上市了!")



MiGu 登录参数分析
目标:分析咪咕视频登录参数(enpassword、fingerPrint、fingerPrintDetail)
工具:NodeJs + Chrome 开发者工具
许久没有水文了,闲来无事特来混混脸熟 源码在此,欢迎白嫖,star 就更好啦
enpassword
找到登录入口:
查找方式:
点击登录 —> 开启 chrome 开发者工具 -> 重载框架 —> 抓到登录包 如下: 
加密参数寻找
清空之后,使用错误的账号密码登录。一共两个包两张图片。图片开源不看,具体看包,最后在 authn 包中看到了我们登录所加密过的三个参数,如下 
海里捞针-找参数
在搜索框(ctrl + shift + F )下搜索 enpassword 参数,进入 source File 发现 link 93,name 并未加密;那么就是在它的 class 属性 J_RsaPsd 中。再次找! 
海里捞针-找参数、埋断点
找到三个 J_RsaPsd,每个都上断点,然后在点登录一下  encrypt:加密函数,b.val 加密对象(输入的密码)
encrypt:加密函数,b.val 加密对象(输入的密码)  将其扣出来! 为什么扣这里?因为这里为加密处!由明文转为密文。那我们拿到这些就以为着拿到了加密的函数。就可以自己实现加密
将其扣出来! 为什么扣这里?因为这里为加密处!由明文转为密文。那我们拿到这些就以为着拿到了加密的函数。就可以自己实现加密
c = new p.RSAKey; c.setPublic(a.result.modulus, a.result.publicExponent); var d = c.encrypt(b.val());
该写如下:(js 丫)
1 |
function getPwd(pwd) { |
虽然我们加密的函数已经找到了,but,我们是在自己的环境下并不一定有这个函数(c.encrypt)。所以现在需要去找 c.encrypt  新问题:p.RSAKey;没有定义;回到 chrome 进入 p.RSAKey-(选中点击进入 f db())
新问题:p.RSAKey;没有定义;回到 chrome 进入 p.RSAKey-(选中点击进入 f db())  进入 f db()扣出这个方法,然后改写 寻找 a.result.modulus, a.result.publicExponent 两个参数, 其实是 publickey 包返回的结果那么至此enpassword加密完成 补两个环境参数
进入 f db()扣出这个方法,然后改写 寻找 a.result.modulus, a.result.publicExponent 两个参数, 其实是 publickey 包返回的结果那么至此enpassword加密完成 补两个环境参数
1 |
window = this; |

fingerPrint、fingerPrintDetail参数破解
 link480 下断点点击下一步,运行 运行一步, 进入RSAfingerPrint函数内,把 o.page.RSAfingerPrint 方法抠出来 在页面中观察 a,b 参数
link480 下断点点击下一步,运行 运行一步, 进入RSAfingerPrint函数内,把 o.page.RSAfingerPrint 方法抠出来 在页面中观察 a,b 参数  观察发现: 其实 a,b,就是我们的a.result.modulus, a.result.publicExponent,
观察发现: 其实 a,b,就是我们的a.result.modulus, a.result.publicExponent,
1 |
rsaFingerprint = function () { |
继续寻找;这两个
1 |
c = $.fingerprint.details |
浏览器里面测一下,把他从 console 拿出来 



 我正在的干货要开始了! 进入我们的 show time 环节,起飞了、起飞了,做好准备了!
我正在的干货要开始了! 进入我们的 show time 环节,起飞了、起飞了,做好准备了! 看到这里面有很多链接,就是一些页面导航集合,这个页面就是列表页。 然后我们随便点开一篇新闻报道,如图所示:
看到这里面有很多链接,就是一些页面导航集合,这个页面就是列表页。 然后我们随便点开一篇新闻报道,如图所示:  这里就是一篇新闻报道,带有醒目的标题、发布时间、正文等内容,这就是详情页。 现在我们要做的就是用一个算法来凭借 HTML 代码区分出来哪个是列表页,哪个是详情页。 最后的输入输出如下:
这里就是一篇新闻报道,带有醒目的标题、发布时间、正文等内容,这就是详情页。 现在我们要做的就是用一个算法来凭借 HTML 代码区分出来哪个是列表页,哪个是详情页。 最后的输入输出如下: 每个文件夹几百个就行了,数量不用太多,五花八门的页面混起来更好。
每个文件夹几百个就行了,数量不用太多,五花八门的页面混起来更好。
 这里我截图下来一张图片,如图所示:
这里我截图下来一张图片,如图所示:  然后我们把这个图片声明成一个 Template 传入,示例如下:
然后我们把这个图片声明成一个 Template 传入,示例如下: 大家可以点击任意一个网站来爬取练习。
大家可以点击任意一个网站来爬取练习。


