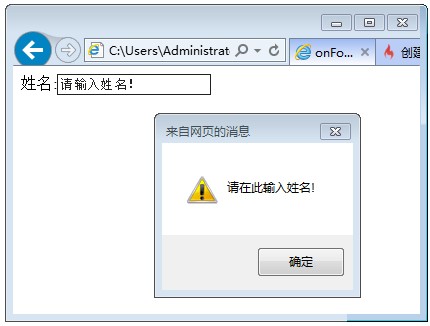
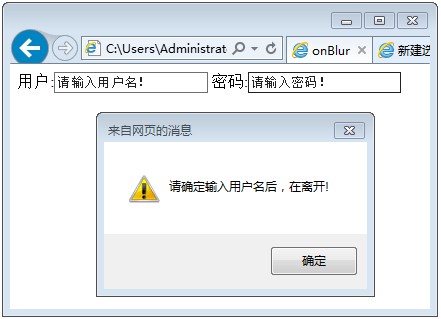
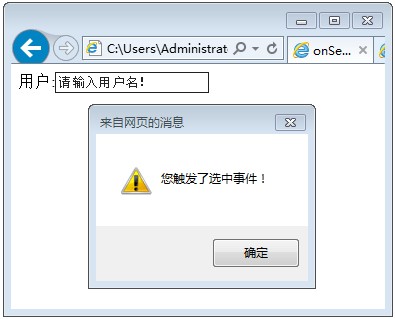
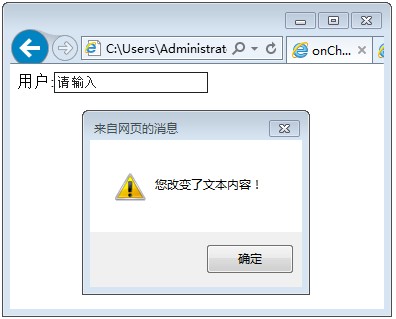
新建一个Dynamic Web Project项目 点下一步,我取名为test,服务器选刚才创建的tomcat6.0,然后下一步,下一步,直到完成就好了 在webcontent目录下面新建一个jsp文件,我的叫a.jsp 我在body区输入了My First Jsp 右击该文件,在服务器上运行,选择tomcat,然后结果如图所示。恭喜你,所有配置都成功啦! 点选eclipse的窗口,然后web浏览器,选default system web browser,即系统默认浏览器,就可以用自己的浏览器打开界面啦。如图所示
html = """ <html><head><title>The Dormouse's story</title></head> <body> <pclass="title"name="dromouse"><b>The Dormouse's story</b></p> <pclass="story">Once upon a time there were three little sisters; and their names were <ahref="http://example.com/elsie"class="sister"id="link1"><!-- Elsie --></a>, <ahref="http://example.com/lacie"class="sister"id="link2">Lacie</a> and <ahref="http://example.com/tillie"class="sister"id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <pclass="story">...</p> """
<html> <head> <title> The Dormouse's story </title> </head> <body> <pclass="title"name="dromouse"> <b> The Dormouse's story </b> </p> <pclass="story"> Once upon a time there were three little sisters; and their names were <aclass="sister"href="http://example.com/elsie"id="link1"> <!-- Elsie --> </a> , <aclass="sister"href="http://example.com/lacie"id="link2"> Lacie </a> and <aclass="sister"href="http://example.com/tillie"id="link3"> Tillie </a> ; and they lived at the bottom of a well. </p> <pclass="story"> ... </p> </body> </html>
<pclass="story">Once upon a time there were three little sisters; and their names were <aclass="sister"href="http://example.com/elsie"id="link1"><!-- Elsie --></a>, <aclass="sister"href="http://example.com/lacie"id="link2">Lacie</a> and <aclass="sister"href="http://example.com/tillie"id="link3">Tillie</a>; and they lived at the bottom of a well.</p>
<html><head><title>The Dormouse's story</title></head> <body> <pclass="title"name="dromouse"><b>The Dormouse's story</b></p> <pclass="story">Once upon a time there were three little sisters; and their names were <aclass="sister"href="http://example.com/elsie"id="link1"><!-- Elsie --></a>, <aclass="sister"href="http://example.com/lacie"id="link2">Lacie</a> and <aclass="sister"href="http://example.com/tillie"id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <pclass="story">...</p> </body></html> <head><title>The Dormouse's story</title></head> <title>The Dormouse's story</title> The Dormouse's story
<body> <pclass="title"name="dromouse"><b>The Dormouse's story</b></p> <pclass="story">Once upon a time there were three little sisters; and their names were <aclass="sister"href="http://example.com/elsie"id="link1"><!-- Elsie --></a>, <aclass="sister"href="http://example.com/lacie"id="link2">Lacie</a> and <aclass="sister"href="http://example.com/tillie"id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <pclass="story">...</p> </body>
<pclass="title"name="dromouse"><b>The Dormouse's story</b></p> <b>The Dormouse's story</b> The Dormouse's story
<pclass="story">Once upon a time there were three little sisters; and their names were <aclass="sister"href="http://example.com/elsie"id="link1"><!-- Elsie --></a>, <aclass="sister"href="http://example.com/lacie"id="link2">Lacie</a> and <aclass="sister"href="http://example.com/tillie"id="link3">Tillie</a>; and they lived at the bottom of a well.</p> Once upon a time there were three little sisters; and their names were
forstringin soup.strings: print(repr(string)) # u"The Dormouse's story" # u'\n\n' # u"The Dormouse's story" # u'\n\n' # u'Once upon a time there were three little sisters; and their names were\n' # u'Elsie' # u',\n' # u'Lacie' # u' and\n' # u'Tillie' # u';\nand they lived at the bottom of a well.' # u'\n\n' # u'...' # u'\n'
forstringin soup.stripped_strings: print(repr(string)) # u"The Dormouse's story" # u"The Dormouse's story" # u'Once upon a time there were three little sisters; and their names were' # u'Elsie' # u',' # u'Lacie' # u'and' # u'Tillie' # u';\nand they lived at the bottom of a well.' # u'...'
