一、先试着英汉翻译一波:
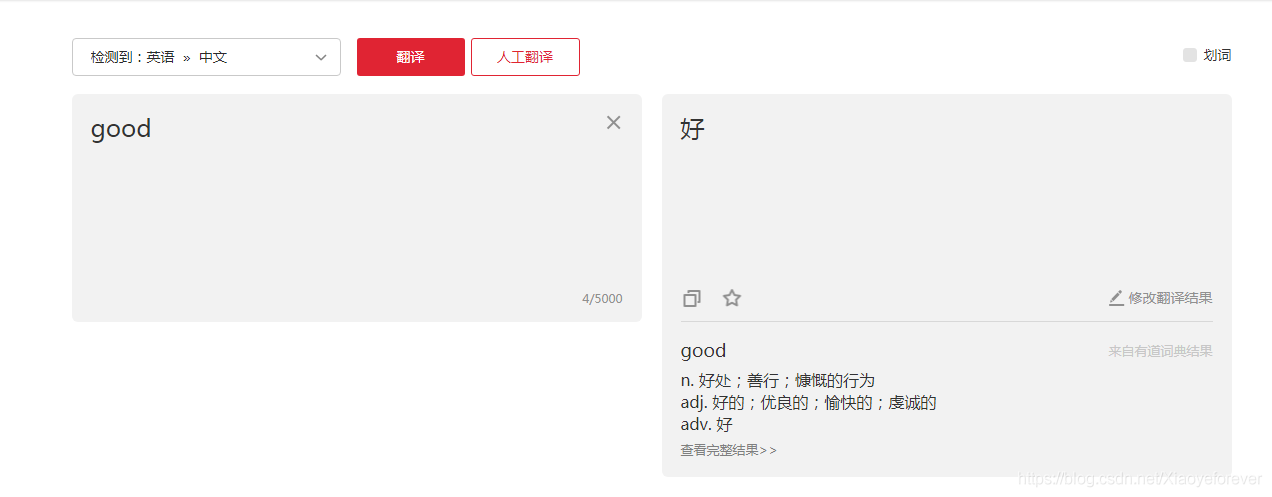
1.按F12打开调试台,再点击Network,再点击Headers,可以找到i=good,这就是我们刚才输入需要翻译的词语good,from Data中的就是请求的参数,分别为:
i: good from: AUTO to: AUTO smartresult: dict client: fanyideskweb salt: 15972332870677 sign: 3a078c10344e67f95822ae9389e1363f lts: 1597233287067 bv: 85c050fb1c0b4d824d801d079db7371a doctype: json version: 2.1 keyfrom: fanyi.web action: FY_BY_CLICKBUTTION
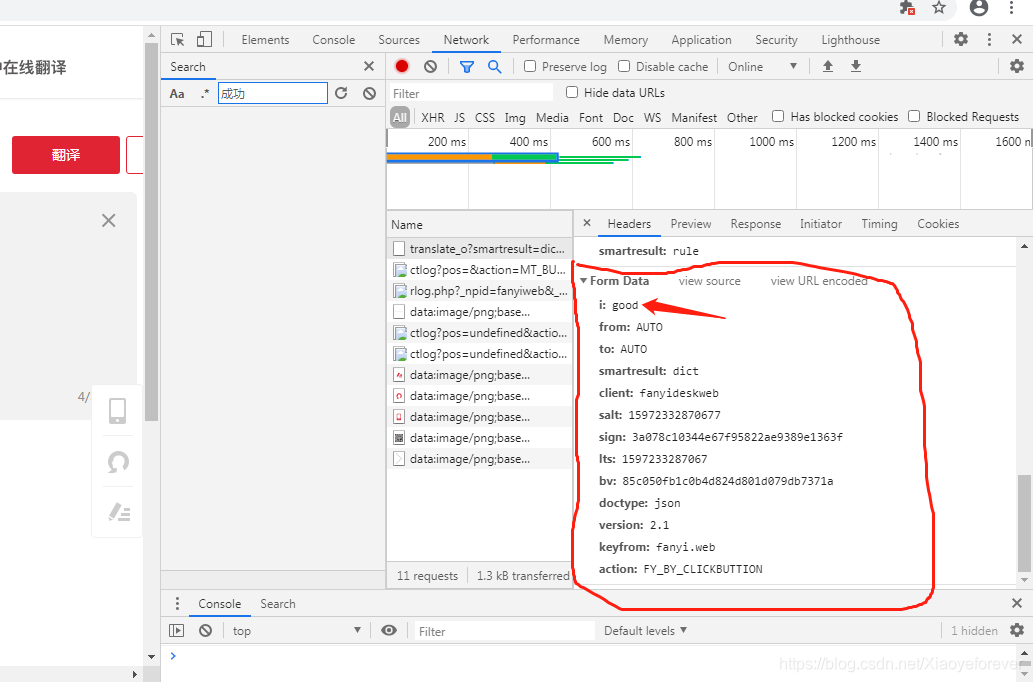
2.在来翻译一个新的词语,看下这些参数有无变化
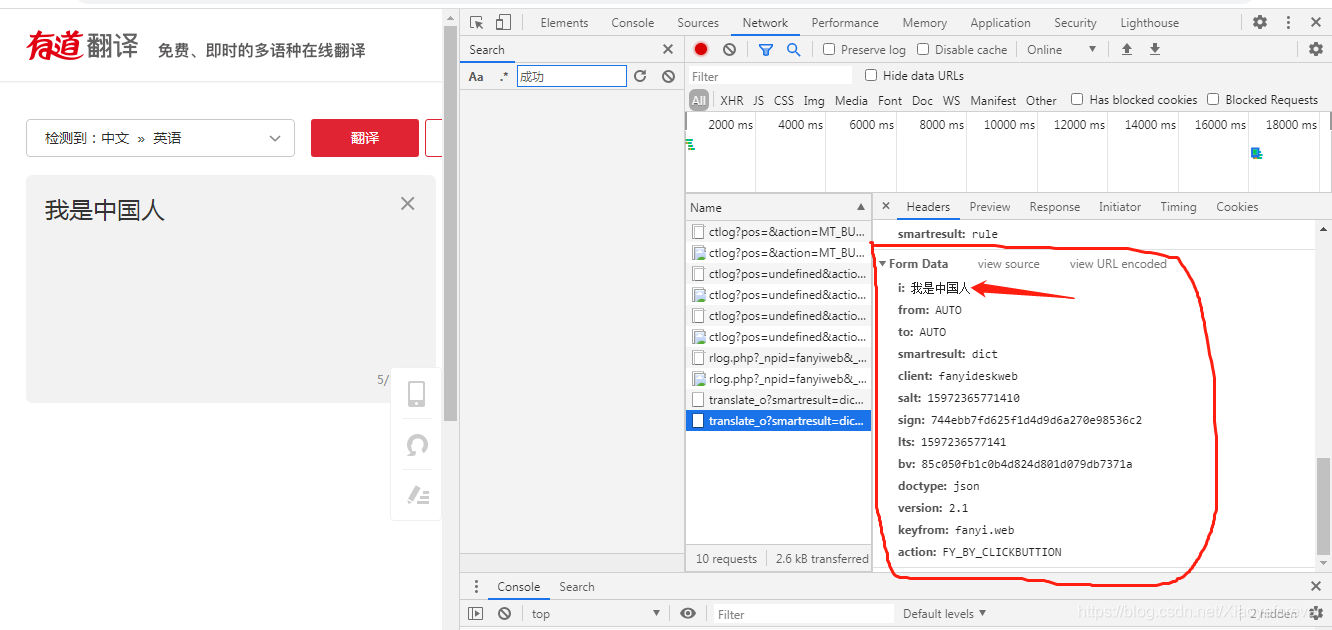 i: 我是中国人 from: AUTO to: AUTO smartresult: dict client: fanyideskweb salt: 15972365771410 sign: 744ebb7fd625f1d4d9d6a270e98536c2 lts: 1597236577141 bv: 85c050fb1c0b4d824d801d079db7371a doctype: json version: 2.1 keyfrom: fanyi.web action: FY_BY_CLICKBUTTION
i: 我是中国人 from: AUTO to: AUTO smartresult: dict client: fanyideskweb salt: 15972365771410 sign: 744ebb7fd625f1d4d9d6a270e98536c2 lts: 1597236577141 bv: 85c050fb1c0b4d824d801d079db7371a doctype: json version: 2.1 keyfrom: fanyi.web action: FY_BY_CLICKBUTTION
发现有5个参数是变化的(实际是4 个),分别为:
i: salt: sign: lts: bv:
3.看看URL,#http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule() 请求连接:http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule 去掉translate_o中的_o,不去的话,轻轻就数据结果:某道词典 ,英语翻译汉语正常,汉语翻译英语时,出现{‘errorCode’: 50} ,post请求方式
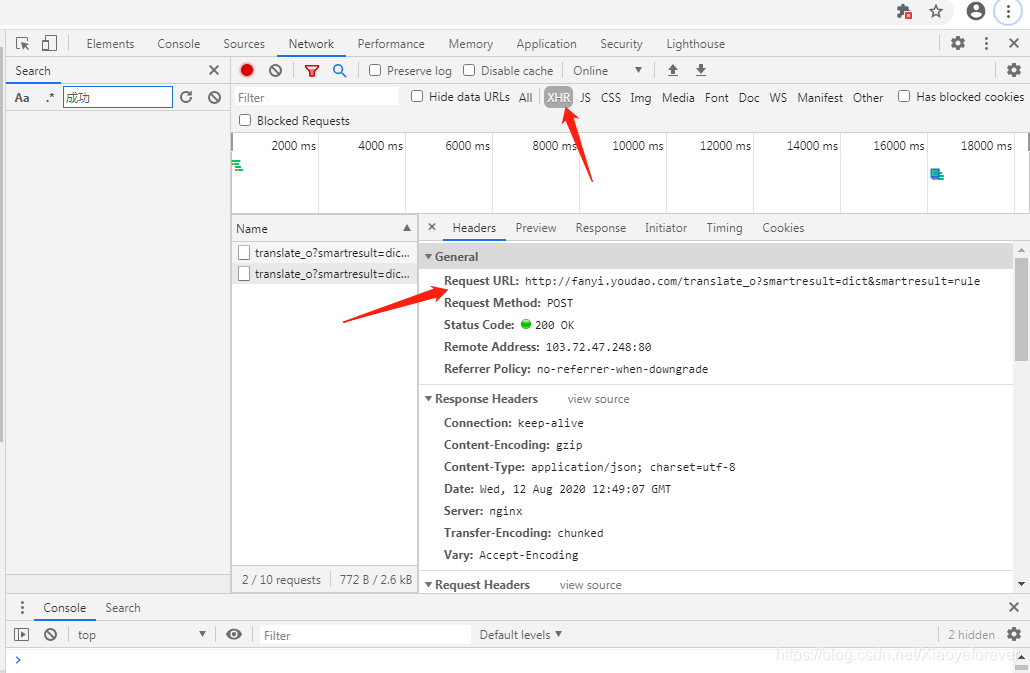
4.点击Initiator,可以看到所有的js文件都是@fanyi.min.js:1
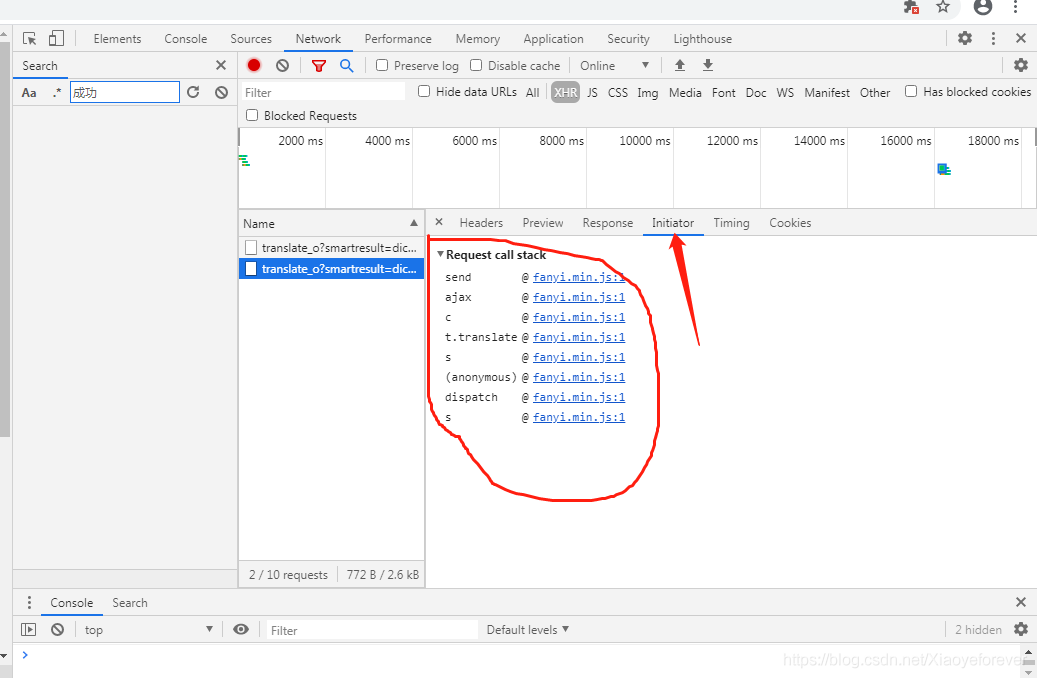
5、点击@fanyi.min.js:1进入,
点击中间的{ },格式化一下。
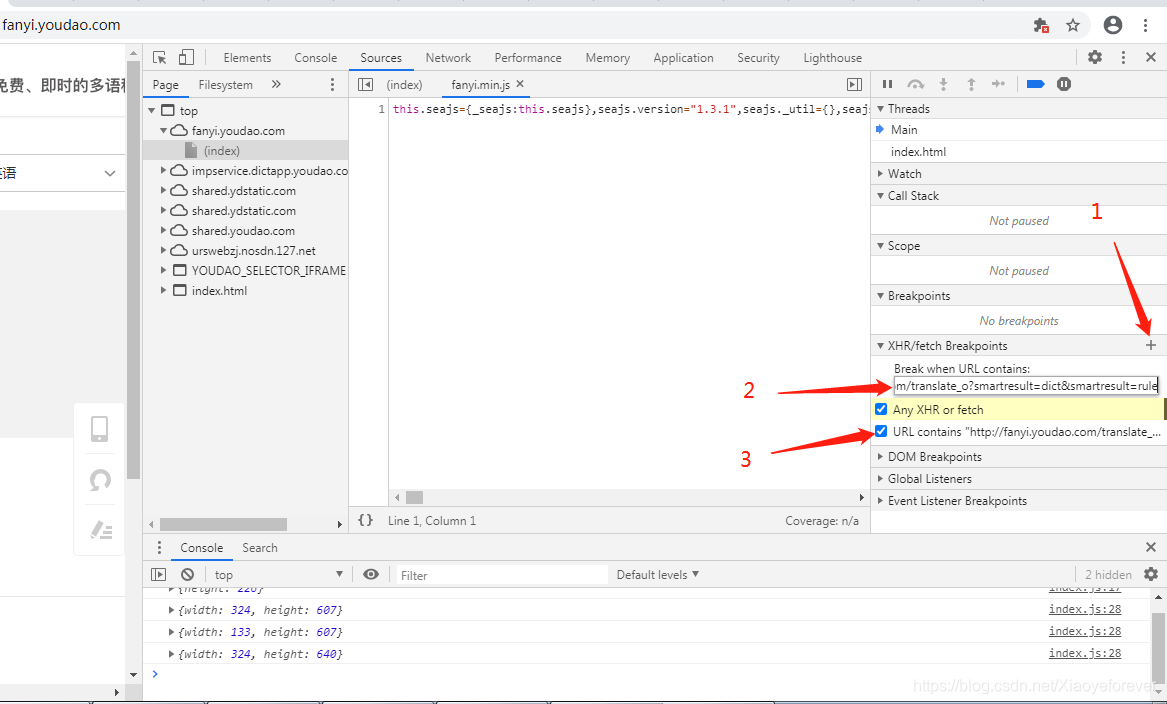
再找到XHR/fetch Breakpoints,添加断点, 你可以针对某一个请求或者请求的关键字设置断点:
再点一下‘+’输入url即可url为http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule
最后再去点击一下翻译按钮
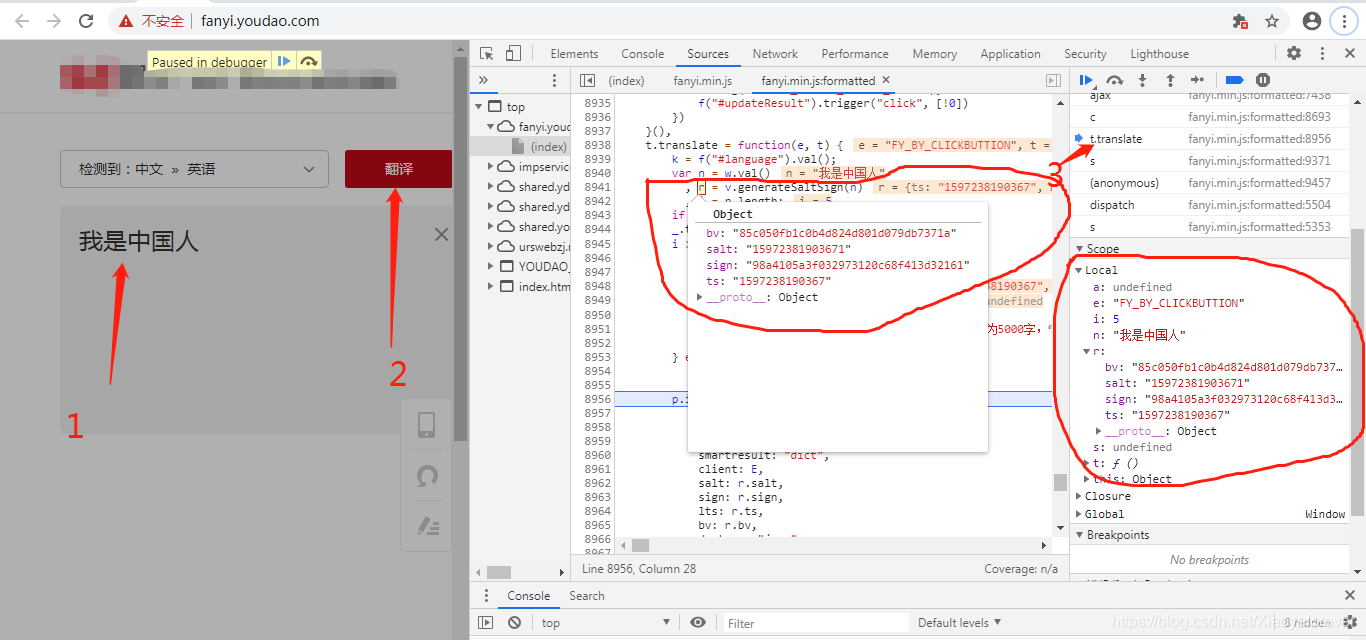
6.翻译:我是中国人,点击t-translate,再点击Scope,再点击Local,再点击r,即可看到我们需要的参数,在吧鼠标放到中间的r上,r = v.generateSaltSign(n),就会弹出Object框。就是我们需要的参数。
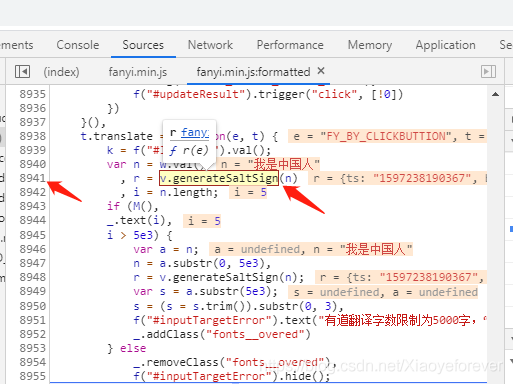
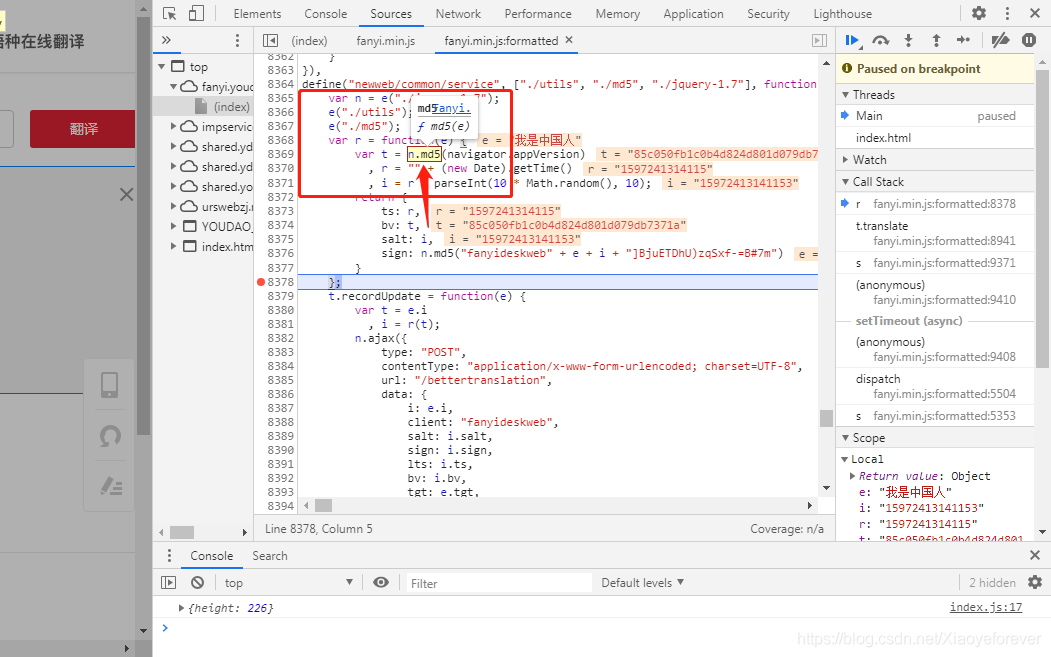
7.可以看到8941行,鼠标放到v.gen erateSaltSign(n)上,会弹出f r(e)函数,点击这个函数会进入第8368行,可以看到我们需要的参数
salt: sign: lts: bv:
在8378行打上断点,再次点击翻译按钮,即可看多所有的参数值显示出来。

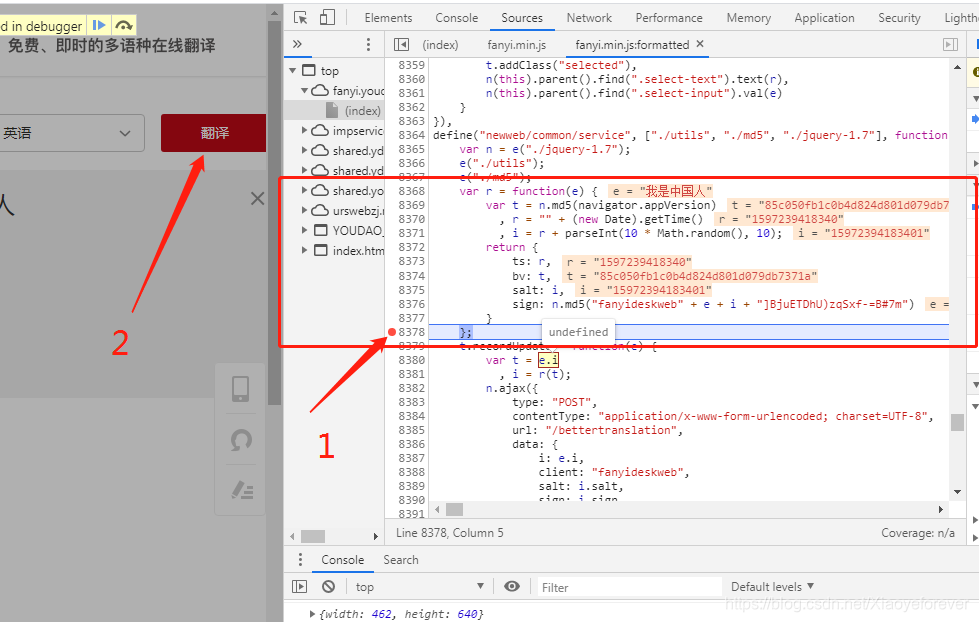
8.对于第一个 ts: r,相当于pythonzhong 的ts=r赋值, 可以看到r = “” + (new Date).getTime(),知道了r,就知道了ts,r是js中 new Date().getTime()得到的是毫秒数,也就是时间戳,单位为毫秒,13位数字的字符串。
即可用python中的时间戳构造:
13位时间戳获取方法:单位:毫秒 t1 = time.time() ts= int(t1 * 1000) ts=r
第二个参数:salt: i,相当于python中的salt= i赋值,i = r + parseInt(10 * Math.random(), 10),意思是随机产生一个整数 范围是0-9里面的一个随机数
ts=r,转化为字符转,parseInt(10 * Math.random(), 10)产生的随机数也转化为字符串,最后进行字符串拼接,而不是数字相加。请注意一下。跟实际的赋值对比,产生了一个14位数字的字符串,跟实际情况一样。
即可用python中的构造法: salt= str(int(ts))+str(random.randint(0,10)) print(salt)
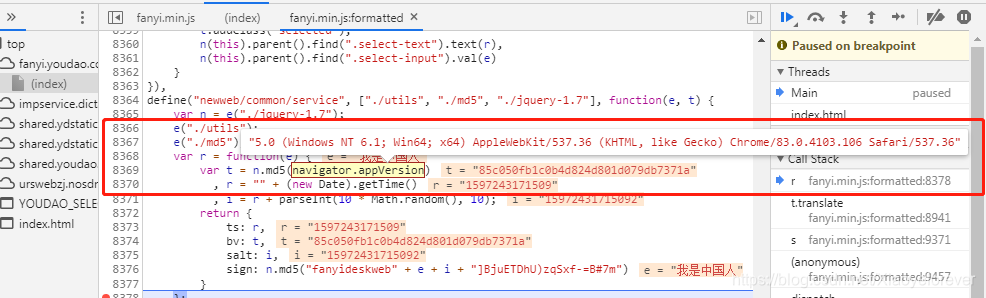
第三个参数:bv: t,相当于python中的bv=t赋值, var t = n.md5(navigator.appVersion),navigator.appVersion的值竟然是一个 User-Agent,那么重点来了,网上教程都是md5加密相关都是直接用python原生来生成,而我就选择直接扣代码。用python3调用js的库之execjs 来扣,鼠标放到var t = n.md5(navigator.appVersion)中的n.md5()上,将会出现f md5(e)函数,点击进入,来到8196行, md5: function(e){ },把第8196行到8278行扣下来,再应用execjs解析出bv
注意:自调函数调用写法:
var aa=function(e){ }和function aa(e){ }写法都可以,一样的
import execjs f = open(r”text.js”,encoding=’utf-8’).read() ctx1 = execjs.compile(f) bv=ctx1.call(‘md5_1’,ua.random) print(bv)
扣出来的js代码:主体为function md51(e) { } ,应用execjs解析,缺什么参数找什么参数,即可_
var n = function(e, t) { return e << t | e >>> 32 - t } , r = function(e, t) { var n, r, i, a, o; return i = 2147483648 & e, a = 2147483648 & t, n = 1073741824 & e, r = 1073741824 & t, o = (1073741823 & e) + (1073741823 & t), n & r ? 2147483648 ^ o ^ i ^ a : n | r ? 1073741824 & o ? 