上市了!")



Ansible简介
Ansible是由Python开发的一个运维工具,因为工作需要接触到Ansible,经常会集成一些东西到Ansible,所以对Ansible的了解越来越多。 那Ansible到底是什么呢?在我的理解中,原来需要登录到服务器上,然后执行一堆命令才能完成一些操作。而Ansible就是来代替我们去执行那些命令。并且可以通过Ansible控制多台机器,在机器上进行任务的编排和执行,在Ansible中称为playbook。 那Ansible是如何做到的呢?简单点说,就是Ansible将我们要执行的命令生成一个脚本,然后通过sftp将脚本上传到要执行命令的服务器上,然后在通过ssh协议,执行这个脚本并将执行结果返回。 那Ansible具体是怎么做到的呢?下面从模块和插件来看一下Ansible是如何完成一个模块的执行 PS:下面的分析都是在对Ansible有一些具体使用经验之后,通过阅读源代码进一步得出的执行结论,所以希望在看本文时,是建立在对Ansible有一定了解的基础上,最起码对于Ansible的一些概念有了解,例如inventory,module,playbooks等
Ansible模块
模块是Ansible执行的最小单位,可以是由Python编写,也可以是Shell编写,也可以是由其他语言编写。模块中定义了具体的操作步骤以及实际使用过程中所需要的参数 执行的脚本就是根据模块生成一个可执行的脚本。 那Ansible是怎么样将这个脚本上传到服务器上,然后执行获取结果的呢?
Ansible插件
connection插件
连接插件,根据指定的ssh参数连接指定的服务器,并切提供实际执行命令的接口
shell插件
命令插件,根据sh类型,来生成用于connection时要执行的命令
strategy插件
执行策略插件,默认情况下是线性插件,就是一个任务接着一个任务的向下执行,此插件将任务丢到执行器去执行。
action插件
动作插件,实质就是任务模块的所有动作,如果ansible的模块没有特别编写的action插件,默认情况下是normal或者async(这两个根据模块是否async来选择),normal和async中定义的就是模块的执行步骤。例如,本地创建临时文件,上传临时文件,执行脚本,删除脚本等等,如果想在所有的模块中增加一些特殊步骤,可以通过增加action插件的方式来扩展。
Ansible执行模块流程
- ansible命令实质是通过ansible/cli/adhoc.py来运行,同时会收集参数信息
- 设置Play信息,然后通过TaskQueueManager进行run,
- TaskQueueManager需要Inventory(节点仓库),variable_manager(收集变量),options(命令行中指定的参数),stdout_callback(回调函数)
- 在task_queue_manager.py中找到run中
- 初始化时会设置队列
- 会根据options,,variable_manager,passwords等信息设置成一个PlayContext信息(playbooks/playcontext.py)
- 设置插件(plugins)信息callback_loader(回调), strategy_loader(执行策略), module_loader(任务模块)
- 通过strategy_loader(strategy插件)的run(默认的strategy类型是linear,线性执行),去按照顺序执行所有的任务(执行一个模块,可能会执行多个任务)