print soup.p.next_sibling # 实际该处为空白 print soup.p.prev_sibling #None 没有前一个兄弟节点,返回 None print soup.p.next_sibling.next_sibling #<pclass="story">Once upon a time there were three little sisters; and their names were #<aclass="sister"href="http://example.com/elsie"id="link1"><!-- Elsie --></a>, #<aclass="sister"href="http://example.com/lacie"id="link2">Lacie</a> and #<aclass="sister"href="http://example.com/tillie"id="link3">Tillie</a>; #and they lived at the bottom of a well.</p> #下一个节点的下一个兄弟节点是我们可以看到的节点
for sibling in soup.a.next_siblings: print(repr(sibling)) # u',\n' # <a class="sister"href="http://example.com/lacie"id="link2">Lacie</a> # u' and\n' # <a class="sister"href="http://example.com/tillie"id="link3">Tillie</a> # u'; and they lived at the bottom of a well.' # None
(9)前后节点
知识点:.next_element .previous_element 属性
与 .next_sibling .previous_sibling 不同,它并不是针对于兄弟节点,而是在所有节点,不分层次 比如 head 节点为
for element in last_a_tag.next_elements: print(repr(element)) # u'Tillie' # u';\nand they lived at the bottom of a well.' # u'\n\n' # <p class="story">...</p> # u'...' # u'\n' # None
以上是遍历文档树的基本用法。
7.搜索文档树
(1)find_all( name , attrs , recursive , text , **kwargs )
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件 1)name 参数 name 参数可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉 A.传字符串 最简单的过滤器是字符串.在搜索方法中传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容,下面的例子用于查找文档中所有的标签
soup.find_all(has_class_but_no_id) # [<pclass="title"><b>The Dormouse's story</b></p>, # <pclass="story">Once upon a time there were...</p>, # <pclass="story">...</p>]
2)keyword 参数
注意:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,如果包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性
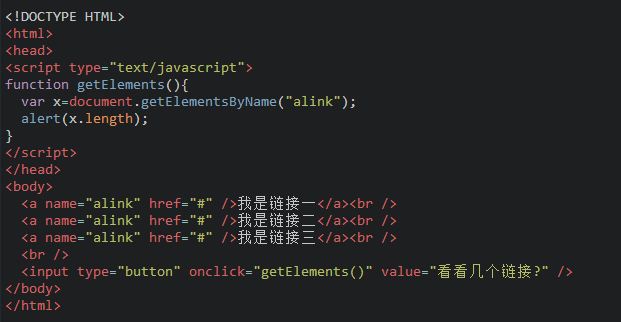
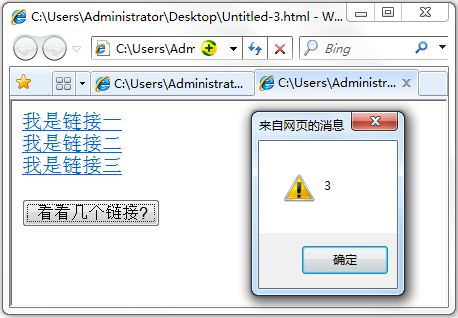
以人来举例说明,人有能标识身份的身份证,有姓名,有类别(大人、小孩、老人)等。 1. ID 是一个人的身份证号码,是唯一的。所以通过getElementById获取的是指定的一个人。 2. Name 是他的名字,可以重复。所以通过getElementsByName获取名字相同的人集合。 3. TagName可看似某类,getElementsByTagName获取相同类的人集合。如获取小孩这类人,getElementsByTagName(“小孩”)。 把上面的例子转换到HTML中,如下:
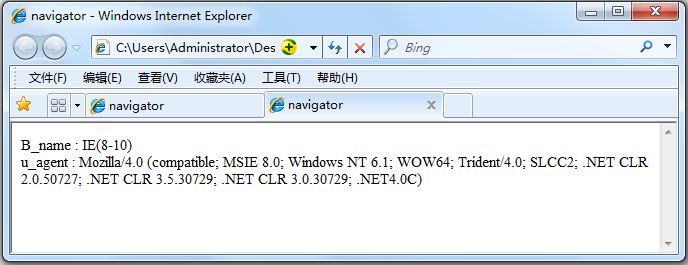
function validB(){ var u_agent = navigator.userAgent; var B_name="Failed to identify the browser"; if(u_agent.indexOf("Firefox")>-1){ B_name="Firefox"; }elseif(u_agent.indexOf("Chrome")>-1){ B_name="Chrome"; }elseif(u_agent.indexOf("MSIE")>-1&&u_agent.indexOf("Trident")>-1){ B_name="IE(8-10)"; } document.write("B_name:"+B_name+"<br>"); document.write("u_agent:"+u_agent+"<br>"); }
