the default rule for AnyProxy. Anyproxy rules initialize finished, have fun! The WebSocket will not work properly in the https intercept mode :( fs.js:885 return binding.mkdir(pathModule._makeLong(path), ^ Error:EACCES: permission denied, mkdir '/Users/chenwenguan/.anyproxy/cache_r929590' at Object.fs.mkdirSync (fs.js:885:18) at Object.module.exports.generateCacheDir (/Users/chenwenguan/.nvm/versions/node/v8.9.3/lib/node_modules/anyproxy/lib/util.js:54:8) at new Recorder (/Users/chenwenguan/.nvm/versions/node/v8.9.3/lib/node_modules/anyproxy/lib/recorder.js:16:31) at /Users/chenwenguan/.nvm/versions/node/v8.9.3/lib/node_modules/anyproxy/proxy.js:116:43 at ChildProcess.exithandler (child_process.js:282:5) at emitTwo (events.js:126:13) at ChildProcess.emit (events.js:214:7) at maybeClose (internal/child_process.js:925:16) at Socket.stream.socket.on (internal/child_process.js:346:11) at emitOne (events.js:116:13)
对于 onDragEnd 方法来说,其实就是检测最后的结果了,刚才我们用 state 变量里面的 over 属性来代表是否拖动到目标位置上,这里我们也定义了另外的 dragged 属性来代表是否已经拖动完成,dragging 属性来代表是否正在拖动,所以整个方法的逻辑上是检测 over 属性,然后对 dragging、dragged 属性做赋值,然后做一些相应的提示,实现如下:
def drop_nonattrs(d, type): if not isinstance(d, dict): return d attrs_attrs = getattr(type, '__attrs_attrs__', None) if attrs_attrs is None: raise ValueError(f'type {type} isnotanattrsclass') attrs: Set[str] = {attr.name for attr in attrs_attrs} return {key: val for key, valin d.items()if key in attrs}
from typing import Set from attr import attrs, attrib import cattr
@attrs classPoint(object): x = attrib(type=int, default=0) y = attrib(type=int, default=0)
defdrop_nonattrs(d, type): ifnotisinstance(d, dict): returnd attrs_attrs = getattr(type, '__attrs_attrs__', None) ifattrs_attrsisNone: raiseValueError(f'type {type} isnot an attrs class') attrs: Set[str] = {attr.name for attr in attrs_attrs} return {key: val for key, val in d.items() if key in attrs}
import csv with open("employee.csv", mode="r") as csv_file: csv_reader = csv.DictReader(csv_file) line_count = 0 for row in csv_reader: if line_count == 0: print(f'Column names are {", ".join(row)}') line_count += 1 print(f'\\t{row["name"]} salary: {row["salary"]}' f'and was born in {row["birthday month"]}.') line_count += 1 print(f'Processed {line_count} lines.')
将代码分解为函数有助于使复杂的代码变的易于阅读和调试。 这里的代码在 with 语句中执行多项操作。为了提高可读性,您可以将带有 process salary 的代码从 CSV 文件中提取到另一个函数中,以降低出错的可能性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
import csv with open("employee.csv", mode="r") as csv_file: csv_reader = csv.DictReader(csv_file) line_count = 0 process_salary(csv_reader)
defprocess_salary(csv_reader): """Process salary of user from csv file.""" for row in csv_reader: if line_count == 0: print(f'Column names are {", ".join(row)}') line_count += 1 print(f'\\t{row["name"]} salary: {row["salary"]}' f'and was born in {row["birthday month"]}.') line_count += 1 print(f'Processed {line_count} lines.')
代码是不是变得容易理解了不少呢。 在这里,创建了一个帮助函数,而不是在 with 语句中编写所有内容。这使读者清楚地了解了函数的实际作用。如果想处理一个特定的异常或者想从 CSV 文件中读取更多的数据,可以进一步分解这个函数,以遵循单一职责原则,一个函数一做一件事。这个很重要
defcall_weather_api(url, location): """Get the weather of specific location. Calling weather api to check for weather by using weather api and location. Make sure you provide city name only, country and county names won't be accepted and will throw exception if not found the city name. :param url:URL of the api to get weather. :type url: str :param location:Location of the city to get the weather. :type location: str :return: Give the weather information of given location. :rtype: str"""
defcall_weather_api(url: str, location: str) -> str: """Get the weather of specific location. Calling weather api to check for weather by using weather api and location. Make sure you provide city name only, country and county names won't be accepted and will throw exception if not found the city name. """
"""This module contains all of the network related requests. This module will checkforall the exceptionswhile making the network calls andraiseexceptionsforanyunknown exception. Make sure that when you use this module, you handle these exceptionsinclient code as: NetworkError exceptionfor network calls. NetworkNotFound exceptionif network not found. """ import urllib3 import json
在为模块编写文档字符串时,应考虑执行以下操作:
对当前模块写一个简要的说明
如果想指定某些对读者有用的模块,如上面的代码,还可以添加异常信息,但是注意不要太详细。
1 2
NetworkError exception for network calls. NetworkNotFound exception if network not found.
classStudent: """Student class information. This class handle actions performed by a student. This class provides information about student full name, age, roll-number and other information. Usage: import student student = student.Student() student.get_name() >>> 678998 """ def__init__(self): pass
这个类 docstring 是多行的; 我们写了很多关于 Student 类的用法以及如何使用它。
函数的 docstring
函数文档字符串可以写在函数之后,也可以写在函数的顶部。
1 2 3 4 5 6 7 8 9 10 11 12
def is_prime_number(number): """Checkfor prime number.
Check the given numberis prime number ornotby checking against all the numbers less the square root of given number.
:param number:Given numbertocheckfor prime :typenumber: int :return: Trueifnumberis prime otherwise False. :rtype: boolean """
如果我们使用类型注解对其进一步优化。
1 2 3 4 5 6 7
defis_prime_number(number: int)->bool: """Check for prime number. Check the given number is prime number or not by checking against all the numbers less the square root of given number. """
import pathlib now_path = pathlib.Path.cwd() from datetime import datetime time, file_path = max((f.stat().st_mtime, f) for f in now_path.iterdir()) print(datetime.fromtimestamp(time), file_path)
甚至可以使用类似的表达式获取上次修改的文件内容
1 2 3 4 5
import pathlib from datetime import datetime now_path =pathlib.Path.cwd() result = max((f.stat().st_mtime, f) for f in now_path.iterdir())[1] print(result.read_text())
.stat().st_mtime 会返回文件的时间戳,可以使用 datetime 或者 time 模块对时间格式进行进一步转换。
入职微软之后,这边大多数是使用 Windows 进行开发的,比如我的台式机是 Windows 的,还有一部分服务器是 Windows 的,当然 Linux 是也非常多。 很多情况下我是使用自己的 Mac 笔记本来远程连接我的 Windows 机器来开发的。比如如果我在工位上,我会用我的 Mac 连接两块显示屏,然后一种一块用来远程桌面连接我的 Windows 开发机,这样另外一块屏幕和 Mac 自带的屏幕就用来看文档或者使用 Teams 通讯等等。如果我回家了,我家里也是有两块屏,开上 VPN,照样用一块屏使用远程桌面,另外一块屏幕和 Mac 自带屏幕就可以做其他事情了。 这样就解决了一个问题:我的 Windows 基本上都是仅用作开发的,一块屏幕就开着一个 Visual Studio,其他的操作都会在 Mac 进行,比如查文档,发消息等等。这样我下班之后照样使用远程连接的方式来操作,和在公司就是一样的。这样就避免了一些软件的来回登录,比如如果我上班只用公司机器,下班了之后换了 Mac 还得切 Teams、切微信、切浏览器等等,还是很麻烦的,而且上班期间 Mac 就闲置了也不好。所以我就采取了这样的开发方案。
需求分析
有了这个情景,就引入了一个问题。开了一个远程桌面之后,我几乎一个屏幕都是被 Visual Studio 占据的,而远程桌面貌似只能开一个屏幕?如果我要再开一个终端窗口的话,那可能屏幕就不太够用了,或者它就得覆盖我的全屏 Visual Stuido。 另外我平时 Mac 终端软件都是使用 SSH 的,基本都是用来连 Linux 的,Windows 一般都是开远程桌面。但命令行这个情形的确让我头疼,让我感到不够爽,因为毕竟远程桌面之后,Windows 里面的操作都得挤在一个桌面里面操作了。当然可能能设置多个桌面,如果可以的话,麻烦大家告知一下谢谢。 所以解决的痛点在于:我要把一些操作尽量从 Windows 里面分离出来,例如终端软件,我能否在远程桌面外面操作,能否使用 SSH 来控制我的 Windows 机器。 好,有需求才有动力,说干就干。
如果是放开的,那么结果会提示 OpenSSH-Server-In-TCP这个状态是 enabled。 好了,完成如上操作之后我们就可以使用 SSH 来连接我们的 Windows 服务器了。
连接
连接非常简单了,用户名密码就是 Windows 的用户名和密码,使用 IP 地址链接即可。 比如我的 Windows 开发机的局域网 IP 为:10.172.134.88,那么就可以使用如下命令完成链接:
1
ssh user@10.172.134.88
然后输入密码,就连接成功了,和 Linux 的是一样的。 另外我自己现在 Mac 常用的 SSH 客户端工具有 Termius,可以多终端同步使用,非常方便,这里我只需要添加我的 Windows 机器就好了,如图所示: OK,以后就可以非常轻松地用 SSH 连接我的 Windows 服务器了,爽歪歪,上面的需求也成功解决。 以上便是使用 SSH 来连接 Windows 服务器的方法,如果大家有需求可以试试。
(function (a) { a.fn.typewriter = function () { this.each(function () { var d = a(this), c = d.html(), b = 0; d.html(""); var e = setInterval(function () { var f = c.substr(b, 1); if (f == "<") { b = c.indexOf(">", b) + 1 } else { b++ } d.html(c.substring(0, b) + (b & 1 ? "_" : "")); if (b >= c.length) { clearInterval(e) } }, 75) }); return this } })(jQuery);