- 在strategy_loader插件run之后,会判断action类型。如果是meta类型的话会单独执行(不是具体的ansible模块时),而其他模块时,会加载到队列_queue_task
- 在队列中会调用WorkerProcess去处理,在workerproces实际的run之后,会使用TaskExecutor进行执行
- 在TaskExecutor中会设置connection插件,并且根据task的类型(模块。或是include等)获取action插件,就是对应的模块,如果模块有自定义的执行,则会执行自定义的action,如果没有的会使用normal或者async,这个是根据是否是任务的async属性来决定
- 在Action插件中定义着执行的顺序,及具体操作,例如生成临时目录,生成临时脚本,所以要在统一的模式下,集成一些额外的处理时,可以重写Action的方法
- 通过Connection插件来执行Action的各个操作步骤
扩展Ansible实例
执行节点Python环境扩展
实际需求中,我们扩展的一些Ansible模块需要使用三方库,但每个节点中安装这些库有些不易于管理。ansible执行模块的实质就是在节点的python环境下执行生成的脚本,所以我们采取的方案是,指定节点上的Python环境,将局域网内一个python环境作为nfs共享。通过扩展Action插件,增加节点上挂载nfs,待执行结束后再将节点上的nfs卸载。具体实施步骤如下: 扩展代码:
重写ActionBase的execute_module方法
1 |
# execute_module |
集成到normal.py和async.py中,记住要将这两个插件在ansible.cfg中进行配置
1 |
from __future__ import (absolute_import, division, print_function) |
- 配置ansible.cfg,将扩展的插件指定为ansible需要的action插件
- 重写插件方法,重点是execute_module
- 执行命令中需要指定Python环境,将需要的参数添加进去nfs挂载和卸载的参数
1 |
ansible 51 -m mysql_db -a "state=dump name=all target=/tmp/test.sql" -i hosts -u root -v -e "ansible_nfs_src=172.16.30.170:/web/proxy_env/lib64/python2.7/site-packages ansible_nfs_dest=/root/.pyenv/versions/2.7.10/lib/python2.7/site-packages ansible_python_interpreter=/root/.pyenv/versions/2.7.10/bin/python" |
 接下来我们在浏览器中打开
接下来我们在浏览器中打开  这里显示了主机、项目的状态,当然由于我们没有添加主机,所以所有的数目都是 0。 如果我们可以正常访问这个页面,那就证明 Gerapy 初始化都成功了。
这里显示了主机、项目的状态,当然由于我们没有添加主机,所以所有的数目都是 0。 如果我们可以正常访问这个页面,那就证明 Gerapy 初始化都成功了。 需要添加 IP、端口,以及名称,点击创建即可完成添加,点击返回即可看到当前添加的 Scrapyd 服务列表,样例如下所示:
需要添加 IP、端口,以及名称,点击创建即可完成添加,点击返回即可看到当前添加的 Scrapyd 服务列表,样例如下所示:  这样我们可以在状态一栏看到各个 Scrapyd 服务是否可用,同时可以一目了然当前所有 Scrapyd 服务列表,另外我们还可以自由地进行编辑和删除。
这样我们可以在状态一栏看到各个 Scrapyd 服务是否可用,同时可以一目了然当前所有 Scrapyd 服务列表,另外我们还可以自由地进行编辑和删除。 假设现在我们有一个 Scrapy 项目,如果我们想要进行管理和部署,还记得初始化过程中提到的 projects 文件夹吗?这时我们只需要将项目拖动到刚才 gerapy 运行目录的 projects 文件夹下,例如我这里写好了一个 Scrapy 项目,名字叫做 zhihusite,这时把它拖动到 projects 文件夹下:
假设现在我们有一个 Scrapy 项目,如果我们想要进行管理和部署,还记得初始化过程中提到的 projects 文件夹吗?这时我们只需要将项目拖动到刚才 gerapy 运行目录的 projects 文件夹下,例如我这里写好了一个 Scrapy 项目,名字叫做 zhihusite,这时把它拖动到 projects 文件夹下:  这时刷新页面,我们便可以看到 Gerapy 检测到了这个项目,同时它是不可配置、没有打包的:
这时刷新页面,我们便可以看到 Gerapy 检测到了这个项目,同时它是不可配置、没有打包的:  这时我们可以点击部署按钮进行打包和部署,在右下角我们可以输入打包时的描述信息,类似于 Git 的 commit 信息,然后点击打包按钮,即可发现 Gerapy 会提示打包成功,同时在左侧显示打包的结果和打包名称:
这时我们可以点击部署按钮进行打包和部署,在右下角我们可以输入打包时的描述信息,类似于 Git 的 commit 信息,然后点击打包按钮,即可发现 Gerapy 会提示打包成功,同时在左侧显示打包的结果和打包名称:  打包成功之后,我们便可以进行部署了,我们可以选择需要部署的主机,点击后方的部署按钮进行部署,同时也可以批量选择主机进行部署,示例如下:
打包成功之后,我们便可以进行部署了,我们可以选择需要部署的主机,点击后方的部署按钮进行部署,同时也可以批量选择主机进行部署,示例如下:  可以发现此方法相比 Scrapyd-Client 的命令行式部署,简直不能方便更多。
可以发现此方法相比 Scrapyd-Client 的命令行式部署,简直不能方便更多。 我们可以通过点击新任务、停止等按钮来实现任务的启动和停止等操作,同时也可以通过展开任务条目查看日志详情:
我们可以通过点击新任务、停止等按钮来实现任务的启动和停止等操作,同时也可以通过展开任务条目查看日志详情:  另外我们还可以随时点击停止按钮来取消 Scrapy 任务的运行。 这样我们就可以在此页面方便地管理每个 Scrapyd 服务上的 每个 Scrapy 项目的运行了。
另外我们还可以随时点击停止按钮来取消 Scrapy 任务的运行。 这样我们就可以在此页面方便地管理每个 Scrapyd 服务上的 每个 Scrapy 项目的运行了。 这样即使 Gerapy 部署在远程的服务器上,我们不方便用 IDE 打开,也不喜欢用 Vim 等编辑软件,我们可以借助于本功能方便地完成代码的编写。
这样即使 Gerapy 部署在远程的服务器上,我们不方便用 IDE 打开,也不喜欢用 Vim 等编辑软件,我们可以借助于本功能方便地完成代码的编写。 再比如爬取规则,我们可以指定从哪个链接开始爬取,允许爬取的域名是什么,该链接提取哪些跟进的链接,用什么解析方法来处理等等配置。通过这些配置,我们可以完成爬取规则的设置。