<scripttype="text/javascript"> var mydate=newDate();//定义日期对象 var weekday=["星期日","星期一","星期二","星期三","星期四","星期五","星期六"]; //定义数组对象,给每个数组项赋值 var mynum=mydate.getDay();//返回值存储在变量mynum中 document.write(mydate.getDay());//输出getDay()获取值 document.write("今天是:"+ weekday[mynum]);//输出星期几 </script>
<scripttype="text/javascript"> var mya1= newArray("hello!") var mya2= newArray("I","love"); var mya3= newArray("JavaScript","!"); var mya4=mya1.concat(mya2,mya3); document.write(mya4); </script>
1. 淘宝的密码用了 AES 加密算法,最终将密码转化为 256 位,在 POST 时,传输的是 256 位长度的密码。 2. 淘宝在登录时必须要输入验证码,在经过几次尝试失败后最终获取了验证码图片让用户手动输入来验证。 3. 淘宝另外有复杂且每天在变的 ua 加密算法,在程序中我们需要提前获取某一 ua 码才可进行模拟登录。 4. 在获取最后的登录 st 码时,历经了多次请求和正则表达式提取,且 st 码只可使用一次。
整体思路梳理
1. 手动到浏览器获取 ua 码以及 加密后的密码,只获取一次即可,一劳永逸。 2. 向登录界面发送登录请求,POST 一系列参数,包括 ua 码以及密码等等,获得响应,提取验证码图像。 3. 用户输入手动验证码,重新加入验证码数据再次用 POST 方式发出请求,获得响应,提取 J_Htoken。 4. 利用 J_Htoken 向 alipay 发出请求,获得响应,提取 st 码。 5. 利用 st 码和用户名,重新发出登录请求,获得响应,提取重定向网址,存储 cookie。 6. 利用 cookie 向其他个人页面如订单页面发出请求,获得响应,提取订单详情。 是不是没看懂?没事,下面我将一点点说明自己模拟登录的过程,希望大家可以理解。
前期准备
由于淘宝的 ua 算法和 aes 密码加密算法太复杂了,ua 算法在淘宝每天都是在变化的,不过,这个内容你获取之后一直用即可,经过测试之后没有问题,一劳永逸。 那么 ua 和 aes 密码怎样获取呢? 我们就从浏览器里面直接获取吧,打开浏览器,找到淘宝的登录界面,按 F12 或者浏览器右键审查元素。 在这里我用的是火狐浏览器,首先记得在浏览器中设置一下显示持续日志,要不然页面跳转了你就看不到之前抓取的信息了。在这里截图如下: 好,那么接下来我们就从浏览器中获取 ua 和 aes 密码 点击网络选项卡,这时都是空的,什么数据也没有截取。这时你就在网页上登录一下试试吧,输入用户名啊,密码啊,有必要时需要输入验证码,点击登录。 等跳转成功后,你就可以看到好多日志记录了,点击图中的那一行 login.taobo.com,然后查看参数,你就会发现表单数据了,其中就包括 ua 还有下面的 password2,把这俩复制下来,我们之后要用到的。这就是我们需要的 ua 还有 aes 加密后的密码。 恩,读到这里,你应该获取到了属于自己的 ua 和 password2 两个内容。
st 也是一个经计算得到的 code,可以这么理解,st 是淘宝后台利用 J_HToken 以及其他数据经过计算之后得到的,可以利用 st 和用户名直接用 get 方式登录,所以 st 可以理解为一个秘钥。这个 st 值只会使用一次,如果第二次用 get 方式登录则会失效。所以它是一次性使用的。 下面 J_HToken 计算 st 的方法如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
#通过token获得st defgetSTbyToken(self,token): tokenURL = 'https://passport.alipay.com/mini_apply_st.js?site=0&token=%s&callback=stCallback6' % token request = urllib2.Request(tokenURL) response = urllib2.urlopen(request) #处理st,获得用户淘宝主页的登录地址 pattern = re.compile('{"st":"(.*?)"}',re.S) result = re.search(pattern,response.read()) #如果成功匹配 if result: printu"成功获取st码" #获取st的值 st = result.group(1) return st else: printu"未匹配到st" returnFalse
直接利用 st 登录
得到 st 之后,基本上就大功告成啦,一段辛苦终于没有白费,你可以直接构建 get 方式请求的 URL,直接访问这个 URL 便可以实现登录。
#获取所有已买到的宝贝信息 defgetAllGoods(self,pageNum): printu"获取到的商品列表如下" for x in range(1,int(pageNum)+1): page = self.getGoodsPage(x) self.tool.getGoodsInfo(page)
#传入图片地址,文件名,保存单张图片 def saveImg(self,imageURL,fileName): u = urllib.urlopen(imageURL) data = u.read() f = open(fileName, 'wb') f.write(data) f.close()
2)写入文本
1 2 3 4 5