3221225472 ^ o ^ i ^ a : 1073741824 ^ o ^ i ^ a : o ^ i ^ a } , i = function(e, t, n) { return e & t | ~e & n } , a = function(e, t, n) { return e & n | t & ~n } , o = function(e, t, n) { return e ^ t ^ n } , s = function(e, t, n) { return t ^ (e | ~n) } , l = function(e, t, a, o, s, l, c) { return e = r(e, r(r(i(t, a, o), s), c)), r(n(e, l), t) } , c = function(e, t, i, o, s, l, c) { return e = r(e, r(r(a(t, i, o), s), c)), r(n(e, l), t) } , u = function(e, t, i, a, s, l, c) { return e = r(e, r(r(o(t, i, a), s), c)), r(n(e, l), t) } , d = function(e, t, i, a, o, l, c) { return e = r(e, r(r(s(t, i, a), o), c)), r(n(e, l), t) } , f = function(e) { for (var t, n = e.length, r = n + 8, i = 16 * ((r - r % 64) / 64 + 1), a = Array(i - 1), o = 0, s = 0; s < n; ) o = s % 4 * 8, a[t = (s - s % 4) / 4] = a[t] | e.charCodeAt(s) << o, s++; return t = (s - s % 4) / 4, o = s % 4 * 8, a[t] = a[t] | 128 << o, a[i - 2] = n << 3, a[i - 1] = n >>> 29, a } , p = function(e) { var t, n = "", r = ""; for (t = 0; t <= 3; t++) n += (r = "0" + (e >>> 8 * t & 255).toString(16)).substr(r.length - 2, 2); return n }, h = function(e) { e = e.replace(/\\x0d\\x0a/g, "\\n"); for (var t = "", n = 0; n < e.length; n++) { var r = e.charCodeAt(n); if (r < 128) t += String.fromCharCode(r); else if (r > 127 && r < 2048) t += String.fromCharCode(r >> 6 | 192), t += String.fromCharCode(63 & r | 128); else if (r >= 55296 && r <= 56319) { if (n + 1 < e.length) { var i = e.charCodeAt(n + 1); if (i >= 56320 && i <= 57343) { var a = 1024 * (r - 55296) + (i - 56320) + 65536; t += String.fromCharCode(240 | a >> 18 & 7), t += String.fromCharCode(128 | a >> 12 & 63), t += String.fromCharCode(128 | a >> 6 & 63), t += String.fromCharCode(128 | 63 & a), n++ } } } else t += String.fromCharCode(r >> 12 | 224), t += String.fromCharCode(r >> 6 & 63 | 128), t += String.fromCharCode(63 & r | 128) } return t }; f = function(e) { for (var t, n = e.length, r = n + 8, i = 16 * ((r - r % 64) / 64 + 1), a = Array(i - 1), o = 0, s = 0; s < n; ) o = s % 4 * 8, a[t = (s - s % 4) / 4] = a[t] | e.charCodeAt(s) << o, s++; return t = (s - s % 4) / 4, o = s % 4 * 8, a[t] = a[t] | 128 << o, a[i - 2] = n << 3, a[i - 1] = n >>> 29, a } function md5_1(e) { var t, n, i, a, o, s, m, g, v, y = Array(); for (e = e, y = f, s = 1732584193, m = 4023233417, g = 2562383102, v = 271733878, t = 0; t < y.length; t += 16) n = s, i = m, a = g, o = v, s = l(s, m, g, v, y[t + 0], 7, 3614090360), v = l(v, s, m, g, y[t + 1], 12, 3905402710), g = l(g, v, s, m, y[t + 2], 17, 606105819), m = l(m, g, v, s, y[t + 3], 22, 3250441966), s = l(s, m, g, v, y[t + 4], 7, 4118548399), v = l(v, s, m, g, y[t + 5], 12, 1200080426), g = l(g, v, s, m, y[t + 6], 17, 2821735955), m = l(m, g, v, s, y[t + 7], 22, 4249261313), s = l(s, m, g, v, y[t + 8], 7, 1770035416), v = l(v, s, m, g, y[t + 9], 12, 2336552879), g = l(g, v, s, m, y[t + 10], 17, 4294925233), m = l(m, g, v, s, y[t + 11], 22, 2304563134), s = l(s, m, g, v, y[t + 12], 7, 1804603682), v = l(v, s, m, g, y[t + 13], 12, 4254626195), g = l(g, v, s, m, y[t + 14], 17, 2792965006), m = l(m, g, v, s, y[t + 15], 22, 1236535329), s = c(s, m, g, v, y[t + 1], 5, 4129170786), v = c(v, s, m, g, y[t + 6], 9, 3225465664), g = c(g, v, s, m, y[t + 11], 14, 643717713), m = c(m, g, v, s, y[t + 0], 20, 3921069994), s = c(s, m, g, v, y[t + 5], 5, 3593408605), v = c(v, s, m, g, y[t + 10], 9, 38016083), g = c(g, v, s, m, y[t + 15], 14, 3634488961), m = c(m, g, v, s, y[t + 4], 20, 3889429448), s = c(s, m, g, v, y[t + 9], 5, 568446438), v = c(v, s, m, g, y[t + 14], 9, 3275163606), g = c(g, v, s, m, y[t + 3], 14, 4107603335), m = c(m, g, v, s, y[t + 8], 20, 1163531501), s = c(s, m, g, v, y[t + 13], 5, 2850285829), v = c(v, s, m, g, y[t + 2], 9, 4243563512), g = c(g, v, s, m, y[t + 7], 14, 1735328473), m = c(m, g, v, s, y[t + 12], 20, 2368359562), s = u(s, m, g, v, y[t + 5], 4, 4294588738), v = u(v, s, m, g, y[t + 8], 11, 2272392833), g = u(g, v, s, m, y[t + 11], 16, 1839030562), m = u(m, g, v, s, y[t + 14], 23, 4259657740), s = u(s, m, g, v, y[t + 1], 4, 2763975236), v = u(v, s, m, g, y[t + 4], 11, 1272893353), g = u(g, v, s, m, y[t + 7], 16, 4139469664), m = u(m, g, v, s, y[t + 10], 23, 3200236656), s = u(s, m, g, v, y[t + 13], 4, 681279174), v = u(v, s, m, g, y[t + 0], 11, 3936430074), g = u(g, v, s, m, y[t + 3], 16, 3572445317), m = u(m, g, v, s, y[t + 6], 23, 76029189), s = u(s, m, g, v, y[t + 9], 4, 3654602809), v = u(v, s, m, g, y[t + 12], 11, 3873151461), g = u(g, v, s, m, y[t + 15], 16, 530742520), m = u(m, g, v, s, y[t + 2], 23, 3299628645), s = d(s, m, g, v, y[t + 0], 6, 4096336452), v = d(v, s, m, g, y[t + 7], 10, 1126891415), g = d(g, v, s, m, y[t + 14], 15, 2878612391), m = d(m, g, v, s, y[t + 5], 21, 4237533241), s = d(s, m, g, v, y[t + 12], 6, 1700485571), v = d(v, s, m, g, y[t + 3], 10, 2399980690), g = d(g, v, s, m, y[t + 10], 15, 4293915773), m = d(m, g, v, s, y[t + 1], 21, 2240044497), s = d(s, m, g, v, y[t + 8], 6, 1873313359), v = d(v, s, m, g, y[t + 15], 10, 4264355552), g = d(g, v, s, m, y[t + 6], 15, 2734768916), m = d(m, g, v, s, y[t + 13], 21, 1309151649), s = d(s, m, g, v, y[t + 4], 6, 4149444226), v = d(v, s, m, g, y[t + 11], 10, 3174756917), g = d(g, v, s, m, y[t + 2], 15, 718787259), m = d(m, g, v, s, y[t + 9], 21, 3951481745), s = r(s, n), m = r(m, i), g = r(g, a), v = r(v, o); return (p(s) + p(m) + p(g) + p(v)).toLowerCase() }
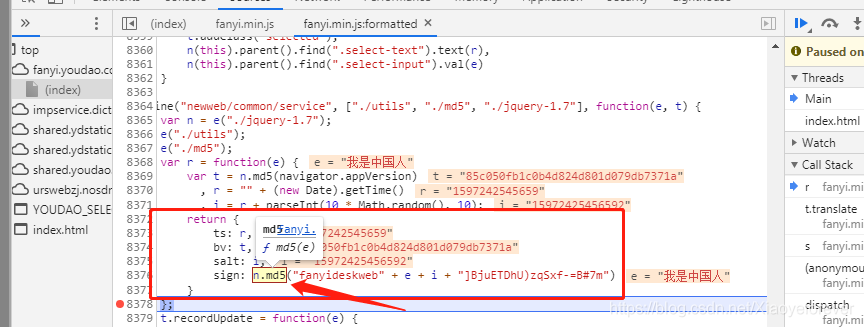
第四个参数:sign: n.md5(“fanyideskweb” + e + i + “]BjuETDhU)zqSxf-=B#7m”),相当于python中的sign=n.md5(“fanyideskweb” + e + i + “]BjuETDhU)zqSxf-=B#7m”), salt=i,e是你输入需要翻译的词语,即可写成sign=n.md5(“fanyideskweb” +str(e) + str(salt) + “]BjuETDhU)zqSxf-=B#7m”),继续选择直接扣代码。用python3调用js的库之execjs 来扣,鼠标放到 sign: n.md5(“fanyideskweb” + e + i + “]BjuETDhU)zqSxf-=B#7m”)中的n.md5()上,将会出现f md5(e)函数,点击进入,来到8196行, md5: function(e){ },把第8196行到8278行扣下来,竟然和刚才的扣bv的方法相同,仅仅是参数不同而已,bv的是 n.md5(navigator.appVersion)中的navigator.appVersion参数,现在的asin的是sign=n.md5(“fanyideskweb” +str(e) + str(salt) + “]BjuETDhU)zqSxf-=B#7m”)中的”fanyideskweb” +str(e) + str(salt) + “]BjuETDhU)zqSxf-=B#7m”参数,再应用execjs解析出sign.
注意:自调函数调用写法:
var aa=function(e){ }和function aa(e){ }写法都可以,一样的
import execjs f = open(r”text.js”,encoding=’utf-8’).read() ctx1 = execjs.compile(f) bv=ctx1.call(‘md5_2’,ua.random) print(bv)
扣出来的js代码:主体为function md52(e) { } ,应用execjs解析,缺什么参数找什么参数,即可_
var n = function(e, t) { return e << t | e >>> 32 - t } , r = function(e, t) { var n, r, i, a, o; return i = 2147483648 & e, a = 2147483648 & t, n = 1073741824 & e, r = 1073741824 & t, o = (1073741823 & e) + (1073741823 & t), n & r ? 2147483648 ^ o ^ i ^ a : n | r ? 1073741824 & o ? 3221225472 ^ o ^ i ^ a : 1073741824 ^ o ^ i ^ a : o ^ i ^ a } , i = function(e, t, n) { return e & t | ~e & n } , a = function(e, t, n) { return e & n | t & ~n } , o = function(e, t, n) { return e ^ t ^ n } , s = function(e, t, n) { return t ^ (e | ~n) } , l = function(e, t, a, o, s, l, c) { return e = r(e, r(r(i(t, a, o), s), c)), r(n(e, l), t) } , c = function(e, t, i, o, s, l, c) { return e = r(e, r(r(a(t, i, o), s), c)), r(n(e, l), t) } , u = function(e, t, i, a, s, l, c) { return e = r(e, r(r(o(t, i, a), s), c)), r(n(e, l), t) } , d = function(e, t, i, a, o, l, c) { return e = r(e, r(r(s(t, i, a), o), c)), r(n(e, l), t) } , f = function(e) { for (var t, n = e.length, r = n + 8, i = 16 * ((r - r % 64) / 64 + 1), a = Array(i - 1), o = 0, s = 0; s < n; ) o = s % 4 * 8, a[t = (s - s % 4) / 4] = a[t] | e.charCodeAt(s) << o, s++; return t = (s - s % 4) / 4, o = s % 4 * 8, a[t] = a[t] | 128 << o, a[i - 2] = n << 3, a[i - 1] = n >>> 29, a } , p = function(e) { var t, n = "", r = ""; for (t = 0; t <= 3; t++) n += (r = "0" + (e >>> 8 * t & 255).toString(16)).substr(r.length - 2, 2); return n }, h = function(e) { e = e.replace(/\\x0d\\x0a/g, "\\n"); for (var t = "", n = 0; n < e.length; n++) { var r = e.charCodeAt(n); if (r < 128) t += String.fromCharCode(r); else if (r > 127 && r < 2048) t += String.fromCharCode(r >> 6 | 192), t += String.fromCharCode(63 & r | 128); else if (r >= 55296 && r <= 56319) { if (n + 1 < e.length) { var i = e.charCodeAt(n + 1); if (i >= 56320 && i <= 57343) { var a = 1024 * (r - 55296) + (i - 56320) + 65536; t += String.fromCharCode(240 | a >> 18 & 7), t += String.fromCharCode(128 | a >> 12 & 63), t += String.fromCharCode(128 | a >> 6 & 63), t += String.fromCharCode(128 | 63 & a), n++ } } } else t += String.fromCharCode(r >> 12 | 224), t += String.fromCharCode(r >> 6 & 63 | 128), t += String.fromCharCode(63 & r | 128) } return t }; f = function(e) { for (var t, n = e.length, r = n + 8, i = 16 * ((r - r % 64) / 64 + 1), a = Array(i - 1), o = 0, s = 0; s < n; ) o = s % 4 * 8, a[t = (s - s % 4) / 4] = a[t] | e.charCodeAt(s) << o, s++; return t = (s - s % 4) / 4, o = s % 4 * 8, a[t] = a[t] | 128 << o, a[i - 2] = n << 3, a[i - 1] = n >>> 29, a }
function md5_2(e) { var t, n, i, a, o, s, m, g, v, y = Array(); for (e = e, y = f(e), s = 1732584193, m = 4023233417, g = 2562383102, v = 271733878, t = 0; t < y.length; t += 16) n = s, i = m, a = g, o = v, s = l(s, m, g, v, y[t + 0], 7, 3614090360), v = l(v, s, m, g, y[t + 1], 12, 3905402710), g = l(g, v, s, m, y[t + 2], 17, 606105819), m = l(m, g, v, s, y[t + 3], 22, 3250441966), s = l(s, m, g, v, y[t + 4], 7, 4118548399), v = l(v, s, m, g, y[t + 5], 12, 1200080426), g = l(g, v, s, m, y[t + 6], 17, 2821735955), m = l(m, g, v, s, y[t + 7], 22, 4249261313), s = l(s, m, g, v, y[t + 8], 7, 1770035416), v = l(v, s, m, g, y[t + 9], 12, 2336552879), g = l(g, v, s, m, y[t + 10], 17, 4294925233), m = l(m, g, v, s, y[t + 11], 22, 2304563134), s = l(s, m, g, v, y[t + 12], 7, 1804603682), v = l(v, s, m, g, y[t + 13], 12, 4254626195), g = l(g, v, s, m, y[t + 14], 17, 2792965006), m = l(m, g, v, s, y[t + 15], 22, 1236535329), s = c(s, m, g, v, y[t + 1], 5, 4129170786), v = c(v, s, m, g, y[t + 6], 9, 3225465664), g = c(g, v, s, m, y[t + 11], 14, 643717713), m = c(m, g, v, s, y[t + 0], 20, 3921069994), s = c(s, m, g, v, y[t + 5], 5, 3593408605), v = c(v, s, m, g, y[t + 10], 9, 38016083), g = c(g, v, s, m, y[t + 15], 14, 3634488961), m = c(m, g, v, s, y[t + 4], 20, 3889429448), s = c(s, m, g, v, y[t + 9], 5, 568446438), v = c(v, s, m, g, y[t + 14], 9, 3275163606), g = c(g, v, s, m, y[t + 3], 14, 4107603335), m = c(m, g, v, s, y[t + 8], 20, 1163531501), s = c(s, m, g, v, y[t + 13], 5, 2850285829), v = c(v, s, m, g, y[t + 2], 9, 4243563512), g = c(g, v, s, m, y[t + 7], 14, 1735328473), m = c(m, g, v, s, y[t + 12], 20, 2368359562), s = u(s, m, g, v, y[t + 5], 4, 4294588738), v = u(v, s, m, g, y[t + 8], 11, 2272392833), g = u(g, v, s, m, y[t + 11], 16, 1839030562), m = u(m, g, v, s, y[t + 14], 23, 4259657740), s = u(s, m, g, v, y[t + 1], 4, 2763975236), v = u(v, s, m, g, y[t + 4], 11, 1272893353), g = u(g, v, s, m, y[t + 7], 16, 4139469664), m = u(m, g, v, s, y[t + 10], 23, 3200236656), s = u(s, m, g, v, y[t + 13], 4, 681279174), v = u(v, s, m, g, y[t + 0], 11, 3936430074), g = u(g, v, s, m, y[t + 3], 16, 3572445317), m = u(m, g, v, s, y[t + 6], 23, 76029189), s = u(s, m, g, v, y[t + 9], 4, 3654602809), v = u(v, s, m, g, y[t + 12], 11, 3873151461), g = u(g, v, s, m, y[t + 15], 16, 530742520), m = u(m, g, v, s, y[t + 2], 23, 3299628645), s = d(s, m, g, v, y[t + 0], 6, 4096336452), v = d(v, s, m, g, y[t + 7], 10, 1126891415), g = d(g, v, s, m, y[t + 14], 15, 2878612391), m = d(m, g, v, s, y[t + 5], 21, 4237533241), s = d(s, m, g, v, y[t + 12], 6, 1700485571), v = d(v, s, m, g, y[t + 3], 10, 2399980690), g = d(g, v, s, m, y[t + 10], 15, 4293915773), m = d(m, g, v, s, y[t + 1], 21, 2240044497), s = d(s, m, g, v, y[t + 8], 6, 1873313359), v = d(v, s, m, g, y[t + 15], 10, 4264355552), g = d(g, v, s, m, y[t + 6], 15, 2734768916), m = d(m, g, v, s, y[t + 13], 21, 1309151649), s = d(s, m, g, v, y[t + 4], 6, 4149444226), v = d(v, s, m, g, y[t + 11], 10, 3174756917), g = d(g, v, s, m, y[t + 2], 15, 718787259), m = d(m, g, v, s, y[t + 9], 21, 3951481745), s = r(s, n), m = r(m, i), g = r(g, a), v = r(v, o); return (p(s) + p(m) + p(g) + p(v)).toLowerCase() }