再比如爬取规则,我们可以指定从哪个链接开始爬取,允许爬取的域名是什么,该链接提取哪些跟进的链接,用什么解析方法来处理等等配置。通过这些配置,我们可以完成爬取规则的设置。  最后点击生成按钮即可完成代码的生成。
最后点击生成按钮即可完成代码的生成。  生成的代码示例结果如图所示,可见其结构和 Scrapy 代码是完全一致的。
生成的代码示例结果如图所示,可见其结构和 Scrapy 代码是完全一致的。  生成代码之后,我们只需要像上述流程一样,把项目进行部署、启动就好了,不需要我们写任何一行代码,即可完成爬虫的编写、部署、控制、监测。
生成代码之后,我们只需要像上述流程一样,把项目进行部署、启动就好了,不需要我们写任何一行代码,即可完成爬虫的编写、部署、控制、监测。 在上图网络结构中,对于矩形块 A 的那部分,通过输入xt(t时刻的特征向量),它会输出一个结果ht(t时刻的状态或者输出)。网络中的循环结构使得某个时刻的状态能够传到下一个时刻。 这些循环的结构让 RNNs 看起来有些难以理解,但我们可以把 RNNs 看成是一个普通的网络做了多次复制后叠加在一起组成的,每一网络会把它的输出传递到下一个网络中。我们可以把 RNNs 在时间步上进行展开,就得到下图这样:
在上图网络结构中,对于矩形块 A 的那部分,通过输入xt(t时刻的特征向量),它会输出一个结果ht(t时刻的状态或者输出)。网络中的循环结构使得某个时刻的状态能够传到下一个时刻。 这些循环的结构让 RNNs 看起来有些难以理解,但我们可以把 RNNs 看成是一个普通的网络做了多次复制后叠加在一起组成的,每一网络会把它的输出传递到下一个网络中。我们可以把 RNNs 在时间步上进行展开,就得到下图这样:  所以最基本的 RNN Cell 输入就是 xt,它还会输出一个隐含内容传递到下一个 Cell,同时还会生成一个结果 ht,其最基本的结构如如下:
所以最基本的 RNN Cell 输入就是 xt,它还会输出一个隐含内容传递到下一个 Cell,同时还会生成一个结果 ht,其最基本的结构如如下:  仅仅是输入的 xt 和隐藏状态进行 concat,然后经过线性变换后经过一个 tanh 激活函数便输出了,另外隐含内容和输出结果是相同的内容。 我们来分析一下 TensorFlow 里面 RNN Cell 的实现。 TensorFlow 实现 RNN Cell 的位置在 python/ops/rnncellimpl.py,首先其实现了一个 RNNCell 类,继承了 Layer 类,其内部有三个比较重要的方法,state_size()、output_size()、__call() 方法,其中 state_size() 和 output_size() 方法设置为类属性,可以当做属性来调用,实现如下:
仅仅是输入的 xt 和隐藏状态进行 concat,然后经过线性变换后经过一个 tanh 激活函数便输出了,另外隐含内容和输出结果是相同的内容。 我们来分析一下 TensorFlow 里面 RNN Cell 的实现。 TensorFlow 实现 RNN Cell 的位置在 python/ops/rnncellimpl.py,首先其实现了一个 RNNCell 类,继承了 Layer 类,其内部有三个比较重要的方法,state_size()、output_size()、__call() 方法,其中 state_size() 和 output_size() 方法设置为类属性,可以当做属性来调用,实现如下: 但是如果我们想依赖前文距离非常远的信息时,普通的 RNN 就非常难以做到了,随着间隔信息的增大,RNN 难以对其做关联:
但是如果我们想依赖前文距离非常远的信息时,普通的 RNN 就非常难以做到了,随着间隔信息的增大,RNN 难以对其做关联:  但是 LSTM 可以用来解决这个问题。 LSTM,Long Short Term Memory Networks,是 RNN 的一个变种,经试验它可以用来解决更多问题,并取得了非常好的效果。 LSTM Cell 的结构如下:
但是 LSTM 可以用来解决这个问题。 LSTM,Long Short Term Memory Networks,是 RNN 的一个变种,经试验它可以用来解决更多问题,并取得了非常好的效果。 LSTM Cell 的结构如下:  LSTMs 最关键的地方在于 Cell 的状态 和 结构图上面的那条横穿的水平线。 Cell 状态的传输就像一条传送带,向量从整个 Cell 中穿过,只是做了少量的线性操作。这种结构能够很轻松地实现信息从整个 Cell 中穿过而不做改变。
LSTMs 最关键的地方在于 Cell 的状态 和 结构图上面的那条横穿的水平线。 Cell 状态的传输就像一条传送带,向量从整个 Cell 中穿过,只是做了少量的线性操作。这种结构能够很轻松地实现信息从整个 Cell 中穿过而不做改变。  若只有上面的那条水平线是没办法实现添加或者删除信息的,信息的操作是是通过一种叫做门的结构来实现的。 这里我们可以把门分为三个:遗忘门(Forget Gate)、传入门(Input Gate)、输出门(Output Gate)。
若只有上面的那条水平线是没办法实现添加或者删除信息的,信息的操作是是通过一种叫做门的结构来实现的。 这里我们可以把门分为三个:遗忘门(Forget Gate)、传入门(Input Gate)、输出门(Output Gate)。
 在经过 Forget Gate 和 Input Gate 处理后,我们就可以对输入的 Ct-1 做更新了,即把Ct−1 更新为 Ct,首先我们把旧的状态 Ct−1 和 ft 相乘, 把一些不想保留的信息忘掉。然后加上 it∗Ct~,这部分信息就是我们要添加的新内容,这样就可以完成对 Ct-1 的更新。
在经过 Forget Gate 和 Input Gate 处理后,我们就可以对输入的 Ct-1 做更新了,即把Ct−1 更新为 Ct,首先我们把旧的状态 Ct−1 和 ft 相乘, 把一些不想保留的信息忘掉。然后加上 it∗Ct~,这部分信息就是我们要添加的新内容,这样就可以完成对 Ct-1 的更新。 
 到了最后,其输出结果有三个内容,其中输出结果就是最上面的箭头代指的内容,即最终计算的结果,隐层包括两部分内容,一个是 Ct,一个是最下方的 ht,我们可以将其合并为一个变量来表示。 接下来我们来看下 LSTMCell 的 TensorFlow 代码实现。 首先它的类是 BasicLSTMCell 类,继承了 RNNCell 类,其初始化方法 init() 实现如下:
到了最后,其输出结果有三个内容,其中输出结果就是最上面的箭头代指的内容,即最终计算的结果,隐层包括两部分内容,一个是 Ct,一个是最下方的 ht,我们可以将其合并为一个变量来表示。 接下来我们来看下 LSTMCell 的 TensorFlow 代码实现。 首先它的类是 BasicLSTMCell 类,继承了 RNNCell 类,其初始化方法 init() 实现如下: 另外还有一个变种就是将 Forget Gate 和 Input Gate 二者联合起来,做到要么遗忘老的输入新的,要么保留老的不输入新的。