 上面是一些案例的效果,基本上是使用 Django + Vue.js 开发的,主题使用了红色调,整个案例平台风格比较统一。另外还有一些 App 也是类似的风格,大家可以自行下载体验试试。 当然这里面最主要的还是案例的功能,比如各种加密、反爬、检测等等。
上面是一些案例的效果,基本上是使用 Django + Vue.js 开发的,主题使用了红色调,整个案例平台风格比较统一。另外还有一些 App 也是类似的风格,大家可以自行下载体验试试。 当然这里面最主要的还是案例的功能,比如各种加密、反爬、检测等等。
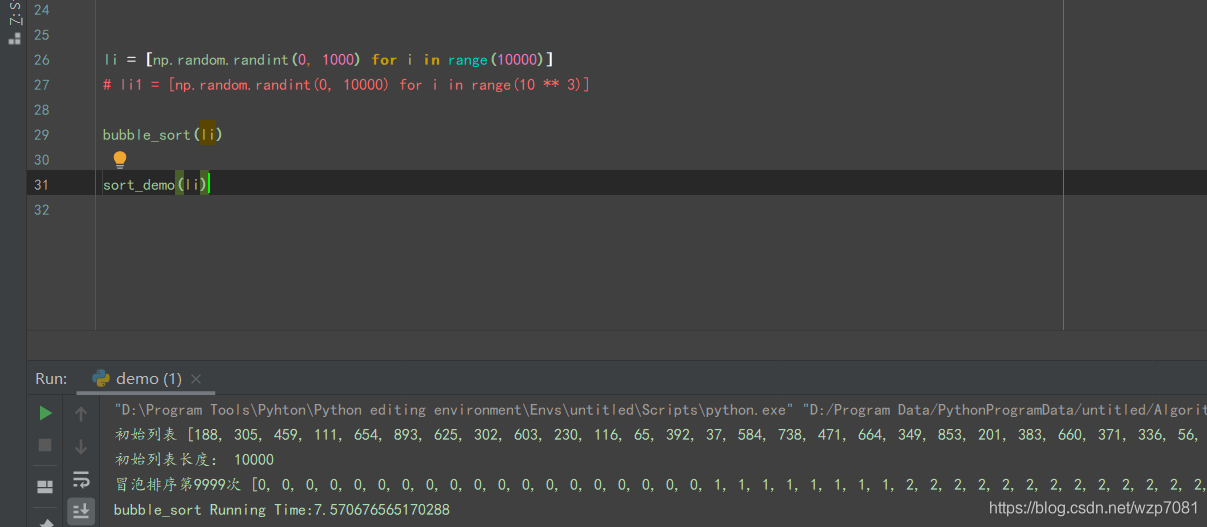 优化: 在一次回头看看冒泡排序具体实现思路,将列表每两个相邻的数,如果前面比后面大,则交换这两个数,一趟排序完成后,则无序区减少一个数,有序区增加一个数。 如果无序区已经是有序的呢?按照代码执行流程可知, 如果前者比后者大,那么则两个交换位置。(假设为降序,前面为无序区,后面为有序区) 否则不执行任何交换操作,但会执行便利(也可以理解为此运算”不执行任何交换操作,无实际意义”) 优化目标:(将“不执行任何交换的操作去掉”),咱们在回头看看,具体实际的运算是在第二层for循环里面的,也就说所谓的“无用功”也是在这里产生的 无用功体现为:无论是否进行了位置交换,都会在往有序区在遍历检查一遍 思路如下: 主要优化的地方在跳出循环,在它不交换位置的时候,直接跳出此次的循环 假设它全部都是有序的,并设个标记True, 当如果循环内发生了位置交换,则改变标记为False。 流程控制,if。当if True的时则会执行if内部代码(设立return,或者break)主要跳出循环。避免对有序区进行有一次的排序操作 具体代码实现如下:
优化: 在一次回头看看冒泡排序具体实现思路,将列表每两个相邻的数,如果前面比后面大,则交换这两个数,一趟排序完成后,则无序区减少一个数,有序区增加一个数。 如果无序区已经是有序的呢?按照代码执行流程可知, 如果前者比后者大,那么则两个交换位置。(假设为降序,前面为无序区,后面为有序区) 否则不执行任何交换操作,但会执行便利(也可以理解为此运算”不执行任何交换操作,无实际意义”) 优化目标:(将“不执行任何交换的操作去掉”),咱们在回头看看,具体实际的运算是在第二层for循环里面的,也就说所谓的“无用功”也是在这里产生的 无用功体现为:无论是否进行了位置交换,都会在往有序区在遍历检查一遍 思路如下: 主要优化的地方在跳出循环,在它不交换位置的时候,直接跳出此次的循环 假设它全部都是有序的,并设个标记True, 当如果循环内发生了位置交换,则改变标记为False。 流程控制,if。当if True的时则会执行if内部代码(设立return,或者break)主要跳出循环。避免对有序区进行有一次的排序操作 具体代码实现如下:

 需求如下:累计求和 1-n 的值(1. 为防止误差,验证 10 次; 2. 验证每次计算次数)
需求如下:累计求和 1-n 的值(1. 为防止误差,验证 10 次; 2. 验证每次计算次数) 任意点开一篇新闻,看到的结果如下:
任意点开一篇新闻,看到的结果如下:  我现在需要做到的是在不编写任何 XPath、Selector 的情况下实现下面信息的提取: 对于列表页来说,我要提取新闻的所有标题列表和对应的链接,它们就是图中的红色区域:
我现在需要做到的是在不编写任何 XPath、Selector 的情况下实现下面信息的提取: 对于列表页来说,我要提取新闻的所有标题列表和对应的链接,它们就是图中的红色区域:  这里红色区域分了多个区块,比如这里一共就是 40 个链接,我都需要提取出来,包括标题的名称,标题的 URL。 我们看到页面里面还有很多无用的链接,如上图绿色区域,包括分类、内部导航等,这些需要排除掉。 对于详情页,我主要关心的内容有标题、发布时间、正文内容,它们就是图中红色区域:
这里红色区域分了多个区块,比如这里一共就是 40 个链接,我都需要提取出来,包括标题的名称,标题的 URL。 我们看到页面里面还有很多无用的链接,如上图绿色区域,包括分类、内部导航等,这些需要排除掉。 对于详情页,我主要关心的内容有标题、发布时间、正文内容,它们就是图中红色区域:  其中这里也带有一些干扰项,比如绿色区域的侧边栏的内容,无用的分享链接等。 总之,我想实现某种算法,实现如上两大部分的智能化提取。
其中这里也带有一些干扰项,比如绿色区域的侧边栏的内容,无用的分享链接等。 总之,我想实现某种算法,实现如上两大部分的智能化提取。 然后编写提取代码如下:
然后编写提取代码如下: 编写测试代码如下:
编写测试代码如下:

 后面会有大规模测试和修正。 项目初版,肯定存在很多不足,希望大家可以多发 Issue 和提 PR。 另外这里建立了一个 Gerapy 开发交流群,之前在 QQ 群的也欢迎加入,以后交流就在微信群了,大家在使用过程遇到关于 Gerapy、Gerapy Auto Extractor 的问题欢迎交流。 这里放一个临时二维码,后期可能会失效,失效后大家可以到公众号「进击的 Coder」获取加群方式。
后面会有大规模测试和修正。 项目初版,肯定存在很多不足,希望大家可以多发 Issue 和提 PR。 另外这里建立了一个 Gerapy 开发交流群,之前在 QQ 群的也欢迎加入,以后交流就在微信群了,大家在使用过程遇到关于 Gerapy、Gerapy Auto Extractor 的问题欢迎交流。 这里放一个临时二维码,后期可能会失效,失效后大家可以到公众号「进击的 Coder」获取加群方式。 

 上面这行标题,没什么用,又这么难看。 我把偏好设置里面的显示内容都去掉了,设置如下:
上面这行标题,没什么用,又这么难看。 我把偏好设置里面的显示内容都去掉了,设置如下:  但是它总是还显示了一个标题,显示成这个样子:
但是它总是还显示了一个标题,显示成这个样子:  上面这个标题看得很难受,我想把它改成无任何内容,简洁清爽,如下图所示:
上面这个标题看得很难受,我想把它改成无任何内容,简洁清爽,如下图所示:  但是现在无论我怎么改偏好设置都不行,总会带上那些信息。 后来搜索了一番发现是 zsh 的问题。 打开
但是现在无论我怎么改偏好设置都不行,总会带上那些信息。 后来搜索了一番发现是 zsh 的问题。 打开  另外注意这里标题处不能完全为空,需要打上一个空格,否则窗口上方会显示「终端」二字。 最后在
另外注意这里标题处不能完全为空,需要打上一个空格,否则窗口上方会显示「终端」二字。 最后在  完毕。
完毕。










 如果没有加入团队是没有权限向所相关的库进行推送的!!! 如何设置(获得)权限呢?(在仓库中点击设置选项进入如下界面)
如果没有加入团队是没有权限向所相关的库进行推送的!!! 如何设置(获得)权限呢?(在仓库中点击设置选项进入如下界面) 
 完成以上操作之后在进行推送即可有权限完成推送。
完成以上操作之后在进行推送即可有权限完成推送。