9.大功告成,四个可变参数全部搞定,即可搞定&
附上完整代码 python部分:
import time import execjs import random import requests import json from fake_useragent import UserAgent # var aa=function(e) function aa(e)
class YouDaoTanslate(): def init(self): #类方法调用 self.js_par() def js_par(self): translation_data = input(“请输入要翻译的词或者句子:”) # 13位时间戳获取方法:单位:毫秒 ua = UserAgent() print(ua.random) t1 = time.time() ts = int(t1 * 1000) print(ts) salt = str(int(ts)) + str(random.randint(0, 10)) print(salt)
f = open(r”text.js”, encoding=’utf-8’).read() ctx1 = execjs.compile(f) bv = ctx1.call(‘md5_1’, ua.random) print(bv)
ctx2 = execjs.compile(f) sign_data = ‘fanyideskweb’ + translation_data + salt + ‘mmbP%A-r6U3Nw(n]BjuEU’ sign = ctx2.call(‘md5_2’, sign_data) print(sign)
self.get_translateData(translation_data,ua,ts,salt,bv,sign) def get_translateData(self,translation_data,ua,ts,salt,bv,sign): url = ‘http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule‘ headers = { ‘Host’: ‘fanyi.youdao.com’, ‘Origin’: ‘http://fanyi.youdao.com‘, ‘Referer’: ‘http://fanyi.youdao.com/‘, ‘User-Agent’: ua.random, ‘X-Requested-With’: ‘XMLHttpRequest’, ‘Cookie’: ‘OUTFOX_SEARCH_USER_ID_NCOO=892433278.3204294; OUTFOX_SEARCH_USER_ID=”-1911793285@10.108.160.19”; _ntes_nnid=d2bb7793f13c9a83907e33d40665337a,1597158692753; JSESSIONID=aaamUZK4O580YaKjmjIpx; _rltest__cookies=1597227802599’ } data = { ‘i’: translation_data, ‘from’: ‘AUTO’, ‘to’: ‘AUTO’, ‘smartresult’: ‘dict’, ‘client’: ‘fanyideskweb’, ‘salt’: str(salt), ‘sign’: str(sign), ‘ts’: str(ts), ‘bv’: str(bv), ‘doctype’: ‘json’, ‘version’: ‘2.1’, ‘keyfrom’: ‘fanyi.web’, ‘action’: ‘FY_BY_CLICKBUTTION’ }
response = requests.post(url=url, data=data, headers=headers)
response = requests.post(url=url, data=data, headers=headers) translate_results = json.loads(response.text) # 找到翻译结果 if ‘translateResult’ in translate_results: translate_results = translate_results[‘translateResult’][0][0][‘tgt’] print(“翻译的结果是:%s” % translate_results)
else: print(translate_results)
self.js_par()
YouDaoTanslate()
js部分:
var n = function(e, t) { return e << t | e >>> 32 - t } , r = function(e, t) { var n, r, i, a, o; return i = 2147483648 & e, a = 2147483648 & t, n = 1073741824 & e, r = 1073741824 & t, o = (1073741823 & e) + (1073741823 & t), n & r ? 2147483648 ^ o ^ i ^ a : n | r ? 1073741824 & o ? 3221225472 ^ o ^ i ^ a : 1073741824 ^ o ^ i ^ a : o ^ i ^ a } , i = function(e, t, n) { return e & t | ~e & n } , a = function(e, t, n) { return e & n | t & ~n } , o = function(e, t, n) { return e ^ t ^ n } , s = function(e, t, n) { return t ^ (e | ~n) } , l = function(e, t, a, o, s, l, c) { return e = r(e, r(r(i(t, a, o), s), c)), r(n(e, l), t) } , c = function(e, t, i, o, s, l, c) { return e = r(e, r(r(a(t, i, o), s), c)), r(n(e, l), t) } , u = function(e, t, i, a, s, l, c) { return e = r(e, r(r(o(t, i, a), s), c)), r(n(e, l), t) } , d = function(e, t, i, a, o, l, c) { return e = r(e, r(r(s(t, i, a), o), c)), r(n(e, l), t) } , f = function(e) { for (var t, n = e.length, r = n + 8, i = 16 * ((r - r % 64) / 64 + 1), a = Array(i - 1), o = 0, s = 0; s < n; ) o = s % 4 * 8, a[t = (s - s % 4) / 4] = a[t] | e.charCodeAt(s) << o, s++; return t = (s - s % 4) / 4, o = s % 4 * 8, a[t] = a[t] | 128 << o, a[i - 2] = n << 3, a[i - 1] = n >>> 29, a } , p = function(e) { var t, n = "", r = ""; for (t = 0; t <= 3; t++) n += (r = "0" + (e >>> 8 * t & 255).toString(16)).substr(r.length - 2, 2); return n }, h = function(e) { e = e.replace(/\\x0d\\x0a/g, "\\n"); for (var t = "", n = 0; n < e.length; n++) { var r = e.charCodeAt(n); if (r < 128) t += String.fromCharCode(r); else if (r > 127 && r < 