另外还有一个变种就是将 Forget Gate 和 Input Gate 二者联合起来,做到要么遗忘老的输入新的,要么保留老的不输入新的。  但接下来还有一个更常用的变种,俺就是 GRU,它是由 Cho, et al. (2014) 提出的,在提出的同时他还提出了 Seq2Seq 模型,为 Generation Model 做好了铺垫。
但接下来还有一个更常用的变种,俺就是 GRU,它是由 Cho, et al. (2014) 提出的,在提出的同时他还提出了 Seq2Seq 模型,为 Generation Model 做好了铺垫。 接下来我们看下 TensorFlow 中 GRUCell 的实现,代码如下:
接下来我们看下 TensorFlow 中 GRUCell 的实现,代码如下: 数据集中包含了图片和对应的标注,在 TensorFlow 中提供了这个数据集,我们可以用如下方法进行导入:
数据集中包含了图片和对应的标注,在 TensorFlow 中提供了这个数据集,我们可以用如下方法进行导入: 正如前面提到的一样,每一个 MNIST 数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。我们把这些图片设为 xs,把这些标签设为 ys。训练数据集和测试数据集都包含 xs 和 ys,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels,每张图片是 28 x 28 像素,即 784 个像素点,我们可以把它展开形成一个向量,即长度为 784 的向量。 所以训练集我们可以转化为 [55000, 784] 的向量,第一维就是训练集中包含的图片个数,第二维是图片的像素点表示的向量。
正如前面提到的一样,每一个 MNIST 数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。我们把这些图片设为 xs,把这些标签设为 ys。训练数据集和测试数据集都包含 xs 和 ys,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels,每张图片是 28 x 28 像素,即 784 个像素点,我们可以把它展开形成一个向量,即长度为 784 的向量。 所以训练集我们可以转化为 [55000, 784] 的向量,第一维就是训练集中包含的图片个数,第二维是图片的像素点表示的向量。 展开等式右边的子式,可以得到:
展开等式右边的子式,可以得到:  比如判断一张图片中的动物是什么,可能的结果有三种,猫、狗、鸡,假如我们可以经过计算得出它们分别的得分为 3.2、5.1、-1.7,Softmax 的过程首先会对各个值进行次幂计算,分别为 24.5、164.0、0.18,然后计算各个次幂结果占总次幂结果的比重,这样就可以得到 0.13、0.87、0.00 这三个数值,所以这样我们就可以实现差别的放缩,即好的更好、差的更差。 如果要进一步求损失值可以进一步求对数然后取负值,这样 Softmax 后的值如果值越接近 1,那么得到的值越小,即损失越小,如果越远离 1,那么得到的值越大。
比如判断一张图片中的动物是什么,可能的结果有三种,猫、狗、鸡,假如我们可以经过计算得出它们分别的得分为 3.2、5.1、-1.7,Softmax 的过程首先会对各个值进行次幂计算,分别为 24.5、164.0、0.18,然后计算各个次幂结果占总次幂结果的比重,这样就可以得到 0.13、0.87、0.00 这三个数值,所以这样我们就可以实现差别的放缩,即好的更好、差的更差。 如果要进一步求损失值可以进一步求对数然后取负值,这样 Softmax 后的值如果值越接近 1,那么得到的值越小,即损失越小,如果越远离 1,那么得到的值越大。 这里实际上是对输入的 x 乘以 w 权重,然后加上一个偏置项作为输出,而这两个变量实际是在训练的过程中动态调优的,所以我们需要指定它们的类型为 Variable,代码如下:
这里实际上是对输入的 x 乘以 w 权重,然后加上一个偏置项作为输出,而这两个变量实际是在训练的过程中动态调优的,所以我们需要指定它们的类型为 Variable,代码如下: y 是我们预测的概率分布, y_label 是实际的分布,比较粗糙的理解是,交叉熵是用来衡量我们的预测用于描述真相的低效性。 我们可以首先定义 y_label,它的表达式是:
y 是我们预测的概率分布, y_label 是实际的分布,比较粗糙的理解是,交叉熵是用来衡量我们的预测用于描述真相的低效性。 我们可以首先定义 y_label,它的表达式是:










 另外我们也可以单独添加单个 Node 或 Relationship,实例如下:
另外我们也可以单独添加单个 Node 或 Relationship,实例如下: 另外还可以利用 data() 方法来获取查询结果:
另外还可以利用 data() 方法来获取查询结果: 在这里我们用 NodeSelector 来筛选 age 为 21 的 Person Node,实例如下:
在这里我们用 NodeSelector 来筛选 age 为 21 的 Person Node,实例如下:

























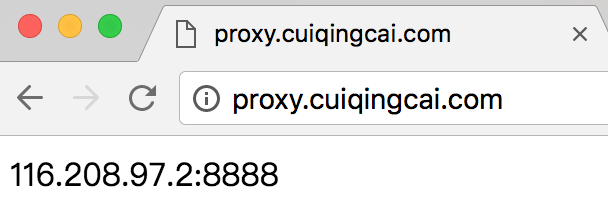
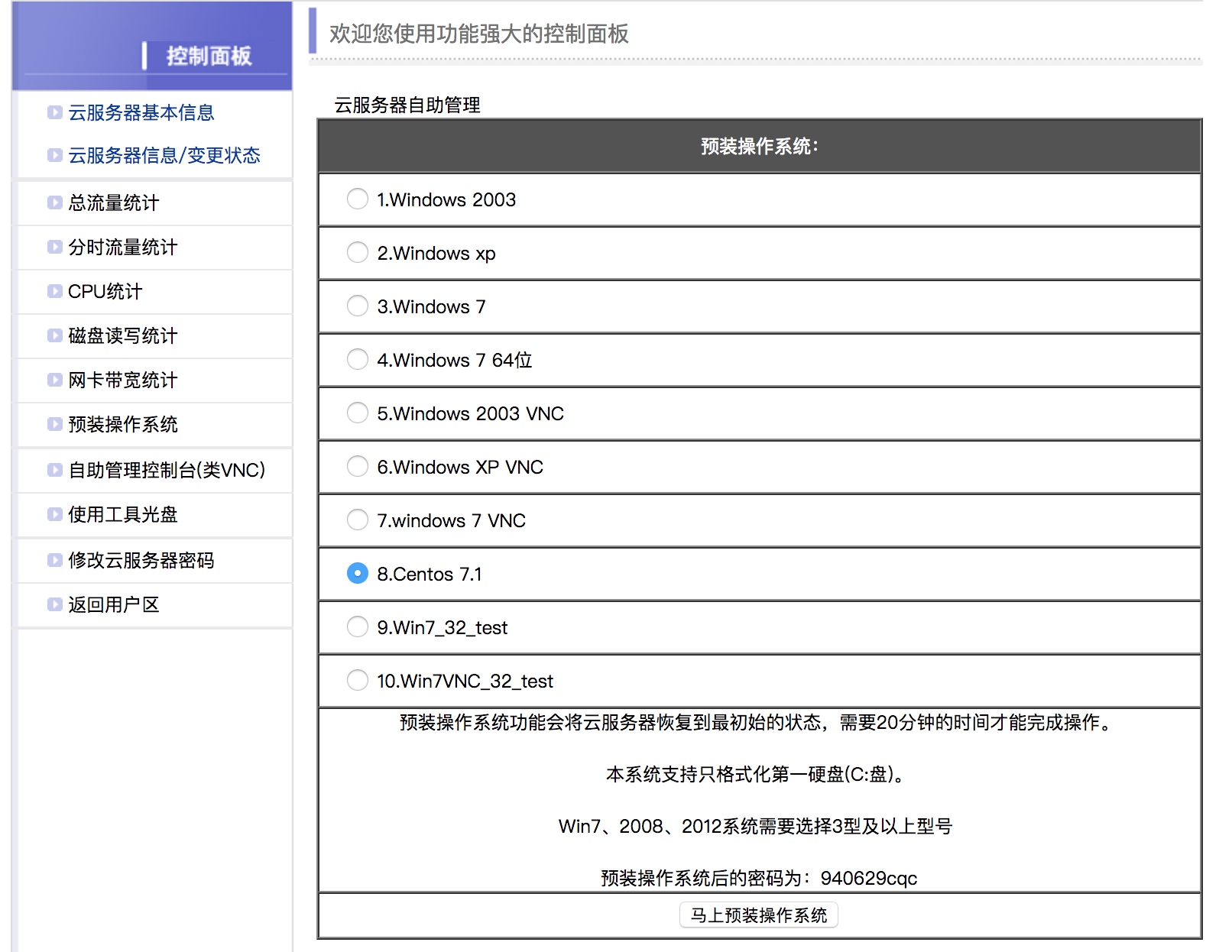 在这里推荐安装CentOS7系统。 然后找到远程管理面板找到远程连接的用户名和密码,也就是SSH远程连接服务器的信息。 比如我这边的IP端口分别是 153.36.65.214:20063,用户名是root。 命令行下输入:
在这里推荐安装CentOS7系统。 然后找到远程管理面板找到远程连接的用户名和密码,也就是SSH远程连接服务器的信息。 比如我这边的IP端口分别是 153.36.65.214:20063,用户名是root。 命令行下输入: 都提示成功之后就可以进行拨号了。 在拨号之前如果我们测试ping任何网站都是不通的,因为当前网络还没联通,输入拨号命令:
都提示成功之后就可以进行拨号了。 在拨号之前如果我们测试ping任何网站都是不通的,因为当前网络还没联通,输入拨号命令: 所以断线重播的命令就是二者组合起来,先执行
所以断线重播的命令就是二者组合起来,先执行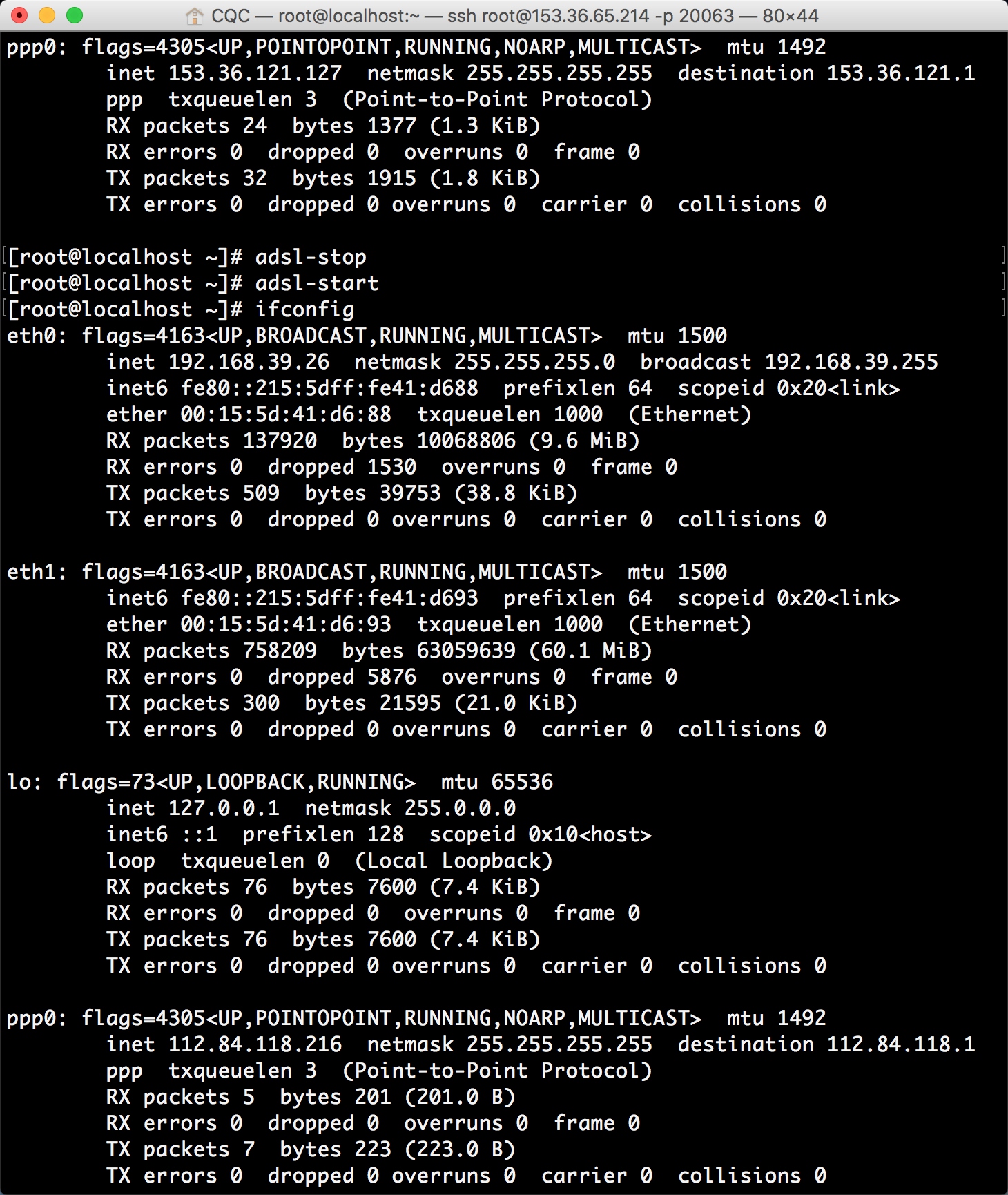 所以,到这里我们就可以知道它作为代理服务器的巨大优势了,如果将这台主机作为代理服务器,如果我们一直拨号换IP,就不怕遇到IP被封的情况了,即使某个IP被封了,重新拨一次号就好了。 所以接下来我们要做的就有两件事,一是怎样将主机设置为代理服务器,二是怎样实时获取拨号主机的IP。
所以,到这里我们就可以知道它作为代理服务器的巨大优势了,如果将这台主机作为代理服务器,如果我们一直拨号换IP,就不怕遇到IP被封的情况了,即使某个IP被封了,重新拨一次号就好了。 所以接下来我们要做的就有两件事,一是怎样将主机设置为代理服务器,二是怎样实时获取拨号主机的IP。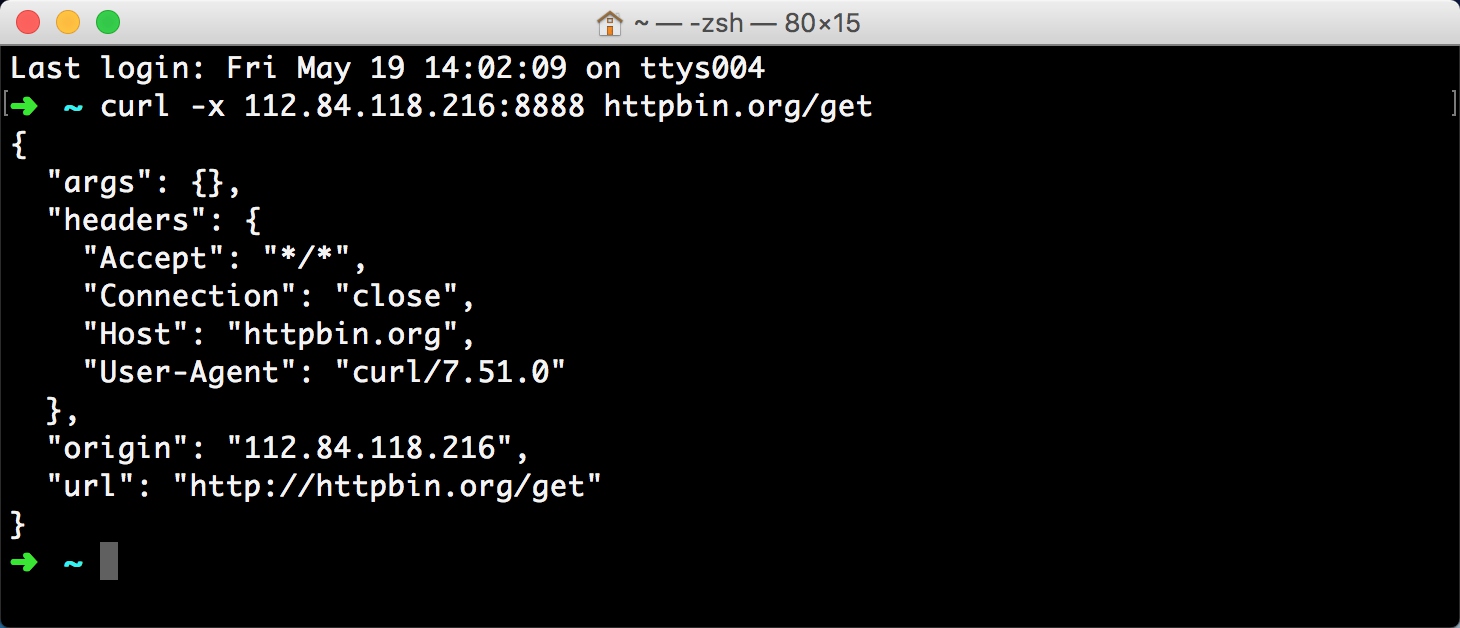 如果有正常的结果输出并且origin的值为代理IP的地址,就证明TinyProxy配置成功了。 好,那到现在,我们接下来要做的就是需要动态实时获取主机的IP了。