这里可以看到,首先获取了页面代码区域的内容,然后通过 DOM 操作将代码先清空,然后利用 setInterval 方法设置一个定时器,定时间隔 75 毫秒,也就是说 75 毫秒循环调用一次。每调用一次,就会从原来的字符上多取一个字符,然后尾部拼接一个下划线就好了。
# You are the greatest love of my life. whileTrue: ifu.with(i): you = everything else: everything = u
这个代码的含义叫做“无论天涯海角,你都是我的一切。“,一个 while True 循环代表了永久。 这些代码其实都是在 HTML 代码中预定义好的,其中注释需要用 span 标签配以 comments 的 class 来修饰,缩进需要用 span 标签配以 placeholder 的 class 来修饰,例如:
1 2 3 4 5 6
<spanclass="comments"># You are the greatest love of my life.</span><br/> while <spanclass="keyword">True</span>:<br/> <spanclass="placeholder"></span><spanclass="keyword">if</span> u.with(i):<br/> <spanclass="placeholder"></span><spanclass="placeholder"></span>you = everything<br/> <spanclass="placeholder"></span><spanclass="keyword">else</span>:<br/> <spanclass="placeholder"></span><spanclass="placeholder"></span>everything = u<br/>
这里不同的格式用 span 的不同 class 来标识,空格缩进一个 placeholder 是两个空格,comments 代表注释格式,关键词使用 keyword 来标识。如果你需要自定义自己的内容,通过控制这些内容穿插写入就好了。
functiontimeElapse(c) { var e = Date(); var f = (Date.parse(e) - Date.parse(c)) / 1000; var g = Math.floor(f / (3600 * 24)); f = f % (3600 * 24); var b = Math.floor(f / 3600); if (b < 10) { b = "0" + b } f = f % 3600; var d = Math.floor(f / 60); if (d < 10) { d = "0" + d } f = f % 60; if (f < 10) { f = "0" + f } }
function getHeartPoint(c) { var b = c / Math.PI; var a = 19.5 * (16 * Math.pow(Math.sin(b), 3)); var d = -20 * (13 * Math.cos(b) - 5 * Math.cos(2 * b) - 2 * Math.cos(3 * b) - Math.cos(4 * b)); return newArray(offsetX + a, offsetY + d) }
作为一名程序员,能够利用好工具提高开发和工作效率是非常重要的。我个人使用的都是苹果系列产品,电脑为 MacBook Pro 15 寸,手机 iPhone 7P,另外还有一个 iPad Pro 和一副 Apple Watch。我一直觉得 Mac 是非常适合做程序开发的,它既有比较不错的页面,也有类 Unix 的操作系统,使得日常使用和程序开发都极其便利,另外由于苹果本身自有的 iCloud 机制,使用 Mac、iPhone、iPad 跨平台开发和工作也变得十分便利。
近期我又对自己的一些工具进行了整理,弃用了一些工具,新启用了一些工具。目的也只有一个,就是提高自己的工作和开发效率,让生活变得更美好。如果你也在用 Mac 开发,或者你也有使用 iPad、iPhone,下面我所总结的个人的一些工具或许能给你带来帮助。
快速导航
这是 Mac 上的一个工具,要说到提高效率,首推 Alfred,可以说是 Mac 必备软件,利用它我们可以快速地进行各种操作,大幅提高工作效率,如快速打开某个软件、快速打开某个链接、快速搜索某个文档,快速定位某个文件,快速查看本机 IP,快速定义某个色值,几乎我们能想到的都能对接实现。
其实 Mac 本身已经自带了软件搜索还有 Spotlight,但是其功能还是远远比不上 Alfred,有了它,所有的快捷操作几乎都能实现。
另外使用 Mac 和 iPhone、iPad 之间也可以相互之间复制粘贴,可以在一台 Apple 设备上拷贝文本、图像、照片和视频,然后在另一台 Apple 设备上粘贴该内容。例如,可以拷贝在 Mac 上浏览网页时发现的食谱,然后将其粘贴到附近 iPhone 上“备忘录”中的购物清单。这是在 macOS Sierra 版本之后出来的功能,若要使用需要确保 Mac 的版本是 Sierra 及以后。若要使用,几个设备必须满足“连续互通”系统要求。它们还必须在“系统偏好设置”(在 Mac 上)和“设置”(在 iOS 设备上)中打开 Wi-Fi、蓝牙和 Handoff,另外必须在所有设备上使用同一 Apple ID登录 iCloud。
言归正传,既然谈到笔记和写作。我的笔记本是 Mac,之前几乎所有的笔记,包括写书,都几乎是在 Mac 上完成的,但是确实有的时候是不方便的。比如 Mac 不在身边或者想用 iPhone 或者 iPad 来写点东西的时候,一个需要解决的问题就是云同步问题。有了云同步,我们如果在电脑上写了一部分内容,接着切换了另一台台式机,或者切换了手机的时候,照样能够接着在原来的基础上写,非常方便。
所谓爬虫的智能化解析,顾名思义就是不再需要我们针对某一些页面来专门写提取规则了,我们可以利用一些算法来计算出来页面特定元素的位置和提取路径。比如一个页面中的一篇文章,我们可以通过算法计算出来,它的标题应该是什么,正文应该是哪部分区域,发布时间是什么等等。 其实智能化解析是非常难的一项任务,比如说你给人看一个网页的一篇文章,人可以迅速找到这篇文章的标题是什么,发布时间是什么,正文是哪一块,或者哪一块是广告位,哪一块是导航栏。但给机器来识别的话,它面临的是什么?仅仅是一系列的 HTML 代码而已。那究竟机器是怎么做到智能化提取的呢?其实这里面融合了多方面的信息。
比如标题。一般它的字号是比较大的,而且长度不长,位置一般都在页面上方,而且大部分情况下它应该和 title 标签里的内容是一致的。
比如正文。它的内容一般是最多的,而且会包含多个段落 p 或者图片 img 标签,另外它的宽度一般可能会占用到页面的三分之二区域,并且密度(字数除以标签数量)会比较大。
ttf 文件: *.ttf 是字体文件格式。TTF(TrueTypeFont)是 Apple 公司和 Microsoft 公司共同推出的字体文件格式,随着 windows 的流行,已经变成最常用的一种字体文件表示方式。 @font-face 是 CSS3 中的一个模块,主要是实现将自定义的 Web 字体嵌入到指定网页中去。
简单粗暴,直接上网站部分源代码,因为这个网站应该不太希望别人来爬,所以就不上网站了。为什么这么说,因为刚开始请求的时候,老是给我返回 GO TO HELL ,哈哈。 这个网站点击鼠标右键审查元素,查看网页源代码是无法用的,但是这个好像只能防住小白啊,简单的按 F12 审查元素,CTRL+u 直接查看源代码(谷歌浏览器)。 这次的目的主要是为了获取下面的链接(重度打码)
doc = etree.HTML(con) shops = doc.xpath('//div[@id="shop-all-list"]/ul/li') for shop in shops: # 店名 name = shop.xpath('.//div[@class="tit"]/a')[0].attrib["title"] print name comment_num = 0
comment_and_price_datas = shop.xpath('.//div[@class="comment"]') for comment_and_price_data in comment_and_price_datas: _comment_data = comment_and_price_data.xpath('a[@class="review-num"]/b/node()') # 遍历每一个node,这里node的类型不同,分别有etree._ElementStringResult(字符),etree._Element(元素),etree._ElementUnicodeResult(字符) for _node in _comment_data: # 如果是字符,则直接取出 if isinstance(_node, etree._ElementStringResult): comment_num = comment_num * 10 + int(_node) else: # 如果是span类型,则要去找数据 # span class的attr span_class_attr_name = _node.attrib["class"] # 偏移量,以及所处的段 offset, position = css_and_px_dict[span_class_attr_name] index = abs(int(float(offset) )) position = abs(int(float(position))) # 判断 for key, value in svg_threshold_and_int_dict.iteritems(): if position in value: threshold = int(math.ceil(index/12)) number = int(key[threshold]) comment_num = comment_num * 10 + number print comment_num
defget_public_ip_address(): """ 获取IP和实例ID :return: {实例ID: ip} """ response = ec2.describe_instances() reservations = response.get('Reservations') instances = [i.get('Instances')[0] for i in reservations] instance_id_public_ip_address = {i.get('InstanceId'): i.get('PublicIpAddress') for i in instances} return instance_id_public_ip_address
defreboot_ec2(ip): """重启实例 :param ip: :return: """ instance_id_public_ip_address = get_public_ip_address() instance_id = instance_id_public_ip_address.get(ip) try: ec2.reboot_instances(InstanceIds=[instance_id], DryRun=True) except ClientError as e: if'DryRunOperation'notin str(e): print("You don't have permission to reboot instances.") raise
首选我们梳理一下 Linux 下的用户、用户组、文件权限等基本知识,然后后面通过一个案例来实际演示一下权限设置的一些操作。 首先 Linux 系统中,是有用户和用户组的概念的,用户就是身份的象征,我们必须以某一个用户身份来操作一个系统,实际上这就对应着我们登录系统时的账号。而用户组就是一些用户的集合,我们可以通过用户组来划分和统一管理某些用户。 比如我要在微信发一条朋友圈,我只想给我的亲人们看,难道我发的时候还要一个个去勾选所有的人?这未免太麻烦了。为了解决这问题,微信里面就有了标签的概念,我们可以提前给好友以标签的方式分类,发的时候直接勾选某个标签就好了,简单高效。实际上这就是用户组的概念,我们可以将某些人进行分组和归类,到时候只需要指定类别或组别就可以了,而不用一个个人去对号入座,从而节省了大量时间。 在 Linux 中,一个用户是可以属于多个组的,一个组也是可以包含多个用户的,下面我以一台 Ubuntu Linux 为例来演示一下相关的命令和操作。
Adding user `cqc' ... Adding new group `cqc' (1002) ... Adding new user `cqc' (1002) with group `cqc'... Creating home directory `/home/cqc' ... Copying files from `/etc/skel'... Enter new UNIX password: Retype new UNIX password: passwd: password updated successfully Changing the user information for cqc Enter the new value, or press ENTER for the default Full Name []: Room Number []: Work Phone []: Home Phone []: Other []: Is the information correct? [Y/n]
id cqc uid=1002(cqc) gid=1002(cqc) groups=1002(cqc),27(sudo),1003(lab) id lbd uid=1004(lbd) gid=1005(lbd) groups=1005(lbd),1003(lab) id slb uid=1003(slb) gid=1004(slb) groups=1004(slb)
Welcome to fdisk (util-linux 2.27.1). Changes will remain in memory only, until you decide to write them. Be careful before using the write command.
Device does not contain a recognized partition table. Created a new DOS disklabel with disk identifier 0xc305fe54.
Command (m for help): n Partition type p primary (0 primary, 0 extended, 4 free) e extended (container for logical partitions) Select (default p): p Partition number (1-4, default 1): First sector (2048-2145386495, default 2048): Last sector, +sectors or +size{K,M,G,T,P} (2048-2145386495, default 2145386495):
Created a new partition 1 of type 'Linux'and of size 1023 GiB.
然后使用 p 打印分区表并使用 w 将表写入磁盘,然后退出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Command (m for help): p Disk /dev/sdc: 1023 GiB, 1098437885952bytes, 2145386496 sectors Units: sectors of1 * 512 = 512bytes Sector size (logical/physical): 512bytes / 512bytes I/O size (minimum/optimal): 512bytes / 512bytes Disklabel type: dos Disk identifier: 0xc305fe54
Device Boot StartEnd Sectors SizeIdType /dev/sdc1 2048214538649521453844481023G 83 Linux
Command (m forhelp): w The partitiontable has been altered. Calling ioctl() to re-readpartition table. Syncing disks.
阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续干别的事情,则称该程序在该操作上是阻塞的。 常见的阻塞形式有:网络 I/O 阻塞、磁盘 I/O 阻塞、用户输入阻塞等。阻塞是无处不在的,包括 CPU 切换上下文时,所有的进程都无法真正干事情,它们也会被阻塞。如果是多核 CPU 则正在执行上下文切换操作的核不可被利用。
Coroutine: <coroutine object execute at 0x10e0f7830> After calling execute Task: <Task pending coro=<execute() running at demo.py:4>> Number: 1 Task: <Task finished coro=<execute() done, defined at demo.py:4> result=1> After calling loop
Coroutine: <coroutine object execute at 0x10aa33830> After calling execute Task: <Task pending coro=<execute() running at demo.py:4>> Number: 1 Task: <Task finished coro=<execute() done, defined at demo.py:4> result=1> After calling loop
发现其效果都是一样的。
3.2 绑定回调
另外我们也可以为某个 task 绑定一个回调方法,来看下面的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
import asyncio import requests
async def request(): url = 'https://www.baidu.com' status = requests.get(url) return status
Waiting forhttp://127.0.0.1:5000 Get response from http://127.0.0.1:5000 Result: Hello! Waiting forhttp://127.0.0.1:5000 Get response from http://127.0.0.1:5000 Result: Hello! Waiting forhttp://127.0.0.1:5000 Get response from http://127.0.0.1:5000 Result: Hello! Waiting forhttp://127.0.0.1:5000 Get response from http://127.0.0.1:5000 Result: Hello! Waiting forhttp://127.0.0.1:5000 Get response from http://127.0.0.1:5000 Result: Hello! Cost time:15.049368143081665
Waiting forhttp://127.0.0.1:5000 Waiting forhttp://127.0.0.1:5000 Waiting forhttp://127.0.0.1:5000 Waiting forhttp://127.0.0.1:5000 Waiting forhttp://127.0.0.1:5000 Cost time:15.048935890197754 Task exception was never retrieved future: <Task finished coro=<request() done, defined at demo.py:7> exception=TypeError("object Response can't be used in 'await' expression",)> Traceback (most recent call last): File "demo.py", line 10, in request status = await requests.get(url) TypeError: object Response can't be used in 'await' expression
Waiting forhttp://127.0.0.1:5000 Get response from http://127.0.0.1:5000 Result: Hello! Waiting forhttp://127.0.0.1:5000 Get response from http://127.0.0.1:5000 Result: Hello! Waiting forhttp://127.0.0.1:5000 Get response from http://127.0.0.1:5000 Result: Hello! Waiting forhttp://127.0.0.1:5000 Get response from http://127.0.0.1:5000 Result: Hello! Waiting forhttp://127.0.0.1:5000 Get response from http://127.0.0.1:5000 Result: Hello! Cost time:15.134317874908447
Waiting forhttp://127.0.0.1:5000 Waiting forhttp://127.0.0.1:5000 Waiting forhttp://127.0.0.1:5000 Waiting forhttp://127.0.0.1:5000 Waiting forhttp://127.0.0.1:5000 Get response from http://127.0.0.1:5000 Result: Hello! Get response from http://127.0.0.1:5000 Result: Hello! Get response from http://127.0.0.1:5000 Result: Hello! Get response from http://127.0.0.1:5000 Result: Hello! Get response from http://127.0.0.1:5000 Result: Hello! Cost time:3.0199508666992188
一些日常工具在这里我就不一一列举了,大部分使用 Mac 的小伙伴都会安装,比如 QQ、微信、Chrome 浏览器、网易云音乐、迅雷等等,这些在 Windows 上也几乎都是必备软件,这里就不再展开说明了。
效率工具
效率工具顾名思义,可以方便和简化 Mac 的操作,提高生产工作效率的工具,下面推荐几款我比较常用的。
Alfred
首推 Alfred,可以说是 Mac 必备软件,利用它我们可以快速地进行各种操作,大幅提高工作效率,如快速打开某个软件、快速打开某个链接、快速搜索某个文档,快速定位某个文件,快速查看本机 IP,快速定义某个色值,几乎你能想到的都能对接实现。 这些快速功能是怎么实现的呢?实际上是 Alfred 对接了很多 Workflow,我们可以使用 Workflow 方便地进行功能扩展,一些比较优秀的 Workflow 已经有人专门做过整理了,可以参见:https://github.com/zenorocha/alfred-workflows。 推荐指数:★★★★★
Todoist
大家肯定也在使用各种 Todo List 的软件,这种软件其实也是五花八门,经过我本人试用,我觉得 Todoist 这款软件是最方便的。 它支持各种类型的任务定制,还可以设置分组、优先级、Deadline、执行人员、提醒、协作、效率统计等功能。另外它的各个平台支持真是异常地全啊,网页、PC、移动端就不用说了,都必须有的,另外它还有浏览器插件版、电邮版、可穿戴设备(如 Apple Watch、Google Wear)版,另外他还可以和 Mac 的日历事件进行同步,日历添加的事件也会自动添加到 Todoist 里面,非常方便,是目前我体验过的最好用的一款。 这款软件个人推荐购买专业版解锁全部功能,一个月 3 刀,但个人觉得确实非常值。 推荐指数:★★★★☆
Paste
Mac 上默认只有一个粘贴板,当我们新复制了一段文字之后,如果我们想再找寻之前复制的历史记录就找不到了,这其实是很反人类的。 好在 Paste 这款软件帮我们解决了这个问题,它可以保存我们粘贴板的历史记录,等需要粘贴某个内容的时候只需要呼出 Paste 历史粘贴板,然后选择某个特定的内容粘贴就好了,另外它还支持文本格式调整粘贴板分类和搜索,还可以支持快速便捷粘贴。有了它,妈妈再也不用担心我的粘贴板丢失了! 推荐指数:★★★★★
Synergy
工作时我会使用公司的台式机,是 Windows 系统,另外自己的个人笔记本 Mac 也会放在旁边,两台 PC 有时候会交替使用,但是我总不能配两套键盘和鼠标吧,这样就显得累赘了,而且也没那么多地方放啊。 有了 Synergy,我们可以将两台 PC 关联,实现键盘鼠标共享。我们可以使用一套键盘和鼠标来操作两台 PC,注意这是两个完全独立的 PC,各自有各自的屏幕和系统,使用 Synergy 我们可以做到一套键鼠同时控制两台电脑,鼠标可以直接从一台电脑的屏幕滑动到另一台电脑屏幕上,同时键盘、粘贴板也都是共享的。 设想这么个情景,我在我的台式机 Windows 上打开了一个页面,需要让我输入一个很长的序列号,而这个序列号又恰巧存在 Mac 上,这时如果有了 Synergy 将二者关联,我们只需要把鼠标从 Windows 的屏幕上直接滑动到 Mac 的屏幕上,选中序列号,然后键盘按下复制的快捷键,然后再把鼠标移回 Windows,粘贴即可,一气呵成。而不必再想办法发消息传输了,大大提高效率。 推荐指数:★★★★
用了 Mac,我们在使用移动硬盘的时候可能会遇到一个无法传输数据(如拷贝文件)的问题,这是因为部分移动硬盘是 NTFS 格式的,而 Mac 的磁盘不是这个格式,因此就会导致二者之间无法拷贝文件。有一个解决方法就是使用 Tuxera NTFS For Mac,有了它,我们就可以比较顺利地拷贝文件了。 另外还有其他品牌的 NTFS For Mac 软件,也可以尝试使用一下。 推荐指数:★★★★☆
VMware、Parallels Desktop
用了 Mac 之后,难免会有些情况下也还会不得不使用 Windows,毕竟很多软件可能只有 Windows 版本,但用 Mac 我就不推荐装双系统了,直接装虚拟机就好了,Mac 上虚拟机软件有两款比较好用,一个就是著名的 VMware,另一个就是 Parallels Desktop,这两款我都使用过,觉得都非常不错,现在用的是 VMware。 推荐指数:★★★★☆
CleanMyMac
很多时候用着用着磁盘就不够用了,如果你的 Mac 硬盘是 512GB 的倒还好,256GB 的你就得多注意一下了,另外 1T 定制版土豪请绕道,这款软件不适合你。 CleanMyMac 可以非常方便地帮助我们扫描缓存、大文件、废纸篓、残留项等内容,清理这些内容之后我们可以节省很多硬盘空间,另外它还支持软件卸载和残留清扫功能,可以帮我们非常干净地移除 Mac 中的软件,目前应该是出到第三版了,非常推荐。 推荐指数:★★★★☆