 具体的流程可以参考上面的流程图:首先是 fork 一个仓库,然后拉去请求 后 clone 到本地,然后编辑更改。后推送到远程仓库(这里的克隆操作就省略了,具体的可以看上面)
具体的流程可以参考上面的流程图:首先是 fork 一个仓库,然后拉去请求 后 clone 到本地,然后编辑更改。后推送到远程仓库(这里的克隆操作就省略了,具体的可以看上面) 

 发送即可完成。 然后接收者根据流程图步骤 6 开始操作即可
发送即可完成。 然后接收者根据流程图步骤 6 开始操作即可 步骤如下:
步骤如下:





 版本前进
版本前进 




 系统用户级别的 config 是在系统目录下,如果不想太麻烦的去找直接 cat ~/.git config 即可
系统用户级别的 config 是在系统目录下,如果不想太麻烦的去找直接 cat ~/.git config 即可
 选择相对应的版本下载即可,下载完成后打开相对应的安装执行,有选项的选择的建议点击第一个默认配置,就不在此过多赘述啦。
选择相对应的版本下载即可,下载完成后打开相对应的安装执行,有选项的选择的建议点击第一个默认配置,就不在此过多赘述啦。 以上的网页地址为:
以上的网页地址为:  Ubuntu:
Ubuntu:



 经过一系列测试发现,其实际需操作的 URL 为
经过一系列测试发现,其实际需操作的 URL 为  基本网站的分析就分析完毕了 注意此处为 POST 请求!!!
基本网站的分析就分析完毕了 注意此处为 POST 请求!!!
 仔细经过上述步骤即可进入本次加密的源码详情页
仔细经过上述步骤即可进入本次加密的源码详情页 
 搜索 sign 参数,得知本页面有 15 个 sign,筛选排查过后可得知以下位置为 sign 等参数,赋值加密过程 为什么会大概确定是此处呢? 理由一:var 声明赋值 理由二:md5() 为什么深信此处呢?
搜索 sign 参数,得知本页面有 15 个 sign,筛选排查过后可得知以下位置为 sign 等参数,赋值加密过程 为什么会大概确定是此处呢? 理由一:var 声明赋值 理由二:md5() 为什么深信此处呢?
 根据其语法可知,Javascript
根据其语法可知,Javascript










 这里一些接口的名称和 URL 我就打码了,这里我可以在 Grafana 中每时每刻都看到每个接口的可用率、响应(包括平均、最快、最慢)时间、状态码等信息,这些信息就是 JMeter 定时检测得到的结果,监控数据转到 Prometheus 里面然后经过 Grafana 可视化出来,并能通过一些指标来实现报警机制。 感兴趣的话,可以继续往下看哈。 为了达成这些功能,我需要解决如下问题:
这里一些接口的名称和 URL 我就打码了,这里我可以在 Grafana 中每时每刻都看到每个接口的可用率、响应(包括平均、最快、最慢)时间、状态码等信息,这些信息就是 JMeter 定时检测得到的结果,监控数据转到 Prometheus 里面然后经过 Grafana 可视化出来,并能通过一些指标来实现报警机制。 感兴趣的话,可以继续往下看哈。 为了达成这些功能,我需要解决如下问题: 这里提示几点可能用到的东西:
这里提示几点可能用到的东西: 这里字段名如 jsr223_rt_as_summary 可以自行修改,比如这里我就统一修改为了 jmeter_test_xxx 这样的字段。 配置完成之后,运行 JMeter 之后,我们就能在
这里字段名如 jsr223_rt_as_summary 可以自行修改,比如这里我就统一修改为了 jmeter_test_xxx 这样的字段。 配置完成之后,运行 JMeter 之后,我们就能在  这里面就包含了 JMeter 的一些接口测试结果,包括成功次数、失败次数、状态码等等,另外还有 JVM、处理器等各种环境信息。 部署之后把对应的 URL 交由 Prometheus 就可以把监控数据收集到 Prometheus 里面了。
这里面就包含了 JMeter 的一些接口测试结果,包括成功次数、失败次数、状态码等等,另外还有 JVM、处理器等各种环境信息。 部署之后把对应的 URL 交由 Prometheus 就可以把监控数据收集到 Prometheus 里面了。 这里就能实时可视化展示出来错误率了,更多的一些配置可以自行修改这些表达式进行定制。 最后我配置成的一些监控面板如下所示:
这里就能实时可视化展示出来错误率了,更多的一些配置可以自行修改这些表达式进行定制。 最后我配置成的一些监控面板如下所示:  这样我要是什么时候想看 Service 接口的情况,随时上来看就好了。
这样我要是什么时候想看 Service 接口的情况,随时上来看就好了。 不过公司内部已经实现了一套了,对接了公司的员工账号,更加方便,所以我就没有再用这个了。
不过公司内部已经实现了一套了,对接了公司的员工账号,更加方便,所以我就没有再用这个了。 只需要给模型输入一张带缺口的验证码图片,模型就能输出缺口的轮廓和边界信息。 感兴趣的可以继续向下看具体的实现流程。
只需要给模型输入一张带缺口的验证码图片,模型就能输出缺口的轮廓和边界信息。 感兴趣的可以继续向下看具体的实现流程。 标注完了会生成一系列 xml 文件,你需要解析 xml 文件把位置的坐标和类别等处理一下,转成训练模型需要的数据。 在这里我先把我整理的数据集放出来吧,完整 GitHub 链接为:
标注完了会生成一系列 xml 文件,你需要解析 xml 文件把位置的坐标和类别等处理一下,转成训练模型需要的数据。 在这里我先把我整理的数据集放出来吧,完整 GitHub 链接为: val_mAP 变化如下:
val_mAP 变化如下:  可以看到 loss 从最初的非常高下降到了很低,准确率也逐渐接近 100%。 另外训练过程中还能看到如下的输出结果:
可以看到 loss 从最初的非常高下降到了很低,准确率也逐渐接近 100%。 另外训练过程中还能看到如下的输出结果:

 这里我们可以看到,利用训练好的模型我们就成功识别出缺口的位置了,另外程序还会打印输出这个边框的中心点和宽高信息。 有了这个边界信息,我们再利用某些手段拖动滑块即可通过验证了。本节不再展开讲解。
这里我们可以看到,利用训练好的模型我们就成功识别出缺口的位置了,另外程序还会打印输出这个边框的中心点和宽高信息。 有了这个边界信息,我们再利用某些手段拖动滑块即可通过验证了。本节不再展开讲解。








 大家可以看到全站的内容都变成灰色了,包括按钮、图片等等。这时候我们可能会好奇这是怎么做到的呢? 有人会以为所有的内容都统一换了一个 CSS 样式,图片也全换成灰色的了,按钮等样式也统一换成了灰色样式。但你想想这个成本也太高了,而且万一某个控件忘记加灰色样式了岂不是太突兀了。 其实,解决方案很简单,只需要几行代码就能搞定了。
大家可以看到全站的内容都变成灰色了,包括按钮、图片等等。这时候我们可能会好奇这是怎么做到的呢? 有人会以为所有的内容都统一换了一个 CSS 样式,图片也全换成灰色的了,按钮等样式也统一换成了灰色样式。但你想想这个成本也太高了,而且万一某个控件忘记加灰色样式了岂不是太突兀了。 其实,解决方案很简单,只需要几行代码就能搞定了。 其 CSS 内容为:
其 CSS 内容为: 果然是这个样式在起作用,而且是全局的效果,因为它是作用在了 html 这个节点之上的。 另外看看 CSDN,它也是用的这个 CSS 样式,其内容为:
果然是这个样式在起作用,而且是全局的效果,因为它是作用在了 html 这个节点之上的。 另外看看 CSDN,它也是用的这个 CSS 样式,其内容为: 比如这里通过 filter 样式改变了图片、颜色、模糊、对比度等等信息。 其所有用法示例如下:
比如这里通过 filter 样式改变了图片、颜色、模糊、对比度等等信息。 其所有用法示例如下: 再说回刚才的灰色图像,这里其实就是设置了 grayscale,其用法如下:
再说回刚才的灰色图像,这里其实就是设置了 grayscale,其用法如下: 这里我们看到,这里除了 IE,其他的 PC、手机端的浏览器都支持了,Firefox 的 PC、安卓端还单独对 SVG 图像加了支持,可以放心使用。
这里我们看到,这里除了 IE,其他的 PC、手机端的浏览器都支持了,Firefox 的 PC、安卓端还单独对 SVG 图像加了支持,可以放心使用。 接着我们点击 PyCharm 的 Tools -> Deployment -> Configuration,这里我们可以配置远程 SFTP 服务器,如图所示:
接着我们点击 PyCharm 的 Tools -> Deployment -> Configuration,这里我们可以配置远程 SFTP 服务器,如图所示:  打开之后是这样子,这里选择 SFTP,然后填入服务器的连接信息,如图所示:
打开之后是这样子,这里选择 SFTP,然后填入服务器的连接信息,如图所示:  在这里可以点「TEST CONNECTION」测试下是否能够连接成功。 OK,配置完了之后,我们已经成功添加好了一台远程服务器了,比如我这里就添加了一台我自己的服务器,Host 为 vm1.cuiqingcai.com。 既然要实现本地和服务器文件同步,那么当然必须要指定本地项目文件夹和远程哪个文件夹同步吧。在哪里指定呢?切换到第二个选项卡,Mappings,如图所示:
在这里可以点「TEST CONNECTION」测试下是否能够连接成功。 OK,配置完了之后,我们已经成功添加好了一台远程服务器了,比如我这里就添加了一台我自己的服务器,Host 为 vm1.cuiqingcai.com。 既然要实现本地和服务器文件同步,那么当然必须要指定本地项目文件夹和远程哪个文件夹同步吧。在哪里指定呢?切换到第二个选项卡,Mappings,如图所示:  这里我们可以通过选择 LocalPath 和 Deployment Path 分别指定本地和远程的文件夹名称。注意这里后者指的是相对服务器工作目录的路径。 好了,就是这样,基本配置就完成了。如果你还想配置某些路径不同步的话,还可以在第三个选项卡 Excluded Paths 里面配置。 接着,还有一些可以配置的地方,点击 Tools -> Deployment -> Options 我们可以配置更多细节,如图所示:
这里我们可以通过选择 LocalPath 和 Deployment Path 分别指定本地和远程的文件夹名称。注意这里后者指的是相对服务器工作目录的路径。 好了,就是这样,基本配置就完成了。如果你还想配置某些路径不同步的话,还可以在第三个选项卡 Excluded Paths 里面配置。 接着,还有一些可以配置的地方,点击 Tools -> Deployment -> Options 我们可以配置更多细节,如图所示:  比如这里我就配置了下什么时候上传,这里我改成了按 Ctrl + S 保存的时候再上传,这样我可以自由控制上传的时机。 另外这里还需要把自动上传勾选上,如图所示:
比如这里我就配置了下什么时候上传,这里我改成了按 Ctrl + S 保存的时候再上传,这样我可以自由控制上传的时机。 另外这里还需要把自动上传勾选上,如图所示:  好了,整个都配置好啦。
好了,整个都配置好啦。 这样就上传完毕了。 接着我们任意修改一个文件,按保存,即 Ctrl + S,这里就出现了自动上传的日志,提示某个文件被上传成功了。
这样就上传完毕了。 接着我们任意修改一个文件,按保存,即 Ctrl + S,这里就出现了自动上传的日志,提示某个文件被上传成功了。  OK,验证没问题。
OK,验证没问题。 点了之后就会提示选择哪个远程服务器,选了之后,下方 Terminal 就弹出来了,和普通的 SSH Shell 一模一样。
点了之后就会提示选择哪个远程服务器,选了之后,下方 Terminal 就弹出来了,和普通的 SSH Shell 一模一样。  OK,接下来要构建镜像,我只需要运行对应的 docker-compose 命令就好了,速度瞬间就上来了,我再也不用看着龟速的下拉速度而发愁了,而不用担心本地机器的资源消耗了。
OK,接下来要构建镜像,我只需要运行对应的 docker-compose 命令就好了,速度瞬间就上来了,我再也不用看着龟速的下拉速度而发愁了,而不用担心本地机器的资源消耗了。  OK,美滋滋。 构建完了运行之后,直接远程访问就好了。
OK,美滋滋。 构建完了运行之后,直接远程访问就好了。 这些云服务器被用做测试用机、学习用机或者正式生产用机,有些朋友会在上面搭建博客,有些朋友在上面搭建 API。东鸽自己也手握几台服务器:
这些云服务器被用做测试用机、学习用机或者正式生产用机,有些朋友会在上面搭建博客,有些朋友在上面搭建 API。东鸽自己也手握几台服务器:  其中有 3 台用作实际的生产,新书《
其中有 3 台用作实际的生产,新书《 一个普通的生产者消费者模式就诞生了。如果数据业务体量比较大,或者说数据业务的出口比较多,那我可能会借用消息中间件来进行调节。
一个普通的生产者消费者模式就诞生了。如果数据业务体量比较大,或者说数据业务的出口比较多,那我可能会借用消息中间件来进行调节。  为了保证数据的完整性和可用性,我可能会对服务器进行镜像,那么我就需要 2~3 台服务器。假设每台服务器的成本是 300元/年,数据合作业务的收入是 3W/年,那真是四两拨千斤了。 要合理利用资源,让资源为我们生小钱钱! 服务器配置跟具体业务需求有关,用于测试的服务器通常是 1 核 2G 1M;博客和论坛的服务器带宽稍大一些,带宽通常是 3M ;用于数据合作的服务器内存较大,一般需要为 4G~8G; 除了服务器之外,华为云还有很多神奇的业务。我觉得黑科技真的是太多了。
为了保证数据的完整性和可用性,我可能会对服务器进行镜像,那么我就需要 2~3 台服务器。假设每台服务器的成本是 300元/年,数据合作业务的收入是 3W/年,那真是四两拨千斤了。 要合理利用资源,让资源为我们生小钱钱! 服务器配置跟具体业务需求有关,用于测试的服务器通常是 1 核 2G 1M;博客和论坛的服务器带宽稍大一些,带宽通常是 3M ;用于数据合作的服务器内存较大,一般需要为 4G~8G; 除了服务器之外,华为云还有很多神奇的业务。我觉得黑科技真的是太多了。  上次我用华为云的深度学习一体化服务 ModelArts 在线实现了图像深度学习中的图片标注、图片分类预测和模型部署+生成 API,感觉很流畅。
上次我用华为云的深度学习一体化服务 ModelArts 在线实现了图像深度学习中的图片标注、图片分类预测和模型部署+生成 API,感觉很流畅。  鼠标点点点,配置一丢丢参数,也不用自己写代码,也不用弄 Web 框架,唰唰唰地几下,就可以调用了。 崔庆才崔哥用 ModelArts 实现了爬虫工程师常用到的拼图验证码缺口识别 API。
鼠标点点点,配置一丢丢参数,也不用自己写代码,也不用弄 Web 框架,唰唰唰地几下,就可以调用了。 崔庆才崔哥用 ModelArts 实现了爬虫工程师常用到的拼图验证码缺口识别 API。  样本准备了小小几十个,训练完成后的识别准确率很高,这样我们就不用担心缺口位置定位的问题了。
样本准备了小小几十个,训练完成后的识别准确率很高,这样我们就不用担心缺口位置定位的问题了。  服务器数量多,开销自然就大。如无必要,通常我是不会购买服务器的,但每当云服务器厂商有活动时我都会做一些购买计划。例如我今年打算增加数据业务,并且学习架构方面的知识,那我至少得再买 5 台服务器。趁着华为开年采购季活动,购买一台服务器的成本最低 79元/年。除此之外,华为云还有数据库专场活动、域名建站专场活动、云安全专场活动在等着我们,买买买!
服务器数量多,开销自然就大。如无必要,通常我是不会购买服务器的,但每当云服务器厂商有活动时我都会做一些购买计划。例如我今年打算增加数据业务,并且学习架构方面的知识,那我至少得再买 5 台服务器。趁着华为开年采购季活动,购买一台服务器的成本最低 79元/年。除此之外,华为云还有数据库专场活动、域名建站专场活动、云安全专场活动在等着我们,买买买!  大家相识已久,东鸽感谢大家关注和支持,这次华为云开年采购季活动我自掏腰包购买 3 台 1 核 2G 1M 的服务器(1年期)送给各位粉丝。大家扫码即可参与抽奖,到期自动开奖。 参与要求:参与活动时必须转发上方华为云开年采购季海报,领奖时小编会检查的哦。
大家相识已久,东鸽感谢大家关注和支持,这次华为云开年采购季活动我自掏腰包购买 3 台 1 核 2G 1M 的服务器(1年期)送给各位粉丝。大家扫码即可参与抽奖,到期自动开奖。 参与要求:参与活动时必须转发上方华为云开年采购季海报,领奖时小编会检查的哦。 
 「Pocket」这个软件有一个不错的特性,那就是跨平台,我可以在浏览器、Mac、iPhone、iPad 上使用,看到不错的网站,调出插件或者点击「分享到 Pocket」就可以存进去了,这样就解决了多平台同步问题,另外 「Pocket」还能设置一些标签等等,然后每周或定期我再翻出来整理整理。 说实话,我用「Pocket」好几年了,但总觉得一直达不到我心中完美的标准,怎么说呢?下面总结一下:
「Pocket」这个软件有一个不错的特性,那就是跨平台,我可以在浏览器、Mac、iPhone、iPad 上使用,看到不错的网站,调出插件或者点击「分享到 Pocket」就可以存进去了,这样就解决了多平台同步问题,另外 「Pocket」还能设置一些标签等等,然后每周或定期我再翻出来整理整理。 说实话,我用「Pocket」好几年了,但总觉得一直达不到我心中完美的标准,怎么说呢?下面总结一下: 哎,一眼难尽啊,左边浓浓的拟物化风格,右边自作聪明出了个阅读模式,也就是自动提取正文内容,结果把文章格式整的这么乱。
哎,一眼难尽啊,左边浓浓的拟物化风格,右边自作聪明出了个阅读模式,也就是自动提取正文内容,结果把文章格式整的这么乱。 所以说,这软件的界面、操作和功能,只能说我不喜欢。不喜欢就不要将就,我将就了这么久,最后还是要放弃它。