defsaveBrief(self,content,name): fileName = name + "/" + name + ".txt" f = open(fileName,"w+") printu"正在偷偷保存她的个人信息为",fileName f.write(content.encode('utf-8'))
#保存个人简介 defsaveBrief(self,content,name): fileName = name + "/" + name + ".txt" f = open(fileName,"w+") printu"正在偷偷保存她的个人信息为",fileName f.write(content.encode('utf-8'))
#传入图片地址,文件名,保存单张图片 defsaveImg(self,imageURL,fileName): u = urllib.urlopen(imageURL) data = u.read() f = open(fileName, 'wb') f.write(data) printu"正在悄悄保存她的一张图片为",fileName f.close()
defgetGrade(self): #计算总绩点 sum = 0.0 weight = 0.0 for i in range(len(self.credit)): if(self.grades[i].isdigit()): sum += string.atof(self.credit[i])*string.atof(self.grades[i]) weight += string.atof(self.credit[i])
安装完毕之后,输入 scrapy 注意,这里 linux 下不要输入 Scrapy,linux 依然严格区分大小写的,感谢 kamen 童鞋提醒。 如果出现如下提示,这证明安装成功
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Usage: scrapy <command> [options] [args]
Available commands: bench Run quick benchmark test fetch Fetch a URL using the Scrapy downloader runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy
[ more ] More commands available when runfrom project directory
Name = BAIDUID Value = B07B663B645729F11F659C02AAE65B4C:FG=1 Name = BAIDUPSID Value = B07B663B645729F11F659C02AAE65B4C Name = H_PS_PSSID Value = 12527_11076_1438_10633 Name = BDSVRTM Value = 0 Name = BD_HOME Value = 0
http 协议有六种请求方法,get,head,put,delete,post,options,我们有时候需要用到 PUT 方式或者 DELETE 方式请求。
PUT:这个方法比较少见。HTML 表单也不支持这个。本质上来讲, PUT 和 POST 极为相似,都是向服务器发送数据,但它们之间有一个重要区别,PUT 通常指定了资源的存放位置,而 POST 则没有,POST 的数据存放位置由服务器自己决定。 DELETE:删除某一个资源。基本上这个也很少见,不过还是有一些地方比如 amazon 的 S3 云服务里面就用的这个方法来删除资源。
如果要使用 HTTP PUT 和 DELETE ,只能使用比较低层的 httplib 库。虽然如此,我们还是能通过下面的方式,使 urllib2 能够发出 PUT 或 DELETE 的请求,不过用的次数的确是少,在这里提一下。
怎样扒网页呢?其实就是根据 URL 来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段 HTML 代码,加 JS、CSS,如果把网页比作一个人,那么 HTML 便是他的骨架,JS 便是他的肌肉,CSS 便是它的衣服。所以最重要的部分是存在于 HTML 中的,下面我们就写个例子来扒一个网页下来。
上面的程序演示了最基本的网页抓取,不过,现在大多数网站都是动态网页,需要你动态地传递参数给它,它做出对应的响应。所以,在访问时,我们需要传递数据给它。最常见的情况是什么?对了,就是登录注册的时候呀。 把数据用户名和密码传送到一个 URL,然后你得到服务器处理之后的响应,这个该怎么办?下面让我来为小伙伴们揭晓吧! 数据传送分为 POST 和 GET 两种方式,两种方式有什么区别呢? 最重要的区别是 GET 方式是直接以链接形式访问,链接中包含了所有的参数,当然如果包含了密码的话是一种不安全的选择,不过你可以直观地看到自己提交了什么内容。POST 则不会在网址上显示所有的参数,不过如果你想直接查看提交了什么就不太方便了,大家可以酌情选择。
POST 方式:
上面我们说了 data 参数是干嘛的?对了,它就是用在这里的,我们传送的数据就是这个参数 data,下面演示一下 POST 方式。
在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以及百度搜索框,这个过程其实就是用户输入网址之后,经过DNS服务器,找到服务器主机,向服务器发出一个请求,服务器经过解析之后,发送给用户的浏览器 HTML、JS、CSS 等文件,浏览器解析出来,用户便可以看到形形色色的图片了。 因此,用户看到的网页实质是由 HTML 代码构成的,爬虫爬来的便是这些内容,通过分析和过滤这些 HTML 代码,实现对图片、文字等资源的获取。
上市了!")