编辑器
既然做程序开发嘛,不配置好自己的开发环境怎么行,下面推荐一下我平常使用的开发软件。
JetBrains
我目前使用的 IDE 是 JetBrains 全家桶,目前我编写 Python 比较多,所以主要使用 PyCharm,另外写前端的时候也会使用 WebStorm,写 Java 就用 IntelliJ IDEA,C、C++ 用 CLion,PHP 的话就用 PhpStorm,Ruby 的话就用 RubyMine,其他的语言用的就少了,就没有装了。 当然有的小伙伴会说 JetBrains 系列的 IDE 需要购买啊?我只想说,国人的力量是无穷的,在网上其实可以搜到各种破解方法,如 License Server 验证,你能搜到各种五花八门的 License Server。另外 JetBrains 还有专门的 Educational Programs,可以来这里申请:https://www.jetbrains.com/education/programs/?fromMenu,学生、老师或教育工作者可以使用学校的 edu 邮箱申请免费的 License,如果你还是学生的话,那么申请是十分方便的,因为我还是个学生,我目前就在使用学生套餐,当然如果你已经工作的话也可以向正在上学的弟弟妹妹们借一下嘛。 总之我个人比较喜欢 JetBrains 全家桶,不论是页面风格还是开发习惯我都比较喜欢,推荐使用。 推荐指数:★★★★☆
对于开发者来说,这个软件几乎是 Mac 上必备的一个软件,它的官方简介就是 “The missing package manager for macOS”,算是 Mac 上的一个软件包平台,它里面包含着非常多的 Mac 开发软件包,比如 Python、PHP、Redis、MySQL、RabbitMQ、HBase 等等,几乎你能想到的开发软件都集成在里面了,堪称神器! 它的安装也非常简单,参见这里:https://brew.sh/,另外 HomeBrew 也有对应的图形界面,叫做 CakeBrew,如果不喜欢命令行操作的话可以使用 CakeBrew 来代替。 推荐指数:★★★★★
import gensim import jieba import numpy as np from scipy.linalg import norm
model_file = './word2vec/news_12g_baidubaike_20g_novel_90g_embedding_64.bin' model = gensim.models.KeyedVectors.load_word2vec_format(model_file, binary=True)
defvector_similarity(s1, s2): defsentence_vector(s): words = jieba.lcut(s) v = np.zeros(64) for word in words: v += model[word] v /= len(words) return v v1, v2 = sentence_vector(s1), sentence_vector(s2) return np.dot(v1, v2) / (norm(v1) * norm(v2))
# If these values are missing, it means we want to use the defaults. optional = { # TODO: Use custom prefixes for this settings to note that are # specific to scrapy-redis. 'queue_key': 'SCHEDULER_QUEUE_KEY', 'queue_cls': 'SCHEDULER_QUEUE_CLASS', 'dupefilter_key': 'SCHEDULER_DUPEFILTER_KEY', # We use the default setting name to keep compatibility. 'dupefilter_cls': 'DUPEFILTER_CLASS', 'serializer': 'SCHEDULER_SERIALIZER', } # 从setting中获取配置组装成dict(具体获取那些配置是optional字典中key) for name, setting_name in optional.items(): val = settings.get(setting_name) if val: kwargs[name] = val
# Support serializer as a path to a module. if isinstance(kwargs.get('serializer'), six.string_types): kwargs['serializer'] = importlib.import_module(kwargs['serializer']) # 或得一个Redis连接 server = connection.from_settings(settings) # Ensure the connection is working. server.ping()
return cls(server=server, **kwargs)
@classmethod def from_crawler(cls, crawler): instance = cls.from_settings(crawler.settings) # FIXME: for now, stats are only supported from this constructor instance.stats = crawler.stats return instance
def open(self, spider): self.spider = spider
try: # 根据self.queue_cls这个可以导入的类 实例化一个队列 self.queue = load_object(self.queue_cls)( server=self.server, spider=spider, key=self.queue_key % {'spider': spider.name}, serializer=self.serializer, ) except TypeError as e: raise ValueError("Failed to instantiate queue class '%s': %s", self.queue_cls, e)
if self.flush_on_start: self.flush() # notice if there are requests already in the queue to resume the crawl if len(self.queue): spider.log("Resuming crawl (%d requests scheduled)" % len(self.queue))
# 在Redis有序集合中数值越小优先级越高(就是会被放在顶层)所以这个位置是取得 相反数 score = -request.priority # We don't use zadd method as the order of arguments change depending on # whether the class is Redis or StrictRedis, and the option of using # kwargs only accepts strings, not bytes. # ZADD 是添加进有序集合 self.server.execute_command('ZADD', self.key, score, data)
defpop(self, timeout=0): """ Pop a request timeout not support in this queue class 有序集合不支持超时所以就木有使用timeout了 这个timeout就是挂羊头卖狗肉 """ """从有序集合中取出一个Request""" # use atomic range/remove using multi/exec """使用multi的原因是为了将获取Request和删除Request合并成一个操作(原子性的)在获取到一个元素之后 删除它,因为有序集合 不像list 有pop 这种方式啊""" pipe = self.server.pipeline() pipe.multi() # 取出 顶层第一个 # zrange :返回有序集 key 中,指定区间内的成员。0,0 就是第一个了 # zremrangebyrank:移除有序集 key 中,指定排名(rank)区间内的所有成员 0,0也就是第一个了 # 更多请参考Redis官方文档 pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0) results, count = pipe.execute() if results: return self._decode_request(results[0])
logger.info('This is a log info') logger.debug('Debugging') logger.warning('Warning exists') logger.info('Finish')
在这里我们首先引入了 logging 模块,然后进行了一下基本的配置,这里通过 basicConfig 配置了 level 信息和 format 信息,这里 level 配置为 INFO 信息,即只输出 INFO 级别的信息,另外这里指定了 format 格式的字符串,包括 asctime、name、levelname、message 四个内容,分别代表运行时间、模块名称、日志级别、日志内容,这样输出内容便是这四者组合而成的内容了,这就是 logging 的全局配置。 接下来声明了一个 Logger 对象,它就是日志输出的主类,调用对象的 info() 方法就可以输出 INFO 级别的日志信息,调用 debug() 方法就可以输出 DEBUG 级别的日志信息,非常方便。在初始化的时候我们传入了模块的名称,这里直接使用 name 来代替了,就是模块的名称,如果直接运行这个脚本的话就是 main,如果是 import 的模块的话就是被引入模块的名称,这个变量在不同的模块中的名字是不同的,所以一般使用 name 来表示就好了,再接下来输出了四条日志信息,其中有两条 INFO、一条 WARNING、一条 DEBUG 信息,我们看下输出结果:
1 2 3
2018-06-0313:42:43,526 - __main__ - INFO - This is a log info 2018-06-0313:42:43,526 - __main__ - WARNING - Warning exists 2018-06-0313:42:43,526 - __main__ - INFO - Finish
