, software, and services. Founded in 1976 as Apple Computer Company by Steve Jobs, Steve Wozniak and Ronald Wayne, the company was incorporated by Jobs and Wozniak as Apple Computer, Inc. the following year.",
"link": "https://en.wikipedia.org/wiki/Apple_Inc.#:~:text=It%20is%20best%20known%20for,%2C%20Inc.%20the%20following%20year."
},
{
"question": "What is the meaning of Inc in Apple Inc?",
"title": "Inc. | English meaning - Cambridge Dictionary",
"snippet": "abbreviation for incorporated: used in the names of US companies that are legally established: Bishop Computer Services, Inc.",
"link": "https://dictionary.cambridge.org/dictionary/english/inc#:~:text=abbreviation%20for%20incorporated%3A%20used%20in,Bishop%20Computer%20Services%2C%20Inc."
}
],
"related_searches": [
{
"query": "apple inc คืออะไร"
},
{
"query": "Apple Inc full form"
},
{
"query": "Apple Inc address"
},
{
"query": "Apple Inc investor relations"
},
{
"query": "Apple Inc industry"
},
{
"query": "Apple Inc Annual Report"
},
{
"query": "Apple Inc careers"
},
{
"query": "Apple 17 pro"
}
]
}
|
上市了!")