2048) t += String.fromCharCode(r >> 6 | 192), t += String.fromCharCode(63 & r | 128); else if (r >= 55296 && r <= 56319) { if (n + 1 < e.length) { var i = e.charCodeAt(n + 1); if (i >= 56320 && i <= 57343) { var a = 1024 * (r - 55296) + (i - 56320) + 65536; t += String.fromCharCode(240 | a >> 18 & 7), t += String.fromCharCode(128 | a >> 12 & 63), t += String.fromCharCode(128 | a >> 6 & 63), t += String.fromCharCode(128 | 63 & a), n++ } } } else t += String.fromCharCode(r >> 12 | 224), t += String.fromCharCode(r >> 6 & 63 | 128), t += String.fromCharCode(63 & r | 128) } return t }; f = function(e) { for (var t, n = e.length, r = n + 8, i = 16 * ((r - r % 64) / 64 + 1), a = Array(i - 1), o = 0, s = 0; s < n; ) o = s % 4 * 8, a[t = (s - s % 4) / 4] = a[t] | e.charCodeAt(s) << o, s++; return t = (s - s % 4) / 4, o = s % 4 * 8, a[t] = a[t] | 128 << o, a[i - 2] = n << 3, a[i - 1] = n >>> 29, a } function md5_1(e) { var t, n, i, a, o, s, m, g, v, y = Array(); for (e = e, y = f, s = 1732584193, m = 4023233417, g = 2562383102, v = 271733878, t = 0; t < y.length; t += 16) n = s, i = m, a = g, o = v, s = l(s, m, g, v, y[t + 0], 7, 3614090360), v = l(v, s, m, g, y[t + 1], 12, 3905402710), g = l(g, v, s, m, y[t + 2], 17, 606105819), m = l(m, g, v, s, y[t + 3], 22, 3250441966), s = l(s, m, g, v, y[t + 4], 7, 4118548399), v = l(v, s, m, g, y[t + 5], 12, 1200080426), g = l(g, v, s, m, y[t + 6], 17, 2821735955), m = l(m, g, v, s, y[t + 7], 22, 4249261313), s = l(s, m, g, v, y[t + 8], 7, 1770035416), v = l(v, s, m, g, y[t + 9], 12, 2336552879), g = l(g, v, s, m, y[t + 10], 17, 4294925233), m = l(m, g, v, s, y[t + 11], 22, 2304563134), s = l(s, m, g, v, y[t + 12], 7, 1804603682), v = l(v, s, m, g, y[t + 13], 12, 4254626195), g = l(g, v, s, m, y[t + 14], 17, 2792965006), m = l(m, g, v, s, y[t + 15], 22, 1236535329), s = c(s, m, g, v, y[t + 1], 5, 4129170786), v = c(v, s, m, g, y[t + 6], 9, 3225465664), g = c(g, v, s, m, y[t + 11], 14, 643717713), m = c(m, g, v, s, y[t + 0], 20, 3921069994), s = c(s, m, g, v, y[t + 5], 5, 3593408605), v = c(v, s, m, g, y[t + 10], 9, 38016083), g = c(g, v, s, m, y[t + 15], 14, 3634488961), m = c(m, g, v, s, y[t + 4], 20, 3889429448), s = c(s, m, g, v, y[t + 9], 5, 568446438), v = c(v, s, m, g, y[t + 14], 9, 3275163606), g = c(g, v, s, m, y[t + 3], 14, 4107603335), m = c(m, g, v, s, y[t + 8], 20, 1163531501), s = c(s, m, g, v, y[t + 13], 5, 2850285829), v = c(v, s, m, g, y[t + 2], 9, 4243563512), g = c(g, v, s, m, y[t + 7], 14, 1735328473), m = c(m, g, v, s, y[t + 12], 20, 2368359562), s = u(s, m, g, v, y[t + 5], 4, 4294588738), v = u(v, s, m, g, y[t + 8], 11, 2272392833), g = u(g, v, s, m, y[t + 11], 16, 1839030562), m = u(m, g, v, s, y[t + 14], 23, 4259657740), s = u(s, m, g, v, y[t + 1], 4, 2763975236), v = u(v, s, m, g, y[t + 4], 11, 1272893353), g = u(g, v, s, m, y[t + 7], 16, 4139469664), m = u(m, g, v, s, y[t + 10], 23, 3200236656), s = u(s, m, g, v, y[t + 13], 4, 681279174), v = u(v, s, m, g, y[t + 0], 11, 3936430074), g = u(g, v, s, m, y[t + 3], 16, 3572445317), m = u(m, g, v, s, y[t + 6], 23, 76029189), s = u(s, m, g, v, y[t + 9], 4, 3654602809), v = u(v, s, m, g, y[t + 12], 11, 3873151461), g = u(g, v, s, m, y[t + 15], 16, 530742520), m = u(m, g, v, s, y[t + 2], 23, 3299628645), s = d(s, m, g, v, y[t + 0], 6, 4096336452), v = d(v, s, m, g, y[t + 7], 10, 1126891415), g = d(g, v, s, m, y[t + 14], 15, 2878612391), m = d(m, g, v, s, y[t + 5], 21, 4237533241), s = d(s, m, g, v, y[t + 12], 6, 1700485571), v = d(v, s, m, g, y[t + 3], 10, 2399980690), g = d(g, v, s, m, y[t + 10], 15, 4293915773), m = d(m, g, v, s, y[t + 1], 21, 2240044497), s = d(s, m, g, v, y[t + 8], 6, 1873313359), v = d(v, s, m, g, y[t + 15], 10, 4264355552), g = d(g, v, s, m, y[t + 6], 15, 2734768916), m = d(m, g, v, s, y[t + 13], 21, 1309151649), s = d(s, m, g, v, y[t + 4], 6, 4149444226), v = d(v, s, m, g, y[t + 11], 10, 3174756917), g = d(g, v, s, m, y[t + 2], 15, 718787259), m = d(m, g, v, s, y[t + 9], 21, 3951481745), s = r(s, n), m = r(m, i), g = r(g, a), v = r(v, o); return (p(s) + p(m) + p(g) + p(v)).toLowerCase() }