2018-06-0314:53:36,467 - __main__ - INFO - This is a log info 2018-06-0314:53:36,468 - __main__ - WARNING - Warning exists 2018-06-0314:53:36,468 - __main__ - INFO - Finish
2018-06-0315:13:44,895 - __main__ - INFO - This is a log info 2018-06-0315:13:44,947 - __main__ - WARNING - Warning exists 2018-06-0315:13:44,949 - __main__ - INFO - Finish
2018-06-0316:55:56,259 - main - INFO - Main Info 2018-06-0316:55:56,259 - main - ERROR - Main Error 2018-06-0316:55:56,259 - main.core - INFO - Core Info 2018-06-0316:55:56,259 - main.core - ERROR - Core Error
try: result = 5 / 0 except Exception as e: # bad logging.error('Error: %s', e) # good logging.error('Error', exc_info=True) # good logging.exception('Error')
上市了!")



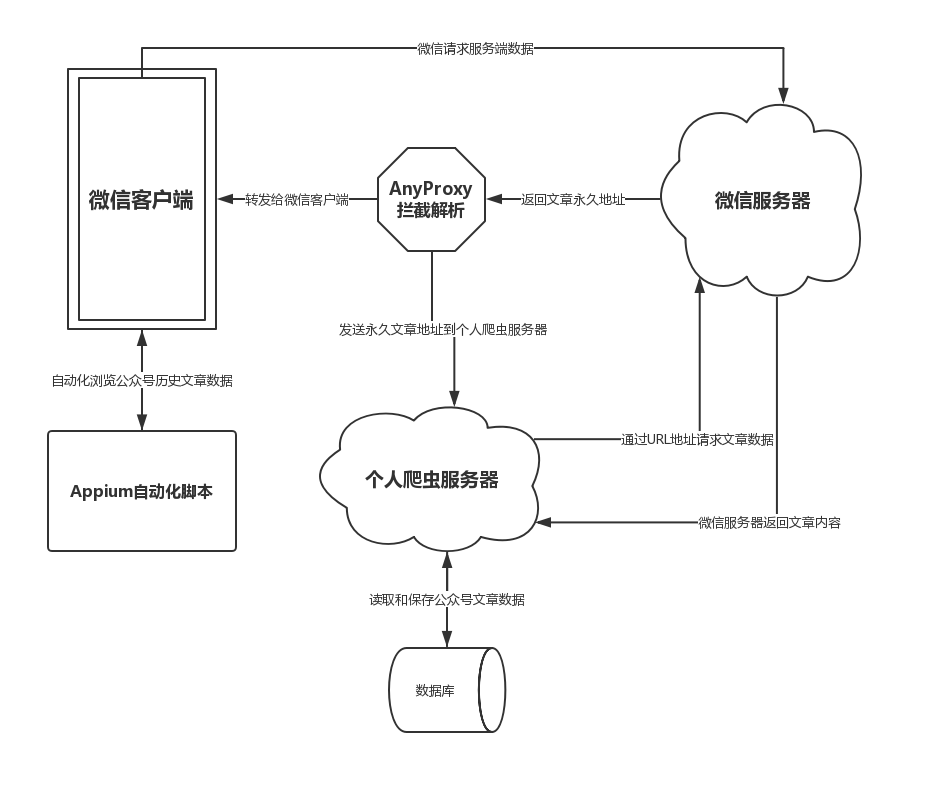

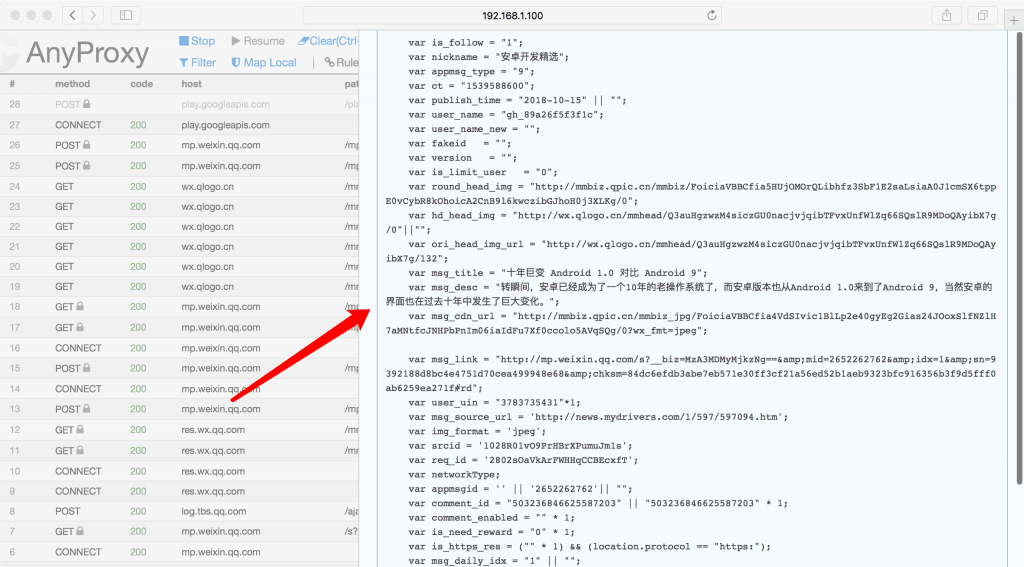

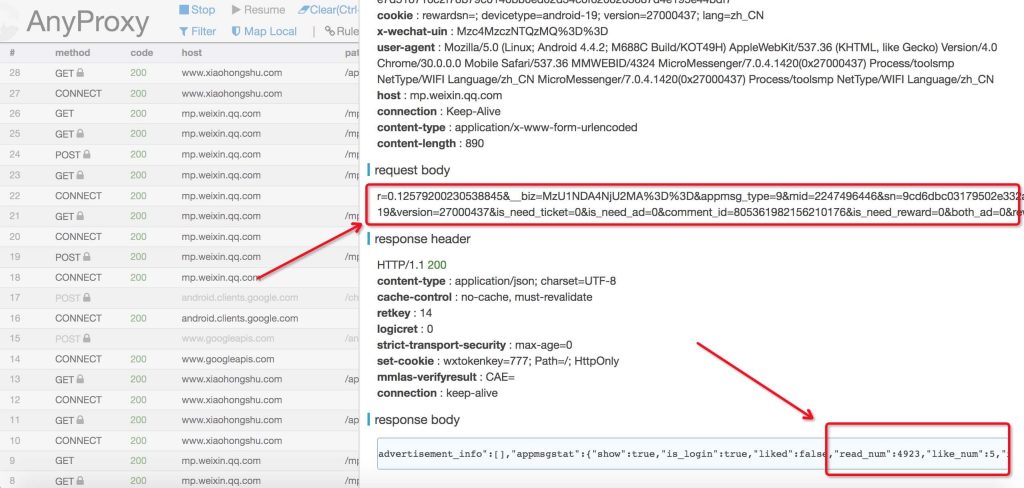











 可以看到图中有一个初始滑块,有一个目标滑块,如果把初始滑块拖动到目标滑块上才能校验成功,然后下方再打印拖动的轨迹,包含它的 x、y 坐标。 有了这些内容之后,就可以放到表单里面进行提交了,轨迹数据可以自行加密处理并校验来判断其是否合法。
可以看到图中有一个初始滑块,有一个目标滑块,如果把初始滑块拖动到目标滑块上才能校验成功,然后下方再打印拖动的轨迹,包含它的 x、y 坐标。 有了这些内容之后,就可以放到表单里面进行提交了,轨迹数据可以自行加密处理并校验来判断其是否合法。 可以看到训练和验证的 Loss 都被记录下来,并化成了图表展示。而这些东西我们配置过吗?没有,因为框架封装好了。 好,现在模型有了,我们要拿来做预测咋做呢?又得构建一边图,又得重新加载模型,又得准备数据,又得切分数据等等,还是麻烦,并没有,这里只需要这么定义就好了,定义 infer.py 如下:
可以看到训练和验证的 Loss 都被记录下来,并化成了图表展示。而这些东西我们配置过吗?没有,因为框架封装好了。 好,现在模型有了,我们要拿来做预测咋做呢?又得构建一边图,又得重新加载模型,又得准备数据,又得切分数据等等,还是麻烦,并没有,这里只需要这么定义就好了,定义 infer.py 如下: 模型便可以输出对应的情绪类型和情绪分布:
模型便可以输出对应的情绪类型和情绪分布: 它的定义域是全体实数,值域是 (0, 1),当自变量小于 -5 的时候,其值就趋近于 0,当自变量大于 5 的时候,其值就趋近于 1,当自变量为 0 的时候,其值就等于 1/2。 所以我们如果在线性回归模型的基础上加一层 Sigmoid 函数,结果不就可以被转化为 0 到 1 了吗?这就很自然而然地转化为了一个分类模型。 我们知道,线性回归模型的表达形式是这样的: 如果我们在它的基础上加一层 Sigmoid 函数,其表达式就变成了: 好,现在我们来考虑下这个表达式表达的什么意思。 我们举例来说吧,如果这个函数的输出结果为 1,那么我们肯定认为结果为“是”。如果输出结果为 0 呢?我们就当然认为结果为 “否”了,但如果输出结果为 0.5 呢?我们只能模棱两可,此时我们既可以判断为“是”,也可以判断为“否”,但恰好为 0.5 的概率太小了,多多少少也有点偏差吧。所以如果输出结果为 0.51,那么我们怎么认为?我们认为“是”的概率会更大,否的概率更小,概率是多少?0.49。如果输出结果是 0.95 呢?“是”的概率是多少?不用多说,必然是 0.95。 因此,我们可以看出来,函数输出的结果就代表了预测为“是”的概率,也就是真实结果为 1 的概率。我们用公式表达下,这里我们用 $ h{theta}(x) $ 表示预测结果,因此对于输入 x,分类类别为 1 和 0 的概率分别为: $$ \begin{cases} P(y = 1|x;\theta) = h{\theta}(x) \\\\ P(y = 0|x;\theta) = 1 - h{\theta}(x) \end{cases} J(\theta) = \dfrac{1}{2m}\sum{i=1}^{m}(h\theta(x^{(i)}) - y^{(i)})^2 Cost(h\theta(x), y) = \begin{cases} -log(h\theta(x)), y = 1 \\\\ -log(1- h\theta(x)), y = 0 \end{cases} Cost(h\theta(x), y) = -ylog(h\theta(x)) - (1-y)log(1-h\theta(x)) J(\theta) = \dfrac{1}{m}\sum{i=1}^{m}Cost(h\theta(x^{(i)}), y^{(i)})\\\\ = -\dfrac{1}{m}\sum{i=1}^{m}[y^{(i)}log(h*\theta(x^{(i)})) + (1-y^{(i)})log(1-h_\theta(x^{(i)}))] $$ 和线性回归类似,这次我们的目的就是找到 $ theta $,使得 $ J(theta) $ 最小。
它的定义域是全体实数,值域是 (0, 1),当自变量小于 -5 的时候,其值就趋近于 0,当自变量大于 5 的时候,其值就趋近于 1,当自变量为 0 的时候,其值就等于 1/2。 所以我们如果在线性回归模型的基础上加一层 Sigmoid 函数,结果不就可以被转化为 0 到 1 了吗?这就很自然而然地转化为了一个分类模型。 我们知道,线性回归模型的表达形式是这样的: 如果我们在它的基础上加一层 Sigmoid 函数,其表达式就变成了: 好,现在我们来考虑下这个表达式表达的什么意思。 我们举例来说吧,如果这个函数的输出结果为 1,那么我们肯定认为结果为“是”。如果输出结果为 0 呢?我们就当然认为结果为 “否”了,但如果输出结果为 0.5 呢?我们只能模棱两可,此时我们既可以判断为“是”,也可以判断为“否”,但恰好为 0.5 的概率太小了,多多少少也有点偏差吧。所以如果输出结果为 0.51,那么我们怎么认为?我们认为“是”的概率会更大,否的概率更小,概率是多少?0.49。如果输出结果是 0.95 呢?“是”的概率是多少?不用多说,必然是 0.95。 因此,我们可以看出来,函数输出的结果就代表了预测为“是”的概率,也就是真实结果为 1 的概率。我们用公式表达下,这里我们用 $ h{theta}(x) $ 表示预测结果,因此对于输入 x,分类类别为 1 和 0 的概率分别为: $$ \begin{cases} P(y = 1|x;\theta) = h{\theta}(x) \\\\ P(y = 0|x;\theta) = 1 - h{\theta}(x) \end{cases} J(\theta) = \dfrac{1}{2m}\sum{i=1}^{m}(h\theta(x^{(i)}) - y^{(i)})^2 Cost(h\theta(x), y) = \begin{cases} -log(h\theta(x)), y = 1 \\\\ -log(1- h\theta(x)), y = 0 \end{cases} Cost(h\theta(x), y) = -ylog(h\theta(x)) - (1-y)log(1-h\theta(x)) J(\theta) = \dfrac{1}{m}\sum{i=1}^{m}Cost(h\theta(x^{(i)}), y^{(i)})\\\\ = -\dfrac{1}{m}\sum{i=1}^{m}[y^{(i)}log(h*\theta(x^{(i)})) + (1-y^{(i)})log(1-h_\theta(x^{(i)}))] $$ 和线性回归类似,这次我们的目的就是找到 $ theta $,使得 $ J(theta) $ 最小。 《Python 基础教程(第 3 版)》/ 豆瓣 8.0 / 2018-2-1 出版 / [挪] 海特兰德
《Python 基础教程(第 3 版)》/ 豆瓣 8.0 / 2018-2-1 出版 / [挪] 海特兰德 .jpg) 《Python 编程快速上手》/ 豆瓣 9.0 / 2016-7-1 出版 / [美] 思维加特
《Python 编程快速上手》/ 豆瓣 9.0 / 2016-7-1 出版 / [美] 思维加特  《笨办法学 Python3》/ 豆瓣 8.4 / 2018-6-1 出版 / [美] 泽德
《笨办法学 Python3》/ 豆瓣 8.4 / 2018-6-1 出版 / [美] 泽德 
 《Python Cookbook 中文版》/ 豆瓣 9.2 / 2015-5-1 出版 / [美] 比斯利
《Python Cookbook 中文版》/ 豆瓣 9.2 / 2015-5-1 出版 / [美] 比斯利  《Effective Python》/ 豆瓣 9.0 / 2016-1-18 出版 / [美] 斯拉特金
《Effective Python》/ 豆瓣 9.0 / 2016-1-18 出版 / [美] 斯拉特金  《Python 编程之美》/ 豆瓣 8.4 / 2018-8-1 出版 / [美] 肯尼思·赖茨 Kenneth Reitz
《Python 编程之美》/ 豆瓣 8.4 / 2018-8-1 出版 / [美] 肯尼思·赖茨 Kenneth Reitz  《Python 高性能编程》/ 豆瓣 7.2 / 2017-7-1 出版 / [美] 戈雷利克
《Python 高性能编程》/ 豆瓣 7.2 / 2017-7-1 出版 / [美] 戈雷利克 
.jpg) 《Python3 网络爬虫开发实战》/ 豆瓣 9.0 / 2018-4-1 出版 / 崔庆才
《Python3 网络爬虫开发实战》/ 豆瓣 9.0 / 2018-4-1 出版 / 崔庆才  数据分析 《利用 Python 进行数据分析(第 2 版)》/ 豆瓣 8.5 / 2018-7-30 出版 / [美] 麦金尼
数据分析 《利用 Python 进行数据分析(第 2 版)》/ 豆瓣 8.5 / 2018-7-30 出版 / [美] 麦金尼 .jpg) 《对比 Excel,轻松学习 Python 数据分析》/ 豆瓣 7.8 / 2019-2-1 出版 / 张俊红
《对比 Excel,轻松学习 Python 数据分析》/ 豆瓣 7.8 / 2019-2-1 出版 / 张俊红  《Python 数据分析与挖掘实战》/ 豆瓣 7.8 / 2016-1-1 出版 / 张良均
《Python 数据分析与挖掘实战》/ 豆瓣 7.8 / 2016-1-1 出版 / 张良均 