如果有正常的结果输出并且origin的值为代理IP的地址,就证明TinyProxy配置成功了。 好,那到现在,我们接下来要做的就是需要动态实时获取主机的IP了。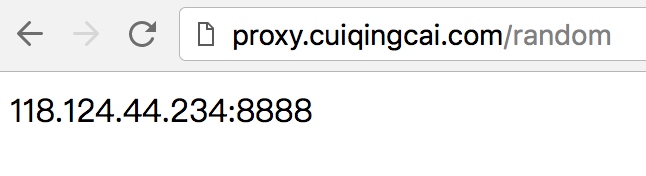 获取最新代理:
获取最新代理:  获取所有代理:
获取所有代理: 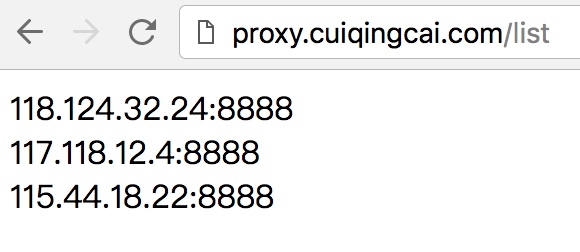 请求接口获取可用代理即可,比如获取一个随机代理:
请求接口获取可用代理即可,比如获取一个随机代理:















 我们可以看到这里就是他的一些基本信息,我们需要抓取的就是这些,比如名字、签名、职业、关注数、赞同数等等。 接下来我们需要探索一下关注列表接口在哪里,我们点击关注选项卡,然后下拉,点击翻页,我们会在下面的请求中发现出现了 followees开头的Ajax请求。这个就是获取关注列表的接口。
我们可以看到这里就是他的一些基本信息,我们需要抓取的就是这些,比如名字、签名、职业、关注数、赞同数等等。 接下来我们需要探索一下关注列表接口在哪里,我们点击关注选项卡,然后下拉,点击翻页,我们会在下面的请求中发现出现了 followees开头的Ajax请求。这个就是获取关注列表的接口。  我们观察一下这个请求结构
我们观察一下这个请求结构  首先它是一个Get类型的请求,请求的URL是
首先它是一个Get类型的请求,请求的URL是 可以看到有data和paging两个字段,data就是数据,包含20个内容,这些就是用户的基本信息,也就是关注列表的用户信息。 paging里面又有几个字段,is_end表示当前翻页是否结束,next是下一页的链接,所以在判读分页的时候,我们可以先利用is_end判断翻页是否结束,然后再获取next链接,请求下一页。 这样我们的关注列表就可以通过接口获取到了。 接下来我们再看下用户详情接口在哪里,我们将鼠标放到关注列表任意一个头像上面,观察下网络请求,可以发现又会出现一个Ajax请求。
可以看到有data和paging两个字段,data就是数据,包含20个内容,这些就是用户的基本信息,也就是关注列表的用户信息。 paging里面又有几个字段,is_end表示当前翻页是否结束,next是下一页的链接,所以在判读分页的时候,我们可以先利用is_end判断翻页是否结束,然后再获取next链接,请求下一页。 这样我们的关注列表就可以通过接口获取到了。 接下来我们再看下用户详情接口在哪里,我们将鼠标放到关注列表任意一个头像上面,观察下网络请求,可以发现又会出现一个Ajax请求。  可以看到这次的请求链接为
可以看到这次的请求链接为 所以综上所述:
所以综上所述:
 可以看到返回的结果非常全,在这里我们直接声明一个Item全保存下就好了。 在items里新声明一个UserItem
可以看到返回的结果非常全,在这里我们直接声明一个Item全保存下就好了。 在items里新声明一个UserItem 看下MongoDB,里面我们爬取的用户详情结果。
看下MongoDB,里面我们爬取的用户详情结果。  到现在为止,整个爬虫就基本完结了,我们主要通过递归的方式实现了这个逻辑。存储结果也通过适当的方法实现了去重。
到现在为止,整个爬虫就基本完结了,我们主要通过递归的方式实现了这个逻辑。存储结果也通过适当的方法实现了去重。