 比较奇怪,phpmyadmin 可以正常访问,而 Mysql-Front 为什么无法连接呢?可能的原因,应该就是 IP 限制了,phpmyadmin 在连接时使用的是 localhost,而我们访问页面才使用的远程主机的 IP,而 Mysql-Front 连接的是远程主机。 解决方法如下, 首先修改 mysql 的配置文件,my.cnf,将
比较奇怪,phpmyadmin 可以正常访问,而 Mysql-Front 为什么无法连接呢?可能的原因,应该就是 IP 限制了,phpmyadmin 在连接时使用的是 localhost,而我们访问页面才使用的远程主机的 IP,而 Mysql-Front 连接的是远程主机。 解决方法如下, 首先修改 mysql 的配置文件,my.cnf,将




























 点击环境变量进行环境变量配置,如图所示:
点击环境变量进行环境变量配置,如图所示:  配置方法一: 1)配置时找到系统变量,找到path变量,如果没有则新建。 在变量名填Path,变量值填 D:\jdk1.7\bin;注意要加分号! 如图所示:
配置方法一: 1)配置时找到系统变量,找到path变量,如果没有则新建。 在变量名填Path,变量值填 D:\jdk1.7\bin;注意要加分号! 如图所示:  2)同理,找到变量名classpath,没有就新建一个classpath 变量值填D:\jdk1.7\lib;. 配制方法二:
2)同理,找到变量名classpath,没有就新建一个classpath 变量值填D:\jdk1.7\lib;. 配制方法二:
 首先进行汉化
首先进行汉化  在原先的JspEclipse下的eclipse文件夹下新建一个links文件夹,再新建文本文件,扩展名为link,内容如图所示:
在原先的JspEclipse下的eclipse文件夹下新建一个links文件夹,再新建文本文件,扩展名为link,内容如图所示:  这样汉化就完成了
这样汉化就完成了 同上在原先的JspEclipse下的eclipse文件夹下新建一个links文件夹,再新建文本文件,扩展名为link,内容如图所示:
同上在原先的JspEclipse下的eclipse文件夹下新建一个links文件夹,再新建文本文件,扩展名为link,内容如图所示:  这样lomboz就配置完成啦,启动一下试试!
这样lomboz就配置完成啦,启动一下试试!  此处显示中文,说明汉化成功! 小问题的解决:或许有的人会显示这样的页面:
此处显示中文,说明汉化成功! 小问题的解决:或许有的人会显示这样的页面:  那么下载
那么下载  -vm 这里是相对的jdk环境设置,这个要设置成你自己的jdk环境,自己写一个路径,在bin目录下,一个javaw.exe文件,如果还不行,那么可能是jdk的版本导致的,我换用了jdk1.6测试成功!如果1.7不能用的话,就换用1.6版本的jdk吧! 好,小问题暂告一段落,看下图。
-vm 这里是相对的jdk环境设置,这个要设置成你自己的jdk环境,自己写一个路径,在bin目录下,一个javaw.exe文件,如果还不行,那么可能是jdk的版本导致的,我换用了jdk1.6测试成功!如果1.7不能用的话,就换用1.6版本的jdk吧! 好,小问题暂告一段落,看下图。  如果你能新建Dynamic Web Project说明你已经全配置成功啦!欢呼吧骚年们!
如果你能新建Dynamic Web Project说明你已经全配置成功啦!欢呼吧骚年们! tomcat环境变量的配置: 1,新建变量名:CATALINA_BASE,变量值:D:\tomcat 6.0\apache-tomcat-6.0.29 2,新建变量名:CATALINA_HOME,变量值:D:\tomcat 6.0\apache-tomcat-6.0.29 【1和2中的路径根据你存放的目录不同而不同】 3,打开PATH,添加变量值:%CATALINA_HOME%\lib;%CATALINA_HOME%\bin 启动tomcat: 在开始菜单输入cmd,然后cd命令定位到tomcat的bin目录,如图
tomcat环境变量的配置: 1,新建变量名:CATALINA_BASE,变量值:D:\tomcat 6.0\apache-tomcat-6.0.29 2,新建变量名:CATALINA_HOME,变量值:D:\tomcat 6.0\apache-tomcat-6.0.29 【1和2中的路径根据你存放的目录不同而不同】 3,打开PATH,添加变量值:%CATALINA_HOME%\lib;%CATALINA_HOME%\bin 启动tomcat: 在开始菜单输入cmd,然后cd命令定位到tomcat的bin目录,如图  然后输入 startup.bat命令,这时tomcat就启动起来了,会弹出一个新的窗口,那个就是tomcat
然后输入 startup.bat命令,这时tomcat就启动起来了,会弹出一个新的窗口,那个就是tomcat  下面这个图就是tomcat:
下面这个图就是tomcat:  下面进行测试:在浏览器输入
下面进行测试:在浏览器输入
 点选服务器—>运行时环境—>添加,选择Apach—>tomcat6.0,完成
点选服务器—>运行时环境—>添加,选择Apach—>tomcat6.0,完成  创建之后编辑,添加tomcat的目录,名称自己随便取,jre用缺省jre
创建之后编辑,添加tomcat的目录,名称自己随便取,jre用缺省jre  这样在eclipse下方就出现了一个tomcat了,绿色的箭头就是启动,红色的方块是停止
这样在eclipse下方就出现了一个tomcat了,绿色的箭头就是启动,红色的方块是停止  可以点击运行tomcat,其中点下方标记的红色处,可以对tomcat进行详细配置,默认配置即可,不用更改了
可以点击运行tomcat,其中点下方标记的红色处,可以对tomcat进行详细配置,默认配置即可,不用更改了 
 点下一步,我取名为test,服务器选刚才创建的tomcat6.0,然后下一步,下一步,直到完成就好了
点下一步,我取名为test,服务器选刚才创建的tomcat6.0,然后下一步,下一步,直到完成就好了  在webcontent目录下面新建一个jsp文件,我的叫a.jsp
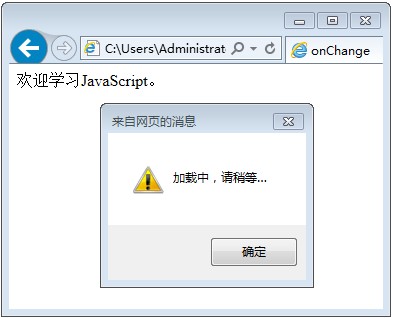
在webcontent目录下面新建一个jsp文件,我的叫a.jsp  我在body区输入了My First Jsp 右击该文件,在服务器上运行,选择tomcat,然后结果如图所示。恭喜你,所有配置都成功啦!