.jpg) 《白话深度学习与 TensorFlow》/ 豆瓣 7.1 / 2017-7-31 出版 / 高扬
《白话深度学习与 TensorFlow》/ 豆瓣 7.1 / 2017-7-31 出版 / 高扬  《机器学习》/ 豆瓣 8.7 / 2016-1-1 出版 / 周志华
《机器学习》/ 豆瓣 8.7 / 2016-1-1 出版 / 周志华  《Python 机器学习基础教程》/ 豆瓣 8.2 / 2018-1-1 出版 / [德] 穆勒
《Python 机器学习基础教程》/ 豆瓣 8.2 / 2018-1-1 出版 / [德] 穆勒  《Python 深度学习》/ 豆瓣 9.6 / 2018-8-1 出版 / [美] 肖莱
《Python 深度学习》/ 豆瓣 9.6 / 2018-8-1 出版 / [美] 肖莱  《Python 神经网络编程》/ 豆瓣 9.0 / 2018-4-1 出版 / [英] 拉希德
《Python 神经网络编程》/ 豆瓣 9.0 / 2018-4-1 出版 / [英] 拉希德 
 《深入浅出 Vue.js》/ 新书 / 2018-3-1 出版 / 刘博文
《深入浅出 Vue.js》/ 新书 / 2018-3-1 出版 / 刘博文 
 《Flask Web 开发(第 2 版)》/ 豆瓣 9.4 / 2018-8-1 出版 / [美] 格雷贝格
《Flask Web 开发(第 2 版)》/ 豆瓣 9.4 / 2018-8-1 出版 / [美] 格雷贝格 .jpg) 《深入浅出 Docker》/ 豆瓣 8.4 / 2019-4-1 出版 / [英] 波尔顿
《深入浅出 Docker》/ 豆瓣 8.4 / 2019-4-1 出版 / [英] 波尔顿  《深入理解 Kafka》/ 新书 / 2019-1-1 出版 / 朱忠华
《深入理解 Kafka》/ 新书 / 2019-1-1 出版 / 朱忠华  《Kubernetes 权威指南(第 4 版)》/ 新书 / 2018-5-1 出版 / 龚正
《Kubernetes 权威指南(第 4 版)》/ 新书 / 2018-5-1 出版 / 龚正 .jpg)
 《程序员的数学》/ 豆瓣 8.6 / 2016-6-25 出版 / [日] 结城浩
《程序员的数学》/ 豆瓣 8.6 / 2016-6-25 出版 / [日] 结城浩  《程序员修炼之道》/ 豆瓣 8.6 / 2011-1-1 出版 / [美] 亨特
《程序员修炼之道》/ 豆瓣 8.6 / 2011-1-1 出版 / [美] 亨特  《代码整洁之道》/ 豆瓣 8.6 / 2016-9-1 出版 / [美] 罗伯特
《代码整洁之道》/ 豆瓣 8.6 / 2016-9-1 出版 / [美] 罗伯特  《持续交付 2.0》/ 豆瓣 9.4 / 2019-1-1 出版 / 乔梁
《持续交付 2.0》/ 豆瓣 9.4 / 2019-1-1 出版 / 乔梁  《鸟哥的 Linux 私房菜(第 4 版)》/ 豆瓣 8.0 / 2018-11-1 出版 / 鸟哥
《鸟哥的 Linux 私房菜(第 4 版)》/ 豆瓣 8.0 / 2018-11-1 出版 / 鸟哥 .jpg) 《颈椎病康复指南》/ 豆瓣 8.6 / 2012-4-1 出版 / 陈选宁
《颈椎病康复指南》/ 豆瓣 8.6 / 2012-4-1 出版 / 陈选宁  以上便是我所推荐的书籍,数量有限,如果大家还有推荐的书籍,欢迎留言~
以上便是我所推荐的书籍,数量有限,如果大家还有推荐的书籍,欢迎留言~ 可以看到这是一个凸函数,竖轴代表损失函数的大小,横纵两轴代表 $ \theta_1 $ 和 $ \theta_2 $ 的变化,可见在中间的最低谷损失函数取得最小值,这时候损失函数在 $ \theta_1 $ 和 $ \theta_2 $ 上的导数都是 0,因此我们可以一步到位,直接用偏导置零的方式来求解损失函数取得最小值时的 $ \theta $ 值的大小。 所以我们可以先对每个 $ \theta $ 求解其偏导结果,这里 $ \theta $ 表示为 $ \theta_j $,代表 $ \theta $ 中的某一维: $$ \dfrac{\partial{J(\theta)}}{\partial{\theta_j}} = \dfrac{1}{2m} \dfrac{\partial({\sum{i=1}^{m}{(y^{(i)} - h{\theta}(x^{(i)}))^2}})}{\partial{\theta_j}} \\\\ =\dfrac{1}{m}\sum{i=1}^{m}((h{\theta}(x^{(i)}) - y^{(i)})x_j^{(i)}) \sum{i=1}^{m} {h{\theta}(x^{(i)})x_j^{(i)}} - \sum{i=1}^{m}y^{(i)}xj^{(i)} = 0 \theta_j = \theta_j - \alpha\dfrac{\partial{J(\theta)}}{\partial{\theta_j}} \\\\ = \theta_j - \dfrac{\alpha}{m}\sum{i=1}^{m}((h_{\theta}(x^{(i)}) - y^{(i)})x_j^{(i)}) $$ 这里 $ \alpha $ 就是学习率,$ \theta_j $ 每经过一步都会进行一次更新,得到新的结果,经过梯度下降过程,$ \theta_j $ 都会更新为使得梯度最小化的数值,最后就完成了 $ \theta $ 的求解。 以上便是线性回归的整个推导和求解过程。
可以看到这是一个凸函数,竖轴代表损失函数的大小,横纵两轴代表 $ \theta_1 $ 和 $ \theta_2 $ 的变化,可见在中间的最低谷损失函数取得最小值,这时候损失函数在 $ \theta_1 $ 和 $ \theta_2 $ 上的导数都是 0,因此我们可以一步到位,直接用偏导置零的方式来求解损失函数取得最小值时的 $ \theta $ 值的大小。 所以我们可以先对每个 $ \theta $ 求解其偏导结果,这里 $ \theta $ 表示为 $ \theta_j $,代表 $ \theta $ 中的某一维: $$ \dfrac{\partial{J(\theta)}}{\partial{\theta_j}} = \dfrac{1}{2m} \dfrac{\partial({\sum{i=1}^{m}{(y^{(i)} - h{\theta}(x^{(i)}))^2}})}{\partial{\theta_j}} \\\\ =\dfrac{1}{m}\sum{i=1}^{m}((h{\theta}(x^{(i)}) - y^{(i)})x_j^{(i)}) \sum{i=1}^{m} {h{\theta}(x^{(i)})x_j^{(i)}} - \sum{i=1}^{m}y^{(i)}xj^{(i)} = 0 \theta_j = \theta_j - \alpha\dfrac{\partial{J(\theta)}}{\partial{\theta_j}} \\\\ = \theta_j - \dfrac{\alpha}{m}\sum{i=1}^{m}((h_{\theta}(x^{(i)}) - y^{(i)})x_j^{(i)}) $$ 这里 $ \alpha $ 就是学习率,$ \theta_j $ 每经过一步都会进行一次更新,得到新的结果,经过梯度下降过程,$ \theta_j $ 都会更新为使得梯度最小化的数值,最后就完成了 $ \theta $ 的求解。 以上便是线性回归的整个推导和求解过程。 扫码关注[/caption] 更多精彩内容关注微信公众号:python 学习开发
扫码关注[/caption] 更多精彩内容关注微信公众号:python 学习开发 所以,求求你加个空格吧(逃。
所以,求求你加个空格吧(逃。 这里提供一些手动的解决方案,比如使用 JavaScript 添加标记,然后 CSS 控制标记的间距,解决方案可以参考:
这里提供一些手动的解决方案,比如使用 JavaScript 添加标记,然后 CSS 控制标记的间距,解决方案可以参考: 这个是我用 Vue.js 开发的,实际上就是用了 pangu.js 这个库实现的,原理非常简单,主要目的就是为了方便空格排版。 另外这个网站我也部署了一下,叫做:
这个是我用 Vue.js 开发的,实际上就是用了 pangu.js 这个库实现的,原理非常简单,主要目的就是为了方便空格排版。 另外这个网站我也部署了一下,叫做: 点击之后便可以看到一个可选功能,选择 OpenSSH 服务器即可,一般情况下是没有安装的。如果没有安装的话它会提示一个安装按钮,这里我已经安装好了,就提示了一个卸载按钮。
点击之后便可以看到一个可选功能,选择 OpenSSH 服务器即可,一般情况下是没有安装的。如果没有安装的话它会提示一个安装按钮,这里我已经安装好了,就提示了一个卸载按钮。  OK,有了它,直接点击安装即可完成 OpenSSH 服务器的安装。 当然如果你是想批量部署 Windows 服务器的话,当然是推荐使用 PowerShell 来自动化部署了。 首先需要用管理员身份启动 PowerShell,使用如下命令看一下,要确保 OpenSSH 可用于安装:
OK,有了它,直接点击安装即可完成 OpenSSH 服务器的安装。 当然如果你是想批量部署 Windows 服务器的话,当然是推荐使用 PowerShell 来自动化部署了。 首先需要用管理员身份启动 PowerShell,使用如下命令看一下,要确保 OpenSSH 可用于安装: OK,以后就可以非常轻松地用 SSH 连接我的 Windows 服务器了,爽歪歪,上面的需求也成功解决。 以上便是使用 SSH 来连接 Windows 服务器的方法,如果大家有需求可以试试。
OK,以后就可以非常轻松地用 SSH 连接我的 Windows 服务器了,爽歪歪,上面的需求也成功解决。 以上便是使用 SSH 来连接 Windows 服务器的方法,如果大家有需求可以试试。 然后由于我自己有一个域名,叫做 cuiqingcai.com,然后我就把它设置了二级域名解析,二级域名名称就叫做 love,域名最终就是 love.cuiqingcai.com。 最终的效果大家可以扫码或者复制链接查看一下最终的效果:
然后由于我自己有一个域名,叫做 cuiqingcai.com,然后我就把它设置了二级域名解析,二级域名名称就叫做 love,域名最终就是 love.cuiqingcai.com。 最终的效果大家可以扫码或者复制链接查看一下最终的效果: 感觉还可以吧?如果你也想送这样的礼物的话,可以根据我现有的代码来进行修改,我已经将源码放到 GitHub 了,地址为:
感觉还可以吧?如果你也想送这样的礼物的话,可以根据我现有的代码来进行修改,我已经将源码放到 GitHub 了,地址为: 其中心形线的解析方程为: 这个公式代表了绘制坐标点的 x、y 的解析方程,用代码表示出来就是:
其中心形线的解析方程为: 这个公式代表了绘制坐标点的 x、y 的解析方程,用代码表示出来就是: 里面上架了什么商品?洗水果服务?做饭刷碗服务?捏肩膀服务?还有自动哄老婆机?我惊了。 她把商品发给我,我好奇问她这是干嘛的。 她说:要获得我的洗水果服务,捏肩膀服务,只需要在我的小店里购买使用就好了(作掐腰状)!还有自动哄老婆机,你要惹我生气了,只需要购买一个自动哄老婆机,我就会不生气了!嘿嘿合不合算?