var n = function(e, t) { return e << t | e >>> 32 - t } , r = function(e, t) { var n, r, i, a, o; return i = 2147483648 & e, a = 2147483648 & t, n = 1073741824 & e, r = 1073741824 & t, o = (1073741823 & e) + (1073741823 & t), n & r ? 2147483648 ^ o ^ i ^ a : n | r ? 1073741824 & o ? 3221225472 ^ o ^ i ^ a : 1073741824 ^ o ^ i ^ a : o ^ i ^ a } , i = function(e, t, n) { return e & t | ~e & n } , a = function(e, t, n) { return e & n | t & ~n } , o = function(e, t, n) { return e ^ t ^ n } , s = function(e, t, n) { return t ^ (e | ~n) } , l = function(e, t, a, o, s, l, c) { return e = r(e, r(r(i(t, a, o), s), c)), r(n(e, l), t) } , c = function(e, t, i, o, s, l, c) { return e = r(e, r(r(a(t, i, o), s), c)), r(n(e, l), t) } , u = function(e, t, i, a, s, l, c) { return e = r(e, r(r(o(t, i, a), s), c)), r(n(e, l), t) } , d = function(e, t, i, a, o, l, c) { return e = r(e, r(r(s(t, i, a), o), c)), r(n(e, l), t) } , f = function(e) { for (var t, n = e.length, r = n + 8, i = 16 ((r - r % 64) / 64 + 1), a = Array(i - 1), o = 0, s = 0; s < n; ) o = s % 4 8, a[t = (s - s % 4) / 4] = a[t] | e.charCodeAt(s) << o, s++; return t = (s - s % 4) / 4, o = s % 4 8, a[t] = a[t] | 128 << o, a[i - 2] = n << 3, a[i - 1] = n >>> 29, a } , p = function(e) { var t, n = “”, r = “”; for (t = 0; t <= 3; t++) n += (r = “0” + (e >>> 8 t & 255).toString(16)).substr(r.length - 2, 2); return n }, h = function(e) { e = e.replace(/\x0d\x0a/g, “\n”); for (var t = “”, n = 0; n < e.length; n++) { var r = e.charCodeAt(n); if (r < 128) t += String.fromCharCode(r); else if (r > 127 && r < 2048) t += String.fromCharCode(r >> 6 | 192), t += String.fromCharCode(63 & r | 128); else if (r >= 55296 && r <= 56319) { if (n + 1 < e.length) { var i = e.charCodeAt(n + 1); if (i >= 56320 && i <= 57343) { var a = 1024 (r - 55296) + (i - 56320) + 65536; t += String.fromCharCode(240 | a >> 18 & 7), t += String.fromCharCode(128 | a >> 12 & 63), t += String.fromCharCode(128 | a >> 6 & 63), t += String.fromCharCode(128 | 63 & a), n++ } } } else t += String.fromCharCode(r >> 12 | 224), t += String.fromCharCode(r >> 6 & 63 | 128), t += String.fromCharCode(63 & r | 128) } return t }; f = function(e) { for (var t, n = e.length, r = n + 8, i = 16 ((r - r % 64) / 64 + 1), a = Array(i - 1), o = 0, s = 0; s < n; ) o = s % 4 8, a[t = (s - s % 4) / 4] = a[t] | e.charCodeAt(s) << o, s++; return t = (s - s % 4) / 4, o = s % 4 8, a[t] = a[t] | 128 << o, a[i - 2] = n << 3, a[i - 1] = n >>> 29, a }
function md5_2(e) { var t, n, i, a, o, s, m, g, v, y = Array(); for (e = e, y = f(e), s = 1732584193, m = 4023233417, g = 2562383102, v = 271733878, t = 0; t < y.length; t += 16) n = s, i = m, a = g, o = v, s = l(s, m, g, v, y[t + 0], 7, 3614090360), v = l(v, s, m, g, y[t + 1], 12, 3905402710), g = l(g, v, s, m, y[t + 2], 17, 606105819), m = l(m, g, v, s, y[t + 3], 22, 3250441966), s = l(s, m, g, v, y[t + 4], 7, 4118548399), v = l(v, s, m, g, y[t + 5], 12, 1200080426), g = l(g, v, s, m, y[t + 6], 17, 2821735955), m = l(m, g, v, s, y[t + 7], 22, 4249261313), s = l(s, m, g, v, y[t + 8], 7, 1770035416), v = l(v, s, m, g, y[t + 9], 12, 2336552879), g = l(g, v, s, m, y[t + 10], 17, 4294925233), m = l(m, g, v, s, y[t + 11], 22, 2304563134), s = l(s, m, g, v, y[t + 12], 7, 1804603682), v = l(v, s, m, g, y[t + 13], 12, 4254626195), g = l(g, v, s, m, y[t + 14], 17, 2792965006), m = l(m, g, v, s, y[t + 15], 22, 1236535329), s = c(s, m, g, v, y[t + 1], 5, 4129170786), v = c(v, s, m, g, y[t + 6], 9, 3225465664), g = c(g, v, s, m, y[t + 11], 14, 643717713), m = c(m, g, v, s, y[t + 0], 20, 3921069994), s = c(s, m, g, v, y[t + 5], 5, 3593408605), v = c(v, s, m, g, y[t + 10], 9, 38016083), g = c(g, v, s, m, y[t + 15], 14, 3634488961), m = c(m, g, v, s, y[t + 4], 20, 3889429448), s = c(s, m, g, v, y[t + 9], 5, 568446438), v = c(v, s, m, g, y[t + 14], 9, 3275163606), g = c(g, v, s, m, y[t + 3], 14, 4107603335), m = c(m, g, v, s, y[t + 8], 20, 1163531501), s = c(s, m, g, v, y[t + 13], 5, 2850285829), v = c(v, s, m, g, y[t + 2], 9, 4243563512), g = c(g, v, s, m, y[t + 7], 14, 1735328473), m = c(m, g, v, s, y[t + 12], 20, 2368359562), s = u(s, m, g, v, y[t + 5], 4, 4294588738), v = u(v, s, m, g, y[t + 8], 11, 2272392833), g = u(g, v, s, m, y[t + 11], 16, 1839030562), m = u(m, g, v, s, y[t + 14], 23, 4259657740), s = u(s, m, g, v, y[t + 1], 4, 2763975236), v = u(v, s, m, g, y[t + 4], 11, 1272893353), g = u(g, v, s, m, y[t + 7], 16, 4139469664), m = u(m, g, v, s, y[t + 10], 23, 3200236656), s = u(s, m, g, v, y[t + 13], 4, 681279174), v = u(v, s, m, g, y[t + 0], 11, 3936430074), g = u(g, v, s, m, y[t + 3], 16, 3572445317), m = u(m, g, v, s, y[t + 6], 23, 76029189), s = u(s, m, g, v, y[t + 9], 4, 3654602809), v = u(v, s, m, g, y[t + 12], 11, 3873151461), g = u(g, v, s, m, y[t + 15], 16, 530742520), m = u(m, g, v, s, y[t + 2], 23, 3299628645), s = d(s, m, g, v, y[t + 0], 6, 4096336452), v = d(v, s, m, g, y[t + 7], 10, 1126891415), g = d(g, v, s, m, y[t + 14], 15, 2878612391), m = d(m, g, v, s, y[t + 5], 21, 4237533241), s = d(s, m, g, v, y[t + 12], 6, 1700485571), v = d(v, s, m, g, y[t + 3], 10, 2399980690), g = d(g, v, s, m, y[t + 10], 15, 4293915773), m = d(m, g, v, s, y[t + 1], 21, 2240044497), s = d(s, m, g, v, y[t + 8], 6, 1873313359), v = d(v, s, m, g, y[t + 15], 10, 4264355552), g = d(g, v, s, m, y[t + 6], 15, 2734768916), m = d(m, g, v, s, y[t + 13], 21, 1309151649), s = d(s, m, g, v, y[t + 4], 6, 4149444226), v = d(v, s, m, g, y[t + 11], 10, 3174756917), g = d(g, v, s, m, y[t + 2], 15, 718787259), m = d(m, g, v, s, y[t + 9], 21, 3951481745), s = r(s, n), m = r(m, i), g = r(g, a), v = r(v, o); return (p(s) + p(m) + p(g) + p(v)).toLowerCase() }
上市了!")































































 代码:
代码:
























































 每条保留字指令必须为大写字母且后面要跟随至少一个参数 指令从上到下、从左至右执行 ‘#’ :表示注释 每条指令都会创建一个新的镜像层,并对镜像进行提交
每条保留字指令必须为大写字母且后面要跟随至少一个参数 指令从上到下、从左至右执行 ‘#’ :表示注释 每条指令都会创建一个新的镜像层,并对镜像进行提交


 容器停止后,主机修改后数据是否同步 可以!但需为同一个容器!!![The same container_id]
容器停止后,主机修改后数据是否同步 可以!但需为同一个容器!!![The same container_id]
 我们实际使用时,如果需要在 Python 中拿到 object 的话,建议把它转换成一个 json 字符串,而不是直接的把结果 return 出来。 因为,有些时候 PyExecjs 对 object 的转换会出现问题,所以我们可能会拿到一些类似于将字典直接用 str 函数包裹后转为字符串的一个东西,这样的话它是无法通过正常的方式去解析的。 或者说你也可能会遇到其情况的报错,总之大家最好先转一下 json 字符串,然后再 return 避免踩坑。这是我们的一个代码。 接下来我们来说一下,PyExecJS 存在的一些问题主要有以下两点:
我们实际使用时,如果需要在 Python 中拿到 object 的话,建议把它转换成一个 json 字符串,而不是直接的把结果 return 出来。 因为,有些时候 PyExecjs 对 object 的转换会出现问题,所以我们可能会拿到一些类似于将字典直接用 str 函数包裹后转为字符串的一个东西,这样的话它是无法通过正常的方式去解析的。 或者说你也可能会遇到其情况的报错,总之大家最好先转一下 json 字符串,然后再 return 避免踩坑。这是我们的一个代码。 接下来我们来说一下,PyExecJS 存在的一些问题主要有以下两点:

 我还能观察到,input 标签里面有两个属性,一个是 id、一个是 data,这两个是比较关键的属性,然后我们还发现这里面引用了一个 js 文件,所以这个网页最终结果实际上是通过 JS 文件,然后一系列的操作生成的,那接下来我就来看看 JS 文件,做了什么工作。
我还能观察到,input 标签里面有两个属性,一个是 id、一个是 data,这两个是比较关键的属性,然后我们还发现这里面引用了一个 js 文件,所以这个网页最终结果实际上是通过 JS 文件,然后一系列的操作生成的,那接下来我就来看看 JS 文件,做了什么工作。 


 在 console 里面打印一下 Object(u.a)(e.encrypt_data) 初一看,好像是又好像不是(仅有部分信息)
在 console 里面打印一下 Object(u.a)(e.encrypt_data) 初一看,好像是又好像不是(仅有部分信息) 没错,就是它。老板,求解密一下? ok,感谢老板。再次在 console 里面打印一下 Object(u.a)(e.encrypt_data) 当当当~
没错,就是它。老板,求解密一下? ok,感谢老板。再次在 console 里面打印一下 Object(u.a)(e.encrypt_data) 当当当~ 
 ok,那它是怎么来的呢?
ok,那它是怎么来的呢?
 当当当~,扣它,把这个函数扣出来(快到我怀里来~)
当当当~,扣它,把这个函数扣出来(快到我怀里来~) 
 到这里就基本上把主函数弄完了,但是还没有完 a.a.decode(t)这个鬼我们还不晓得,进去找他,扣它
到这里就基本上把主函数弄完了,但是还没有完 a.a.decode(t)这个鬼我们还不晓得,进去找他,扣它 

 完成!
完成!