我在body区输入了My First Jsp 右击该文件,在服务器上运行,选择tomcat,然后结果如图所示。恭喜你,所有配置都成功啦!  点选eclipse的窗口,然后web浏览器,选default system web browser,即系统默认浏览器,就可以用自己的浏览器打开界面啦。如图所示
点选eclipse的窗口,然后web浏览器,选default system web browser,即系统默认浏览器,就可以用自己的浏览器打开界面啦。如图所示 




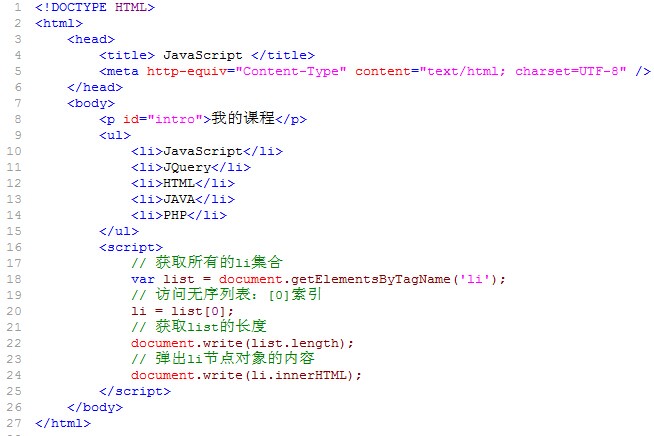


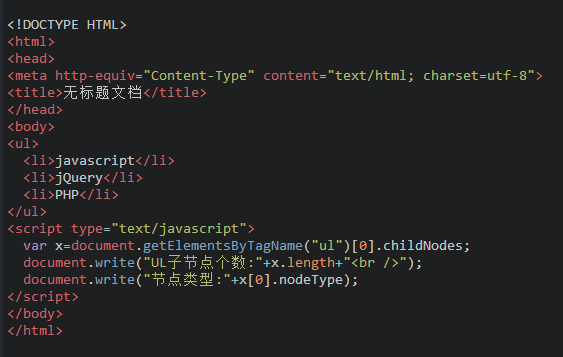



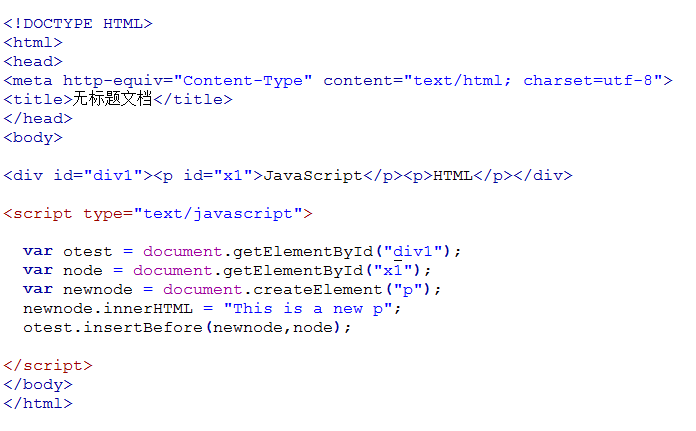



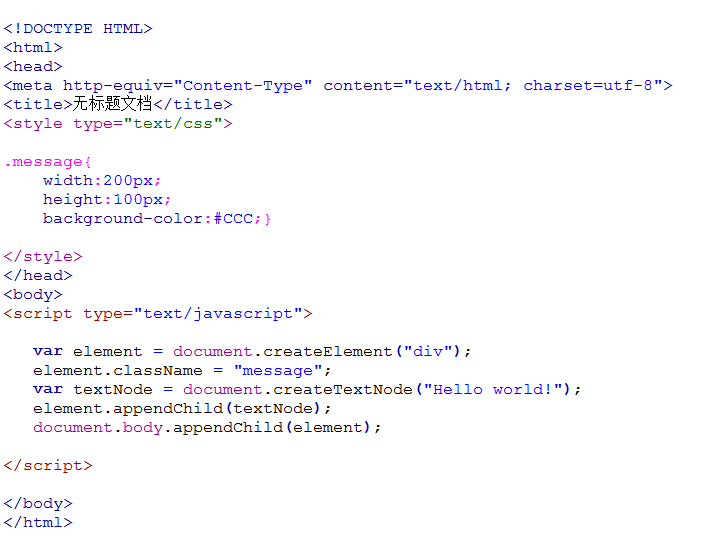
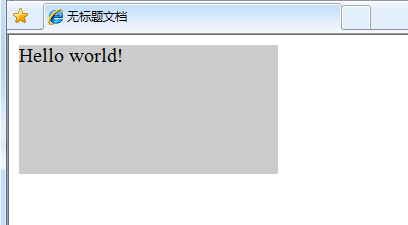
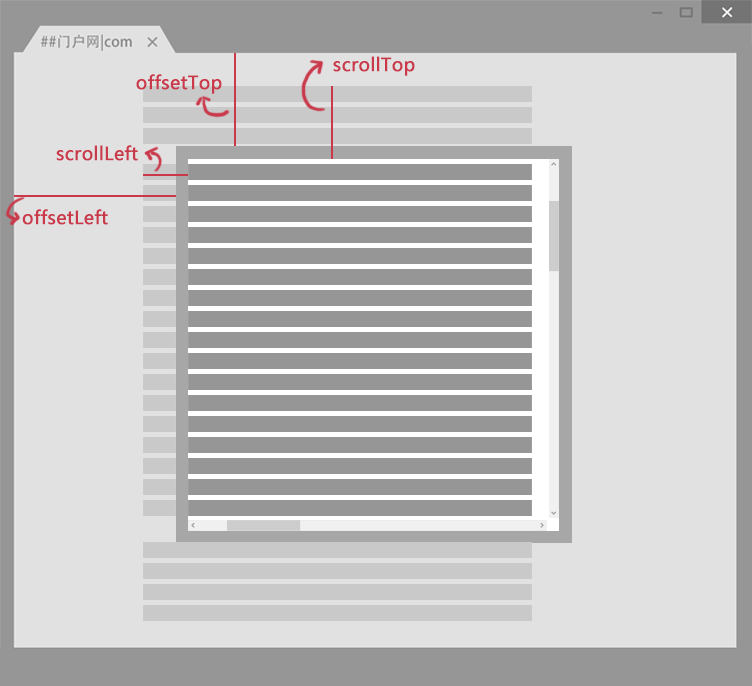
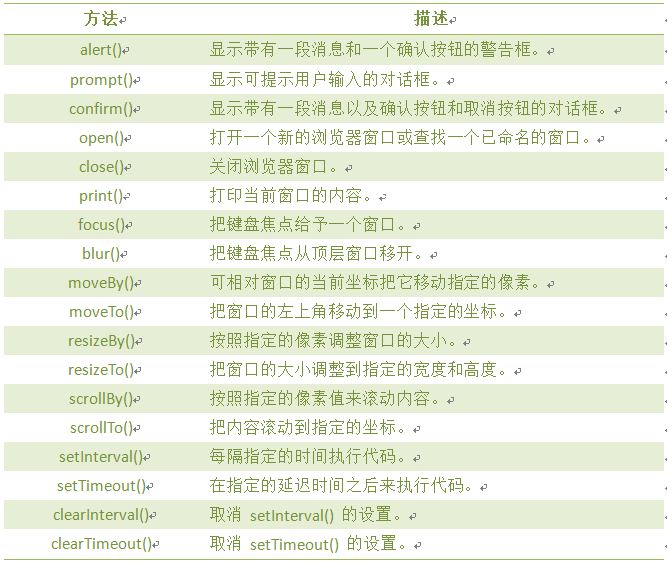
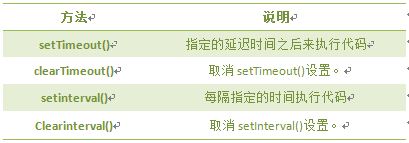




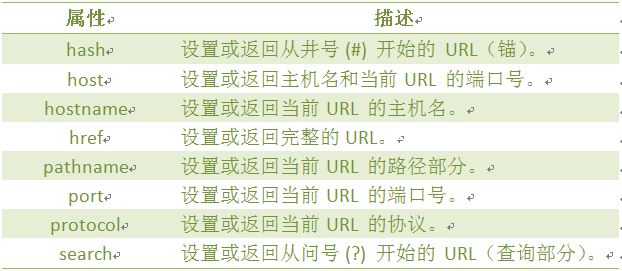