里面上架了什么商品?洗水果服务?做饭刷碗服务?捏肩膀服务?还有自动哄老婆机?我惊了。 她把商品发给我,我好奇问她这是干嘛的。 她说:要获得我的洗水果服务,捏肩膀服务,只需要在我的小店里购买使用就好了(作掐腰状)!还有自动哄老婆机,你要惹我生气了,只需要购买一个自动哄老婆机,我就会不生气了!嘿嘿合不合算?  我说:多少钱?999!这么贵的吗! 她说:当然不是啦,亲亲我们店里有活动的,使用优惠券满 999 减 998 呢,您是我的 VIP 唯一专属客户,我会给您发优惠券的呀,使用优惠券只需要一块钱就可以购买了。购买之后,您每次使用一张,我就可以给您洗水果、捏肩膀了!这个情人节的话呢,我要送亲亲 10 张!可省着点话,不能累到店长我啊! 哦哦,卧槽真牛逼啊!于是乎我就快快乐乐领取到了十张优惠券购买了女朋友的这些服务,等着时不时用一张,享受一下帝王级的待遇,美滋滋!哈哈~ 最后,祝大家情人节快乐!幸福!
我说:多少钱?999!这么贵的吗! 她说:当然不是啦,亲亲我们店里有活动的,使用优惠券满 999 减 998 呢,您是我的 VIP 唯一专属客户,我会给您发优惠券的呀,使用优惠券只需要一块钱就可以购买了。购买之后,您每次使用一张,我就可以给您洗水果、捏肩膀了!这个情人节的话呢,我要送亲亲 10 张!可省着点话,不能累到店长我啊! 哦哦,卧槽真牛逼啊!于是乎我就快快乐乐领取到了十张优惠券购买了女朋友的这些服务,等着时不时用一张,享受一下帝王级的待遇,美滋滋!哈哈~ 最后,祝大家情人节快乐!幸福!




 我们需要从页面中提取出标题、发布人、发布时间、发布内容、图片等内容。一般情况下我们需要怎么办?写规则。 那么规则都有什么呢?怼正则,怼 CSS 选择器,怼 XPath。我们需要对标题、发布时间、来源等内容做规则匹配,更有甚者再需要正则表达式来辅助一下。我们可能就需要用 re、BeautifulSoup、pyquery 等库来实现内容的提取和解析。 但如果我们有成千上万个不同样式的页面怎么办呢?它们来自成千上万个站点,难道我们还需要对他们一一写规则来匹配吗?这得要多大的工作量啊。另外这些万一弄不好还会解析有问题。比如正则表达式在某些情况下匹配不了了,CSS、XPath 选择器选错位了也会出现问题。 想必大家可能见过现在的浏览器有阅读模式,比如我们把这个页面用 Safari 浏览器打开,然后开启阅读模式,看看什么效果:
我们需要从页面中提取出标题、发布人、发布时间、发布内容、图片等内容。一般情况下我们需要怎么办?写规则。 那么规则都有什么呢?怼正则,怼 CSS 选择器,怼 XPath。我们需要对标题、发布时间、来源等内容做规则匹配,更有甚者再需要正则表达式来辅助一下。我们可能就需要用 re、BeautifulSoup、pyquery 等库来实现内容的提取和解析。 但如果我们有成千上万个不同样式的页面怎么办呢?它们来自成千上万个站点,难道我们还需要对他们一一写规则来匹配吗?这得要多大的工作量啊。另外这些万一弄不好还会解析有问题。比如正则表达式在某些情况下匹配不了了,CSS、XPath 选择器选错位了也会出现问题。 想必大家可能见过现在的浏览器有阅读模式,比如我们把这个页面用 Safari 浏览器打开,然后开启阅读模式,看看什么效果:  页面一下子变得非常清爽,只保留了标题和需要读的内容。原先页面多余的导航栏、侧栏、评论等等的统统都被去除了。它怎么做到的?难道是有人在里面写好规则了?那当然不可能的事。其实,这里面就用到了智能化解析了。 那么本篇文章,我们就来了解一下页面的智能化解析的相关知识。
页面一下子变得非常清爽,只保留了标题和需要读的内容。原先页面多余的导航栏、侧栏、评论等等的统统都被去除了。它怎么做到的?难道是有人在里面写好规则了?那当然不可能的事。其实,这里面就用到了智能化解析了。 那么本篇文章,我们就来了解一下页面的智能化解析的相关知识。 有人可能好奇为什么 Diffbot 这么厉害?我也查询了一番。Diffbot 自 2010 年以来就致力于提取 Web 页面数据,并提供许多 API 来自动解析各种页面。其中他们的算法依赖于自然语言技术、机器学习、计算机视觉、标记检查等多种算法,并且所有的页面都会考虑到当前页面的样式以及可视化布局,另外还会分析其中包含的图像内容、CSS 甚至 Ajax 请求。另外在计算一个区块的置信度时还考虑到了和其他区块的关联关系,基于周围的标记来计算每个区块的置信度。 总之,Diffbot 也是一直致力于这一方面的服务,整个 Diffbot 就是页面解析起家的,现在也一直专注于页面解析服务,准确率高也就不足为怪了。 但它们的算法开源了吗?很遗憾,并没有,而且我也没有找到相关的论文介绍它们自己的具体算法。 所以,如果想实现这么好的效果,那就使用它们家的服务就好了。 接下来的内容,我们就来说说如何使用 Diffbot 来进行页面的智能解析。另外还有 Readability 算法也非常值得研究,我会写专门的文章来介绍 Readability 及其与 Python 的对接使用。
有人可能好奇为什么 Diffbot 这么厉害?我也查询了一番。Diffbot 自 2010 年以来就致力于提取 Web 页面数据,并提供许多 API 来自动解析各种页面。其中他们的算法依赖于自然语言技术、机器学习、计算机视觉、标记检查等多种算法,并且所有的页面都会考虑到当前页面的样式以及可视化布局,另外还会分析其中包含的图像内容、CSS 甚至 Ajax 请求。另外在计算一个区块的置信度时还考虑到了和其他区块的关联关系,基于周围的标记来计算每个区块的置信度。 总之,Diffbot 也是一直致力于这一方面的服务,整个 Diffbot 就是页面解析起家的,现在也一直专注于页面解析服务,准确率高也就不足为怪了。 但它们的算法开源了吗?很遗憾,并没有,而且我也没有找到相关的论文介绍它们自己的具体算法。 所以,如果想实现这么好的效果,那就使用它们家的服务就好了。 接下来的内容,我们就来说说如何使用 Diffbot 来进行页面的智能解析。另外还有 Readability 算法也非常值得研究,我会写专门的文章来介绍 Readability 及其与 Python 的对接使用。 这时候我们可以看到,它帮我们提取出来了标题、发布时间、发布机构、发布机构链接、正文内容等等各种结果。而且目前来看都十分正确,时间也自动识别之后做了转码,是一个标准的时间格式。 接下来我们继续下滑,查看还有什么其他的字段,这里我们还可以看到有 html 字段,它和 text 不同的是,它包含了文章内容的真实 HTML 代码,因此图片也会包含在里面,如图所示:
这时候我们可以看到,它帮我们提取出来了标题、发布时间、发布机构、发布机构链接、正文内容等等各种结果。而且目前来看都十分正确,时间也自动识别之后做了转码,是一个标准的时间格式。 接下来我们继续下滑,查看还有什么其他的字段,这里我们还可以看到有 html 字段,它和 text 不同的是,它包含了文章内容的真实 HTML 代码,因此图片也会包含在里面,如图所示:  另外最后面还有 images 字段,他以列表形式返回了文章套图及每一张图的链接,另外还有文章的站点名称、页面所用语言等等结果,如图所示:
另外最后面还有 images 字段,他以列表形式返回了文章套图及每一张图的链接,另外还有文章的站点名称、页面所用语言等等结果,如图所示:  当然我们也可以选择 JSON 格式的返回结果,其内容会更加丰富,例如图片还返回了其宽度、高度、图片描述等等内容,另外还有各种其他的结果如面包屑导航等等结果,如图所示:
当然我们也可以选择 JSON 格式的返回结果,其内容会更加丰富,例如图片还返回了其宽度、高度、图片描述等等内容,另外还有各种其他的结果如面包屑导航等等结果,如图所示:  经过手工核对,发现其返回的结果都是完全正确的,准确率相当之高! 所以说,如果你对准确率要求没有那么非常非常严苛的情况下,使用 Diffbot 的服务可以帮助我们快速地提取页面中所需的结果,省去了我们绝大多数的手工劳动,可以说是非常赞了。 但是,我们也不能总在网页上这么试吧。其实 Diffbot 也提供了官方的 API 文档,让我们来一探究竟。
经过手工核对,发现其返回的结果都是完全正确的,准确率相当之高! 所以说,如果你对准确率要求没有那么非常非常严苛的情况下,使用 Diffbot 的服务可以帮助我们快速地提取页面中所需的结果,省去了我们绝大多数的手工劳动,可以说是非常赞了。 但是,我们也不能总在网页上这么试吧。其实 Diffbot 也提供了官方的 API 文档,让我们来一探究竟。
 后台源代码里面的
后台源代码里面的  从上面可以看出,生这个字变成了乱码,请大家特别注意箭头所指的数字。
从上面可以看出,生这个字变成了乱码,请大家特别注意箭头所指的数字。 和大众点评的反爬差不多,都是通过 css 搞得。
和大众点评的反爬差不多,都是通过 css 搞得。 而且还有 base64,直接进行解密,但是解密出来的其实是乱码,这个时候其实要做的很简单,把解密后的内容保存为.ttf格式即可。
而且还有 base64,直接进行解密,但是解密出来的其实是乱码,这个时候其实要做的很简单,把解密后的内容保存为.ttf格式即可。 很明显,每个字可以看到字形和字形编码。 观察现在箭头指的地方和前面箭头指的地方的数字是不是一样啊,没错,就是通过这种方法进行映射的。 所以我们现在的思路似乎就是在源代码里找到箭头指的数字,然后再来字体里找到后替换就行了。 恭喜你,如果你也是这么想的,那你就掉坑里了。 因为每次访问,字体字形是不变的,但字符的编码确是变化的。因此,我们需要根据每次访问,动态解析字体文件。 字体 1:
很明显,每个字可以看到字形和字形编码。 观察现在箭头指的地方和前面箭头指的地方的数字是不是一样啊,没错,就是通过这种方法进行映射的。 所以我们现在的思路似乎就是在源代码里找到箭头指的数字,然后再来字体里找到后替换就行了。 恭喜你,如果你也是这么想的,那你就掉坑里了。 因为每次访问,字体字形是不变的,但字符的编码确是变化的。因此,我们需要根据每次访问,动态解析字体文件。 字体 1:  所以想通过写死的方式也是行不通的。 这个时候我们就要对字体文件进行更深一步的研究了。 3、研究字体文件 刚刚的.ttf 文件我们是看不到内部的东西的,所以这个时候我们要对字体文件进行转换格式,将其转换为 xml 格式,然后来查看: 具体操作如下:
所以想通过写死的方式也是行不通的。 这个时候我们就要对字体文件进行更深一步的研究了。 3、研究字体文件 刚刚的.ttf 文件我们是看不到内部的东西的,所以这个时候我们要对字体文件进行转换格式,将其转换为 xml 格式,然后来查看: 具体操作如下:
 文件很长,我只截取了一部分。 仔细的观察一下,你会发现~这俩下面的 x,y,on 值都是一毛一样的。所以我们的思路就是以一个已知的字体文件为基本,然后将获取到的新的字体文件的每个文字对应的 x,y,on 值进行比较,如果相同,那么说明新的文字对就 可以在基础字体那里找到对应的文字,有点绕,下面举个小例子。 假设: “我” 在基本字体中的名为 uni1,对应的 x=1,y=1,n=1 新的字体文件中,一个名为 uni2 对应的 x,y, n 分别于上面的相等,那么这个时候就可以确定 uni2 对应的文字为”我”。 查资料的时候,发现在特殊情况下,有时候两个字体中的文字对应的 x,y 不相等,但是差距都是在某一个阈值之内,处理方法差不多,只不过上面是相等,这种情况下就是要比较一下。 其实,如果你用画图工具按照上面的 x 与 y 值把点给连起来,你会发现,就是汉字的字形~ 所以,到此总结一下:
文件很长,我只截取了一部分。 仔细的观察一下,你会发现~这俩下面的 x,y,on 值都是一毛一样的。所以我们的思路就是以一个已知的字体文件为基本,然后将获取到的新的字体文件的每个文字对应的 x,y,on 值进行比较,如果相同,那么说明新的文字对就 可以在基础字体那里找到对应的文字,有点绕,下面举个小例子。 假设: “我” 在基本字体中的名为 uni1,对应的 x=1,y=1,n=1 新的字体文件中,一个名为 uni2 对应的 x,y, n 分别于上面的相等,那么这个时候就可以确定 uni2 对应的文字为”我”。 查资料的时候,发现在特殊情况下,有时候两个字体中的文字对应的 x,y 不相等,但是差距都是在某一个阈值之内,处理方法差不多,只不过上面是相等,这种情况下就是要比较一下。 其实,如果你用画图工具按照上面的 x 与 y 值把点给连起来,你会发现,就是汉字的字形~ 所以,到此总结一下:
 这个网站点击鼠标右键审查元素,查看网页源代码是无法用的,但是这个好像只能防住小白啊,简单的按 F12 审查元素,CTRL+u 直接查看源代码(谷歌浏览器)。 这次的目的主要是为了获取下面的链接(重度打码)
这个网站点击鼠标右键审查元素,查看网页源代码是无法用的,但是这个好像只能防住小白啊,简单的按 F12 审查元素,CTRL+u 直接查看源代码(谷歌浏览器)。 这次的目的主要是为了获取下面的链接(重度打码)

 然,在搜资料的时候,你会发现,很多教程都是用的 selenium 之类的方法,效率太低,没有啥技术含量。 所以,这篇文章的面向的对象就是 PC 端的大众点评;目标是解决这种反爬虫措施,使用 requests 获取到干净正确的数据; 跟着我,绝不会让你失望。
然,在搜资料的时候,你会发现,很多教程都是用的 selenium 之类的方法,效率太低,没有啥技术含量。 所以,这篇文章的面向的对象就是 PC 端的大众点评;目标是解决这种反爬虫措施,使用 requests 获取到干净正确的数据; 跟着我,绝不会让你失望。 
 这张图片很重要,很重要,很重要,我们要的值,几乎都从这里匹配出来。 这里我们看到了“vxt20”这个变量对应的两个像素值,前面的是控制用哪个数字,后面的是控制用哪一段的数字集合,先记下,后面要用,同时这里的值应该是 6; 这里其实就是整个破解流程最关键的一步了。在这里我们看到了一个链接。 瞎猫当死耗子吧,点进去看看。
这张图片很重要,很重要,很重要,我们要的值,几乎都从这里匹配出来。 这里我们看到了“vxt20”这个变量对应的两个像素值,前面的是控制用哪个数字,后面的是控制用哪一段的数字集合,先记下,后面要用,同时这里的值应该是 6; 这里其实就是整个破解流程最关键的一步了。在这里我们看到了一个链接。 瞎猫当死耗子吧,点进去看看。  可以看到这里面的几个关键数字:font-size:字体大小;还有几个 y 的值,我到后面才知道原来这个 y 是个阈值,起的是个控制的作用。 所以,这一反爬的原理就是:
可以看到这里面的几个关键数字:font-size:字体大小;还有几个 y 的值,我到后面才知道原来这个 y 是个阈值,起的是个控制的作用。 所以,这一反爬的原理就是:.png)
 这里对主要的步骤代码进行解释, 如果你想获取更多的代码,请关注我的公众号,并发送 “大众点评”即可。。 1.获取 css_url 及 span 对应的 TAG 值;
这里对主要的步骤代码进行解释, 如果你想获取更多的代码,请关注我的公众号,并发送 “大众点评”即可。。 1.获取 css_url 及 span 对应的 TAG 值;



 市面上各种代理也是琳琅满目的说··· 相信大家最喜欢用的之一应该就是 某布云。 根据官网的显示他他家的代理是这个样子的:
市面上各种代理也是琳琅满目的说··· 相信大家最喜欢用的之一应该就是 某布云。 根据官网的显示他他家的代理是这个样子的:












 我实际输入的值全是 1, 然后都被加密了, 没办法,只能去找加密的方法了。 经过一番搜索过后,才发现,原来加密的算法就在源代码里面,这里截个图:
我实际输入的值全是 1, 然后都被加密了, 没办法,只能去找加密的方法了。 经过一番搜索过后,才发现,原来加密的算法就在源代码里面,这里截个图:  从这里就可以看到具体的算法名以及相关的参数了,你会说,这是什么算法我都不知道啊?搜啊,用关键词搜一下就能知道了。 同时,是不是觉得这个网站好傻逼,这不太简单了吗? 肯定不是!!! 这么简单,说明此处也是必有玄机!!! 至于什么玄机,到后面说,都是泪。
从这里就可以看到具体的算法名以及相关的参数了,你会说,这是什么算法我都不知道啊?搜啊,用关键词搜一下就能知道了。 同时,是不是觉得这个网站好傻逼,这不太简单了吗? 肯定不是!!! 这么简单,说明此处也是必有玄机!!! 至于什么玄机,到后面说,都是泪。 可以看到信息提示要刷新,但是当时是百思不得其解,为毛线要刷新? 困惑了一会之后,我再次从头走了一遍流程,这下我才发现,原来源代码里面的那个长长的数据是会改变的,直到这个时候,我才意识到为什么要我刷新。。。。。。 服务器啊,你就不能直接说参数错误吗?刷新你大爷啊。 果然,我还是太年轻啊。
可以看到信息提示要刷新,但是当时是百思不得其解,为毛线要刷新? 困惑了一会之后,我再次从头走了一遍流程,这下我才发现,原来源代码里面的那个长长的数据是会改变的,直到这个时候,我才意识到为什么要我刷新。。。。。。 服务器啊,你就不能直接说参数错误吗?刷新你大爷啊。 果然,我还是太年轻啊。 知道这个坑以后就好办了,用个正则匹配一下就行了,而结果也是对的:
知道这个坑以后就好办了,用个正则匹配一下就行了,而结果也是对的:





















 这个是监控服务器网速的最后成果,显示的是下载与上传的网速,单位为 M。爬虫的原理都是一样的,只不过将数据存到 InfluxDB 的方式不一样而已, 如下图。
这个是监控服务器网速的最后成果,显示的是下载与上传的网速,单位为 M。爬虫的原理都是一样的,只不过将数据存到 InfluxDB 的方式不一样而已, 如下图。
 点击 ADD DATA SOURCE,进行配置即可,如下图:
点击 ADD DATA SOURCE,进行配置即可,如下图:  其中,name 自行设定;Type 选择 InfluxDB;url 为默认的
其中,name 自行设定;Type 选择 InfluxDB;url 为默认的  接着点击下图中的 edit 进入编辑页面:
接着点击下图中的 edit 进入编辑页面: 
 从上图中可以发现:
从上图中可以发现: 因为是边看,边练习,然后翻译,所以个人理解可能有偏差,有错误的地方,请大家指正。 首先,这个库是用来处理一些嵌套的数据的,作者也在 PyCon 2018 上做了个分享,老美的 PyCon 还是有点质量的,不像国内的,搞的什么玩意。 视频地址:
因为是边看,边练习,然后翻译,所以个人理解可能有偏差,有错误的地方,请大家指正。 首先,这个库是用来处理一些嵌套的数据的,作者也在 PyCon 2018 上做了个分享,老美的 PyCon 还是有点质量的,不像国内的,搞的什么玩意。 视频地址:







 最后也是最重要的就是参与活动的地址了!!!快来扫码回复领取属于你的福利吧!!!
最后也是最重要的就是参与活动的地址了!!!快来扫码回复领取属于你的福利吧!!!

 要是我们能够多个Scrapy一起采集该多好啊 人多力量大。 很遗憾Scrapy官方并不支持多个同时采集一个站点,虽然官方给出一个方法: 将一个站点的分割成几部分 交给不同的scrapy去采集 似乎是个解决办法,但是很麻烦诶!毕竟分割很麻烦的哇 下面就改轮到我们的额主角Scrapy-Redis登场了!
要是我们能够多个Scrapy一起采集该多好啊 人多力量大。 很遗憾Scrapy官方并不支持多个同时采集一个站点,虽然官方给出一个方法: 将一个站点的分割成几部分 交给不同的scrapy去采集 似乎是个解决办法,但是很麻烦诶!毕竟分割很麻烦的哇 下面就改轮到我们的额主角Scrapy-Redis登场了! 
 这张图大家相信大家都很熟悉了。重点看一下SCHEDULER 1. 先来看看官方对于SCHEDULER的定义: SCHEDULER接受来自Engine的Requests,并将它们放入队列(可以按顺序优先级),以便在之后将其提供给Engine
这张图大家相信大家都很熟悉了。重点看一下SCHEDULER 1. 先来看看官方对于SCHEDULER的定义: SCHEDULER接受来自Engine的Requests,并将它们放入队列(可以按顺序优先级),以便在之后将其提供给Engine 








 视频教程链接:
视频教程链接:  微信二维码[/caption]
微信二维码[/caption]