所以说,这软件的界面、操作和功能,只能说我不喜欢。不喜欢就不要将就,我将就了这么久,最后还是要放弃它。 大家可以看视频来感受一下:
大家可以看视频来感受一下: 另外内容还支持各种其他的布局,如列表式:
另外内容还支持各种其他的布局,如列表式:  瀑布流式:
瀑布流式:  舒服了。 说回功能,这里我先分了几个分组,为「网站」、「代码」、「图片」,我估计我用到的最多的肯定是「网站」这个分组,用来存各种链接的,「代码」和「图片」是为了测试它的上传文件和图片功能而加的,可以用来存代码文件和图片。 分组建好之后,我们可以在分组里面添加收藏夹,看图里面每行前面有个小图标的就是一个收藏夹。没错,每个收藏夹都可以自定义它的小图标,这个功能真的是增色不少! 它提供了非常多的小图标,看:
舒服了。 说回功能,这里我先分了几个分组,为「网站」、「代码」、「图片」,我估计我用到的最多的肯定是「网站」这个分组,用来存各种链接的,「代码」和「图片」是为了测试它的上传文件和图片功能而加的,可以用来存代码文件和图片。 分组建好之后,我们可以在分组里面添加收藏夹,看图里面每行前面有个小图标的就是一个收藏夹。没错,每个收藏夹都可以自定义它的小图标,这个功能真的是增色不少! 它提供了非常多的小图标,看:  这个功能,我觉得简直不能更赞!另外这些小图标还可以自己上传,所以你看图里面的 GitHub 图标、Python 图标,都是我从 icons8 上面找到并上传的,毫无违和感! 另外每一个收藏它都会自动生成一张封面图,会自动截取网站当前页面的内容,或者也可以自定义上传图片或者自定义截屏,最后每个收藏项都会变成一张张卡片。 当然添加标签页不在话下。
这个功能,我觉得简直不能更赞!另外这些小图标还可以自己上传,所以你看图里面的 GitHub 图标、Python 图标,都是我从 icons8 上面找到并上传的,毫无违和感! 另外每一个收藏它都会自动生成一张封面图,会自动截取网站当前页面的内容,或者也可以自定义上传图片或者自定义截屏,最后每个收藏项都会变成一张张卡片。 当然添加标签页不在话下。  另外浏览器的插件也做的很精致,提供了 Mini Application 和极简模式,收藏一个页面只需要点一下这个图标就收藏好了。如果是高级版的账号,还支持自动分类。
另外浏览器的插件也做的很精致,提供了 Mini Application 和极简模式,收藏一个页面只需要点一下这个图标就收藏好了。如果是高级版的账号,还支持自动分类。  手机和 iPad 上面的软件我也试了,功能基本类似。怎么保存呢?比如我的 iPhone 上可以把这个软件放到分享的 App 列表里面,这样在浏览器里面点击「分享」,然后选「Raindrop.io」就好了,它会自动弹出一个窗口,让我们选择分类或加标签,体验很不错。
手机和 iPad 上面的软件我也试了,功能基本类似。怎么保存呢?比如我的 iPhone 上可以把这个软件放到分享的 App 列表里面,这样在浏览器里面点击「分享」,然后选「Raindrop.io」就好了,它会自动弹出一个窗口,让我们选择分类或加标签,体验很不错。  嗯,总之整体体验下来,非常好用。 另外它还支持自动导入书签或从其他的收藏软件里面迁移,大家如果一些网站保存在书签里面的话,如果用了这个,可以快速导入进来,非常方便!
嗯,总之整体体验下来,非常好用。 另外它还支持自动导入书签或从其他的收藏软件里面迁移,大家如果一些网站保存在书签里面的话,如果用了这个,可以快速导入进来,非常方便!  另外还有一些高级的功能大家再探索吧。怎么感觉越写越像个广告文了,但确实这不是广告文,它确实很好用,在这强推给大家!希望它能帮助大家方便管理各种资源,什么博客、公众号、干货、微博、图片、文件统统可以保存到这里并明确清晰地归类啦!
另外还有一些高级的功能大家再探索吧。怎么感觉越写越像个广告文了,但确实这不是广告文,它确实很好用,在这强推给大家!希望它能帮助大家方便管理各种资源,什么博客、公众号、干货、微博、图片、文件统统可以保存到这里并明确清晰地归类啦!