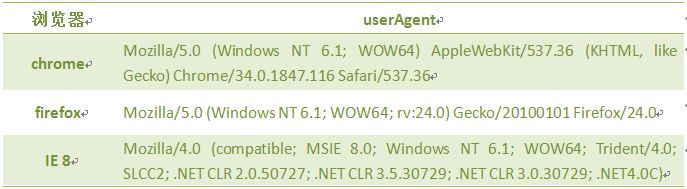
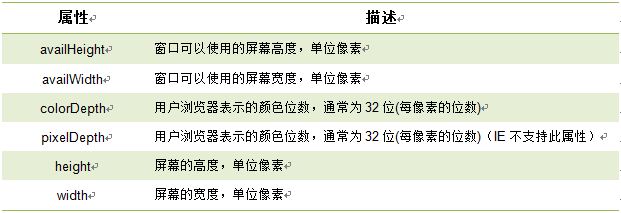




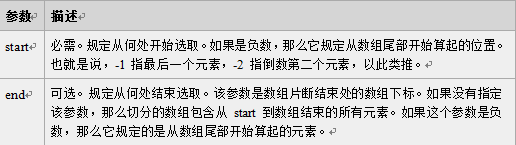
 注意: 1. 返回的内容是从 start开始(包含start位置的字符)到 stop-1 处的所有字符,其长度为 stop 减start。 2. 如果参数 start 与 stop 相等,那么该方法返回的就是一个空串(即长度为 0 的字符串)。 3. 如果 start 比 stop 大,那么该方法在提取子串之前会先交换这两个参数。 使用 substring() 从字符串中提取字符串,代码如下:
注意: 1. 返回的内容是从 start开始(包含start位置的字符)到 stop-1 处的所有字符,其长度为 stop 减start。 2. 如果参数 start 与 stop 相等,那么该方法返回的就是一个空串(即长度为 0 的字符串)。 3. 如果 start 比 stop 大,那么该方法在提取子串之前会先交换这两个参数。 使用 substring() 从字符串中提取字符串,代码如下:
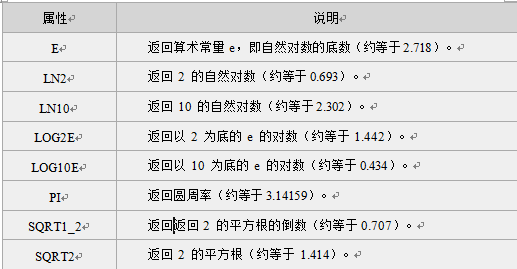
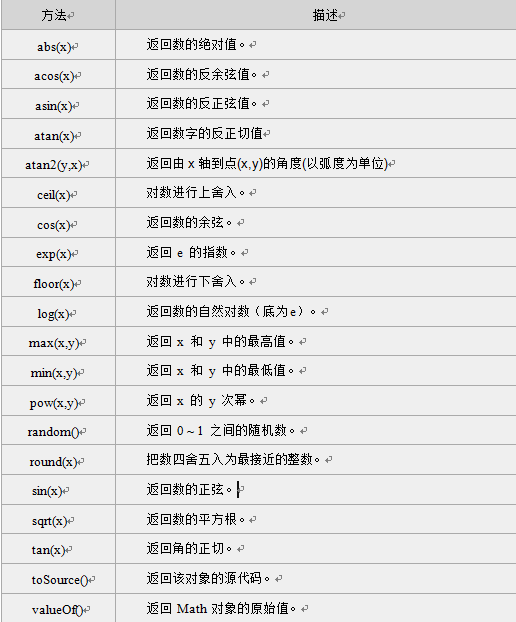

 注意:返回的是小于或等于x,并且与x最接近的整数。 我们将在不同的数字上使用 floor() 方法,代码如下:
注意:返回的是小于或等于x,并且与x最接近的整数。 我们将在不同的数字上使用 floor() 方法,代码如下: 注意: 1. 返回与 x 最接近的整数。 2. 对于 0.5,该方法将进行上舍入。(5.5 将舍入为 6) 3. 如果 x 与两侧整数同等接近,则结果接近 +∞方向的数字值 。(如 -5.5 将舍入为 -5; -5.52 将舍入为 -6),如下图:
注意: 1. 返回与 x 最接近的整数。 2. 对于 0.5,该方法将进行上舍入。(5.5 将舍入为 6) 3. 如果 x 与两侧整数同等接近,则结果接近 +∞方向的数字值 。(如 -5.5 将舍入为 -5; -5.52 将舍入为 -6),如下图: 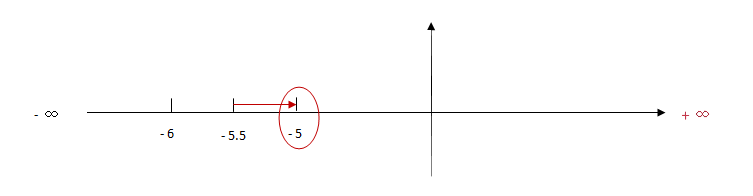
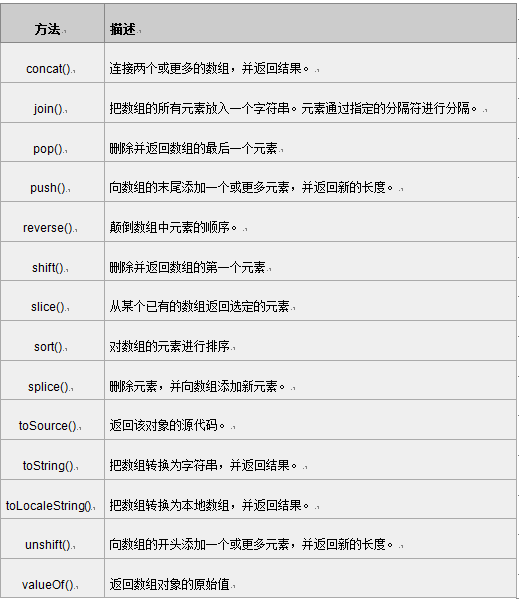

 注意:返回一个字符串,该字符串把数组中的各个元素串起来,用<分隔符>置于元素与元素之间。这个方法不影响数组原本的内容。 我们使用join()方法,将数组的所有元素放入一个字符串中,代码如下:
注意:返回一个字符串,该字符串把数组中的各个元素串起来,用<分隔符>置于元素与元素之间。这个方法不影响数组原本的内容。 我们使用join()方法,将数组的所有元素放入一个字符串中,代码如下: