在AI图像生成领域,Midjourney 的名字想必大家早已不陌生。它不仅仅是一个工具,更像是一个随时待命的“创意伙伴”,能够将一段段文字描述,迅速转化成质感细腻、创意十足的视觉画面。无论是概念设计、营销素材,还是艺术创作,Midjourney 都已成为许多人与项目背后的灵感来源。
现在,通过 Ace Data Cloud 提供的 Midjourney API,即可轻松集成这一流的AI能力。欢迎访问我们的平台官网 https://platform.acedata.cloud/ 了解更多。
我们为你整理了详细的集成文档,并在文末说明了费用与咨询方式,全程协助您快速落地。
Midjourney API 集成文档
本文档主要介绍 Midjourney API 中 Imagine 操作的使用流程,利用它我们可以轻松通过文本生成所需要的图像。
要使用 Midjourney Imagine API,首先可以到 Midjourney Imagine API[1] 页面点击「Acquire」按钮,获取请求所需要的凭证:

如果你尚未登录或注册,会自动跳转到登录页面邀请您来注册和登录,登录注册之后会自动返回当前页面。
在首次申请时会有免费额度赠送,可以免费使用该 API。
接下来就可以在界面上填写对应的内容,如图所示:
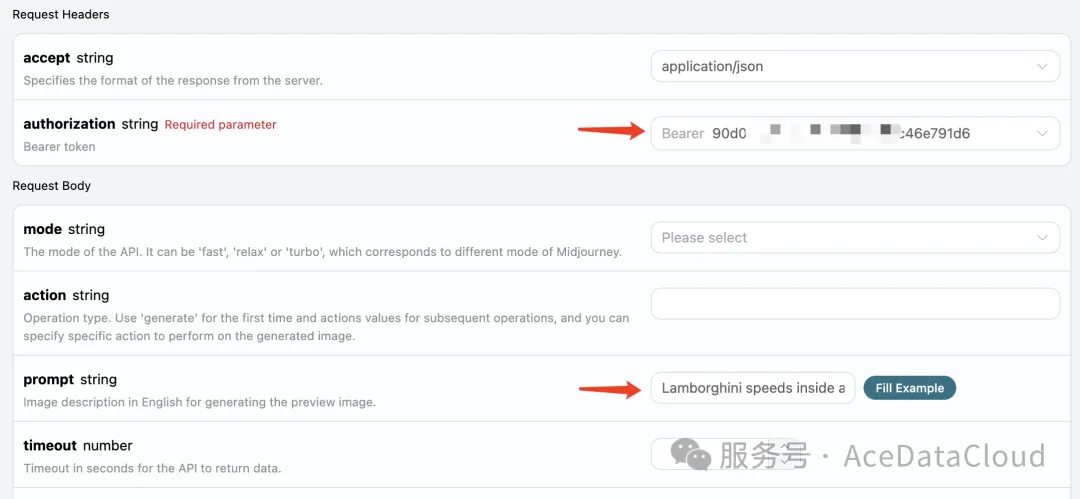
在第一次使用该接口时,我们至少需要填写两个内容,一个是 authorization,直接在下拉列表里面选择即可。另一个参数是 prompt, prompt 就是我们想生成的图片描述内容,建议用英文描述,画的图会更准确效果更好,这里我们用了示例内容 Lamborghini speeds inside a volcano,代表要画一个兰博基尼在火山飞驰。
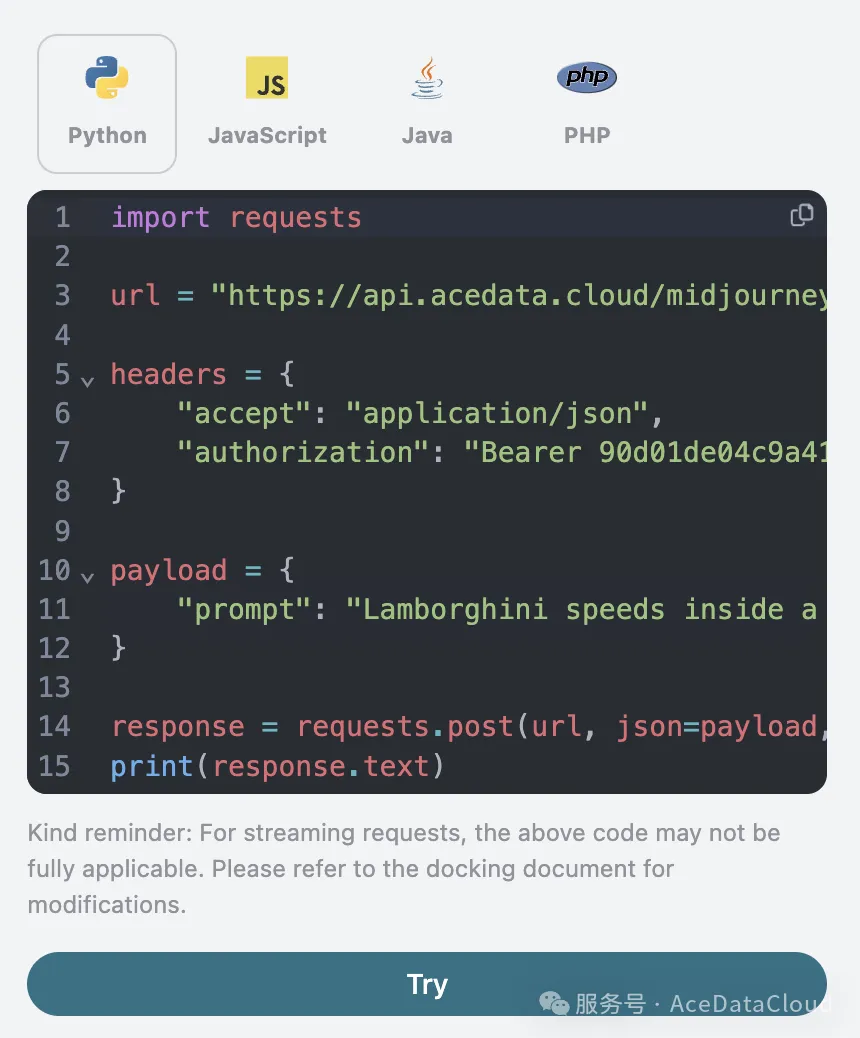
同时您可以注意到右侧有对应的调用代码生成,您可以复制代码直接运行,也可以直接点击「Try」按钮进行测试。
调用之后,我们发现返回结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
{
"image_url": "https://midjourney.cdn.acedata.cloud/attachments/1233387694839697411/1234197197067915365/36rgqit64j90qptsxnyq_Lamborghini_speeds_inside_a_volcano_id0494_f47263b6-ff92-44a3-88ee-51cf0e706aae.png?ex=662fdb36&is=662e89b6&hm=ca9be54907726937ed02517a13466bef2afb2825b7cda4b313de56a3c3310d0d&width=1024&height=1024",
"image_width": 1024,
"image_height": 1024,
"image_id": "1234197197067915365",
"raw_image_url": "https://midjourney.cdn.acedata.cloud/attachments/1233387694839697411/1234197197067915365/36rgqit64j90qptsxnyq_Lamborghini_speeds_inside_a_volcano_id0494_f47263b6-ff92-44a3-88ee-51cf0e706aae.png?ex=662fdb36&is=662e89b6&hm=ca9be54907726937ed02517a13466bef2afb2825b7cda4b313de56a3c3310d0d&",
"raw_image_width": 2048,
"raw_image_height": 2048,
"progress": 100,
"actions": [
"upscale1",
"upscale2",
"upscale3",
"upscale4",
"reroll",
"variation1",
"variation2",
"variation3",
"variation4"
],
"task_id": "1bae3bec-3ac4-4180-a148-74ee6cb68b98",
"success": true
}
|
返回结果一共有多个字段,介绍如下:
task_id,生成此图像任务的 ID,用于唯一标识此次图像生成任务。image_id,图片的唯一标识,在下次需要对图片进行变换操作时需要传此参数。image_url,缩略图的 URL,直接打开即可查看生成的效果。image_width:缩略图的像素宽度。image_height:缩略图的像素高度。raw_image_url:原图的 URL,和缩略图内容一样,但相比缩略图更加高清,加载速度会更慢一些。raw_image_width:原图的像素宽度。raw_image_height:原图的像素高度。actions,可以对生成的图片进行的进一步操作列表。这里一共列了 8 个,其中 upscale 代表放大,variation 代表变换。所以 upscale1 代表的就是对左上角第一张图片进行放大操作,variation3 就是代表根据左下角第三张图片进行变换操作。
打开 image_url 或者 raw_image_url 所对应的链接,可以发现如图所示。

可以看到,这里生成了一张 2x2 的预览图。到现在为止,第一次 API 调用就完成了。
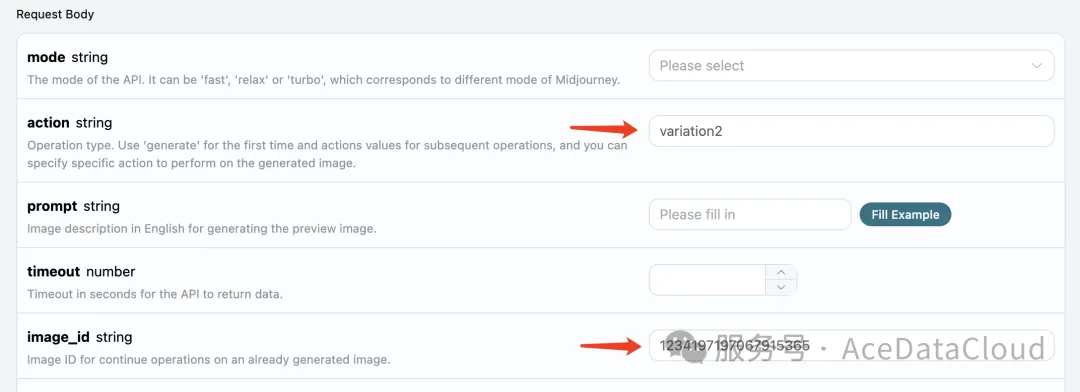
下面我们尝试针对当前生成的照片进行进一步的操作,比如我们觉得右上角第二张的图片还不错,但我们想进行一些变换微调,那么就可以进一步将 action 填写为 variation2,同时将 image_id 传递即可:
这时候得到的结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
{
"image_url": "https://midjourney.cdn.acedata.cloud/attachments/1233387694839697411/1234201336543969401/36rgqit64j90qptsxnyq_Lamborghini_speeds_inside_a_volcano_id0494_10dc56a7-ec16-4bac-878e-2338f2ae5f5d.png?ex=662fdf10&is=662e8d90&hm=9aec96bca35ae20b6f9ab536101b9c4ea255eb6216cbf7000ac554937da071f3&width=1024&height=1024",
"image_width": 1024,
"image_height": 1024,
"image_id": "1234201336543969401",
"raw_image_url": "https://midjourney.cdn.acedata.cloud/attachments/1233387694839697411/1234201336543969401/36rgqit64j90qptsxnyq_Lamborghini_speeds_inside_a_volcano_id0494_10dc56a7-ec16-4bac-878e-2338f2ae5f5d.png?ex=662fdf10&is=662e8d90&hm=9aec96bca35ae20b6f9ab536101b9c4ea255eb6216cbf7000ac554937da071f3&",
"raw_image_width": 2048,
"raw_image_height": 2048,
"progress": 100,
"actions": [
"upscale1",
"upscale2",
"upscale3",
"upscale4",
"reroll",
"variation1",
"variation2",
"variation3",
"variation4"
],
"task_id": "f4961620-1104-409f-9dc1-ba3ed15c2f4d",
"success": true
}
|
打开 image_url,新生成的图片如下所示:

可以看到,针对上一张右上角的图片,我们再次得到了四张类似的照片。
这时候我们可以挑选其中一张进行精细化地放大操作,比如选第四张,那就可以 action 传入 upscale4,通过 image_id 再次传入当前图像的 ID 即可。
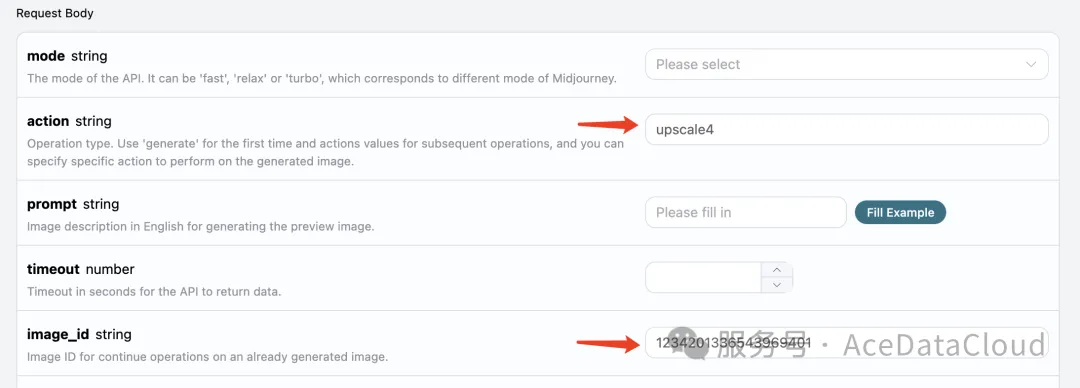
注意: upscale 操作相比 variation 来说,Midjourney 的耗时会更短一些。
返回结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
{
"image_url": "https://midjourney.cdn.acedata.cloud/attachments/1233387694839697411/1234202545208033400/36rgqit64j90qptsxnyq_Lamborghini_speeds_inside_a_volcano_id0494_34edc3f5-2bd0-4f5b-a372-03270b02289b.png?ex=662fe031&is=662e8eb1&hm=f8006c4d33a03dfd027dffe4eb46ab0d113a4910aef07497f0b335c8998b7858&width=512&height=512",
"image_width": 512,
"image_height": 512,
"image_id": "1234202545208033400",
"raw_image_url": "https://midjourney.cdn.acedata.cloud/attachments/1233387694839697411/1234202545208033400/36rgqit64j90qptsxnyq_Lamborghini_speeds_inside_a_volcano_id0494_34edc3f5-2bd0-4f5b-a372-03270b02289b.png?ex=662fe031&is=662e8eb1&hm=f8006c4d33a03dfd027dffe4eb46ab0d113a4910aef07497f0b335c8998b7858&",
"raw_image_width": 1024,
"raw_image_height": 1024,
"progress": 100,
"actions": [
"upscale_2x",
"upscale_4x",
"variation_subtle",
"variation_strong",
"zoom_out_2x",
"zoom_out_1_5x",
"pan_left",
"pan_right",
"pan_up",
"pan_down"
],
"task_id": "03f62b17-a6f1-4c8e-9b4d-1fc7bd5b1180",
"success": true
}
|
其中 image_url 如图所示:

这样我们就成功得到了一张兰博基尼的照片。
同时注意到 actions 里面又包含了几个可进行的操作,介绍如下:
upscale_2x:对画面放大 2 倍,得到 2 倍高清图。upscale_4x:对画面放大 4 倍,得到 4 倍高清图。zoom_out_2x:对画面进行缩小两倍操作(周围区域填充)。zoom_out_1_5x:对画面进行缩小 1.5 倍操作(周围区域填充)。pan_left:对画面进行左偏移操作。pan_right:对画面进行右便宜操作。pan_up:对画面进行上偏移操作。pan_down:对画面进行下偏移操作。
可以继续按照上述流程传入对应的变换指令进行连续生图操作。
该 API 也支持图像改写,俗称垫图,我们可以输入一张图片 URL 以及需要改写的描述文字,该 API 就可以返回改写后的图片。
注意:输入的图片 URL 需要是一张纯图片,不能是一个网页里面展示一张图片,否则无法进行图像改写。建议使用图床来上传获取图片的 URL。
例如,我们这里有一张公路落日的图片,公路旁边有一些树木和楼房,如图所示:

现在我们想在它的基础上改写成海滩旁边,同时放一辆汽车停在路边。我们就可以构造如下的 prompt:
可以看到,我们的 prompt 的最开头是一个 HTTPS 开头的图片链接,然后接着加一个空格,后面跟上 prompt 文字的内容。这里我们还用了额外的一些高级参数,如 —iw 2 来调整图片的权重。
我们可以将如上内容作为一个整体,传递给 prompt 字段,如图所示:
输出结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
{
"image_url": "https://midjourney.cdn.acedata.cloud/attachments/1234427310434947145/1234539663515975690/atmateosa5693_An_illustration_of_a_car_parked_on_the_beach_id26_cc8650ec-7e4b-4685-8911-78172430d8a7.png?ex=66311a28&is=662fc8a8&hm=c39707a1f22bc7f12874060ea6ed58ba37c188139ccc9a13c61ed9f37e66ea74&width=1456&height=816",
"image_width": 1456,
"image_height": 816,
"image_id": "1234539663515975690",
"raw_image_url": "https://midjourney.cdn.acedata.cloud/attachments/1234427310434947145/1234539663515975690/atmateosa5693_An_illustration_of_a_car_parked_on_the_beach_id26_cc8650ec-7e4b-4685-8911-78172430d8a7.png?ex=66311a28&is=662fc8a8&hm=c39707a1f22bc7f12874060ea6ed58ba37c188139ccc9a13c61ed9f37e66ea74&",
"raw_image_width": 2912,
"raw_image_height": 1632,
"progress": 100,
"actions": [
"upscale1",
"upscale2",
"upscale3",
"upscale4",
"reroll",
"variation1",
"variation2",
"variation3",
"variation4"
],
"task_id": "24a79e8b-a79d-471a-aef7-089dc0627ee8",
"success": true
}
|
这时候我们就得到了如下生成的图片:

可以看到,在原来的图片整体风格和构图不变的前提下,整个场景变成了海滩旁边,同时公路上还出现了汽车,这就是 Prompt with Image。
该 API 也支持图像融合,我们可以传入多张图片,以实现不同的图片融合效果。
比如说这里我们一共有两张图片,一张是一只玩具熊,另一张是一个电锯,分别如图所示:


现在我们想把二者融合起来,让这只熊拿着这个电锯,怎么做呢?
我们可以构造如下的 prompt:
可以发现,和 Image with Prompt 类似,我们这里将多张图片 URL 放在了 prompt 开头,并以空格分隔,最后再加上文字 prompt,将如上内容作为一个整体传递给 prompt 参数,运行效果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
{
"image_url": "https://midjourney.cdn.acedata.cloud/attachments/1234291876639674388/1234547236830973972/kcisok_The_bear_is_holding_the_chainsaw_id8873344_ad605bc4-ba19-4807-b94f-367dab672f7a.png?ex=66312136&is=662fcfb6&hm=0fb1e2261c9a30b04de9da9b23b7562eb73677f1bbda1fae52c7243b12d25aac&width=1024&height=1024",
"image_width": 1024,
"image_height": 1024,
"image_id": "1234547236830973972",
"raw_image_url": "https://midjourney.cdn.acedata.cloud/attachments/1234291876639674388/1234547236830973972/kcisok_The_bear_is_holding_the_chainsaw_id8873344_ad605bc4-ba19-4807-b94f-367dab672f7a.png?ex=66312136&is=662fcfb6&hm=0fb1e2261c9a30b04de9da9b23b7562eb73677f1bbda1fae52c7243b12d25aac&",
"raw_image_width": 2048,
"raw_image_height": 2048,
"progress": 100,
"actions": [
"upscale1",
"upscale2",
"upscale3",
"upscale4",
"reroll",
"variation1",
"variation2",
"variation3",
"variation4"
],
"task_id": "891f2645-ee15-4c7b-ac24-d98163c8e57e",
"success": true
}
|
我们就得到了如下结果:

可以看到,我们就成功实现了图片融合。
注意:图片融合最多可以支持 5 个图片 URL 作为输入,也就是最多支持 5 张图片融合,输入格式同上。
该 API 也支持图像的局部绘图功能,但只支持在上文内容下生成的图片,我们可以传入一张生成图片的的唯一ID,局部重绘的行为参数 action 以及需要重绘区域的掩码mask,以实现在改掩码区域进行重绘。
比如说这里我们有一张生成关于猫的图片:

现在我们想对这个猫脸进行重绘,怎么做呢?
首先我们需要获取该区域的掩码mask,此mask是通过灰度图片进行Base64编码得来的,下面提供一些获取掩码的工具代码:
Python获取掩码示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
|
import sys
import os
from PySide6.QtWidgets import *
from PySide6.QtGui import QPainter, QMouseEvent, QPen, QColor, QImage
from PySide6.QtCore import Qt, QPoint
class DrawingWidget(QWidget):
def __init__(self, imagePath):
super().__init__()
self.setAttribute(Qt.WA_StaticContents)
self.background_image = QImage(imagePath)
imageSize = self.background_image.size()*0.8
self.setFixedSize(imageSize)
self.foreground_image = QImage(self.size(), QImage.Format_ARGB32)
self.foreground_image.fill(Qt.transparent)
self.drawing = False
self.lastPoint = QPoint()
self.pen_color = QColor(255, 255, 255, 255)
self.pen_size = 50
def set_pen_size(self, size):
self.pen_size = size
def mousePressEvent(self, event: QMouseEvent):
if event.button() == Qt.LeftButton:
self.drawing = True
self.lastPoint = event.pos()
def mouseMoveEvent(self, event: QMouseEvent):
if event.buttons() & Qt.LeftButton and self.drawing:
painter = QPainter(self.foreground_image)
painter.setRenderHint(QPainter.Antialiasing, True)
pen = QPen(self.pen_color, self.pen_size,
Qt.SolidLine, Qt.RoundCap, Qt.RoundJoin)
painter.setPen(pen)
painter.drawLine(self.lastPoint, event.pos())
self.lastPoint = event.pos()
self.update()
def mouseReleaseEvent(self, event: QMouseEvent):
if event.button() == Qt.LeftButton and self.drawing:
self.drawing = False
def paintEvent(self, event):
canvasPainter = QPainter(self)
canvasPainter.drawImage(
self.rect(), self.background_image, self.background_image.rect())
canvasPainter.drawImage(
self.rect(), self.foreground_image, self.foreground_image.rect())
def save_image(self, path):
self.foreground_image.save(path)
class MainWindow(QDialog):
def __init__(self, imagePath):
super().__init__()
self.setWindowTitle("mask tool")
self.drawing_widget = DrawingWidget(imagePath)
self.currentPath = os.getcwd().replace("\\", "/")
self.tempPath = self.currentPath + "/temp.jpg"
self.projectPath = ""
self.setDone = False
def init_ui(self):
layout = QVBoxLayout()
layout.addWidget(self.drawing_widget)
controls_layout = QHBoxLayout()
size_label = QLabel("pen size:")
controls_layout.addWidget(size_label)
self.size_slider = QSlider(Qt.Horizontal)
self.size_slider.setMinimum(100)
self.size_slider.setMaximum(400)
self.size_slider.setValue(400)
self.size_slider.valueChanged.connect(self.update_pen_size)
controls_layout.addWidget(self.size_slider)
self.lineEdit_addPromp = QLineEdit()
layout.addWidget(self.lineEdit_addPromp)
save_button = QPushButton(" Start partial redrawing ")
save_button.clicked.connect(self.save_image)
controls_layout.addWidget(save_button)
dont_button = QPushButton(" Cancel partial redraw ")
dont_button.clicked.connect(self.dont_image)
controls_layout.addWidget(dont_button)
layout.addLayout(controls_layout)
self.setLayout(layout)
def update_pen_size(self):
size = self.size_slider.value()
self.drawing_widget.set_pen_size(size)
def save_image(self):
tempImage = self.currentPath + "/temp.jpg"
self.drawing_widget.save_image(self.tempPath)
self.prompt = self.lineEdit_addPromp.text()
self.setDone = True
self.close()
def dont_image(self):
self.setDone = False
self.close()
def closeEvent(self, event):
if self.setDone:
pass
else:
self.setDone = False
event.accept()
if __name__ == '__main__':
imagePath = "test.png"
app = QApplication(sys.argv)
mainWindow = MainWindow(imagePath)
mainWindow.init_ui()
mainWindow.exec()
|
通过以上代码可以获得掩码图片,在这个过程中我们需要注意掩码图片必须与原图片一样的尺寸,然后掩码图片中白色的区域就是需要重绘的区域,下面展示猫图片需要重绘的掩码图片与原图的对比:
原图片:

掩码图片:

最后我们还需要将掩码图片转换为基于Base64的编码,接下来提供转换Base64编码的代码:
Python转换Base64示例代码:
1
2
3
4
5
6
7
8
9
10
11
|
import cv2
import base64
image_path = 'temp.jpg'
gray_image = cv2.imread(image_path)
_, buffer = cv2.imencode('.jpg', gray_image)
base64_encoded = base64.b64encode(buffer).decode('utf-8')
with open('grayscale_image_base64.txt', 'w') as f:
f.write(base64_encoded)
print("success!")
|
注意:上述 Python 代码描述了 mask 的生成过程,如果您要将其对接到您的产品中,请根据其原理编写对应语言的代码。
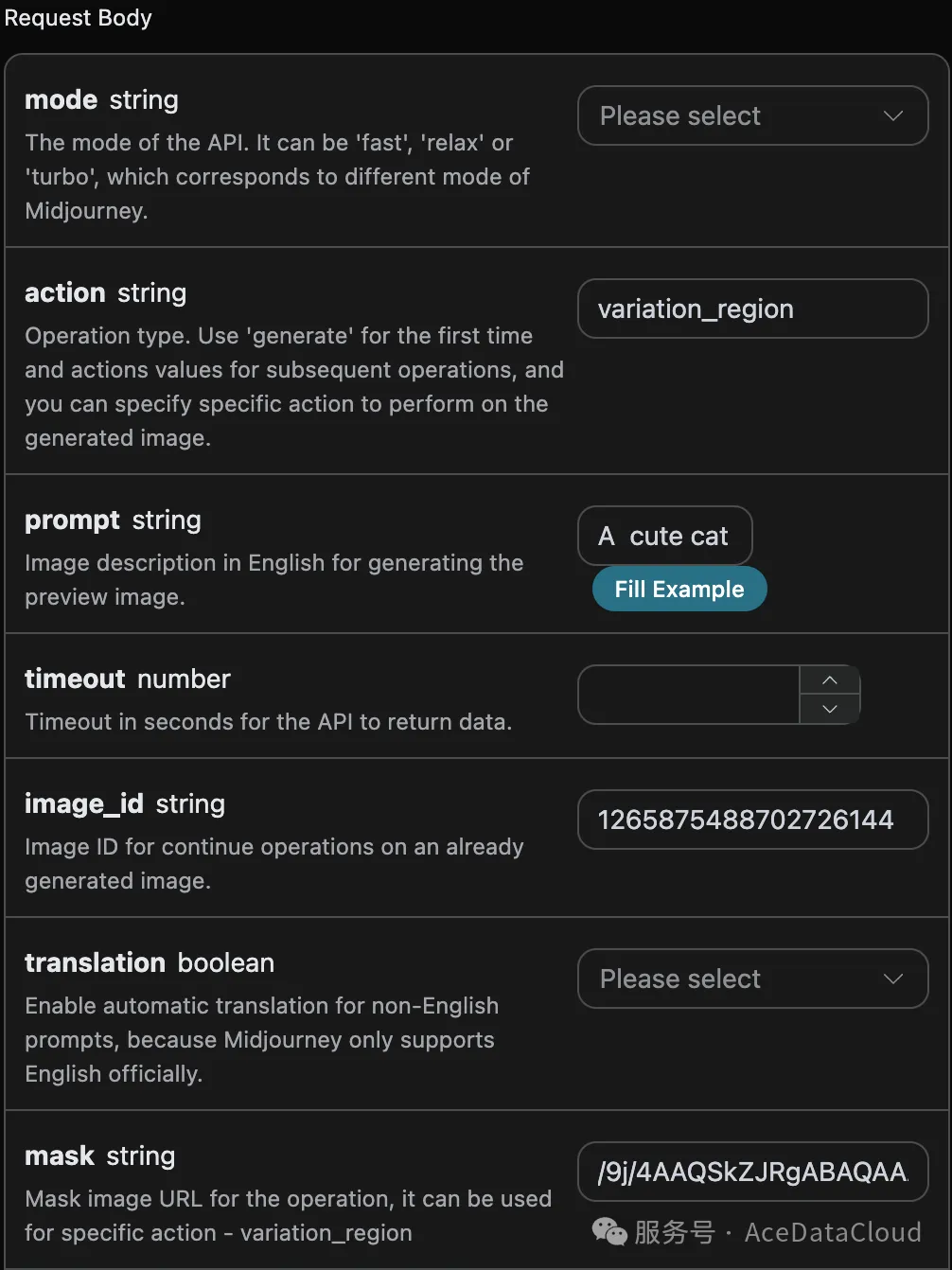
通过以上代码,我们获得了需要重绘的掩码 mask ,下面我们还需要需要将参数 action 设置为 variation_region ,生成图片的ID image_id (获取该参数参考上文的内容),以及传入对应的掩码 mask ,其它参数信息如下:
action:对图片进行操作的行为,此处为 variation_region ,表示对图片进行局部重绘。prompt:对图像进行局部重绘的描述词(可选参数)。image_id:图片的唯一标识,方便对图像进行局部重绘。mask:图片对应的掩码区域的base64编码(图片是上面image_id指定的)。
因此根据以上规则我们需要设置正确的的参数,参数 prompt 是一个非必填参数,这里为了方便对比将掩码区域的 prompt 设置为 A cute cat ,具体的参数设置如下图所示:
可以发现,在页面右侧已经自动生成了各种语言的代码,如图所示:
部分代码示例如下:
CURL
1
2
3
4
5
6
7
8
9
10
|
curl -X POST 'https:
-H 'accept: application/json' \
-H 'authorization: Bearer {token}' \
-H 'content-type: application/json' \
-d '{
"prompt": "A cute cat ",
"action": "variation_region",
"image_id": "1265875488702726144",
"mask": "/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAIBAQEBAQIBAQECAgICAgQDAgICAgUEBAMEBgUGBgYFBgKACiiigAooooAKKKKACiiigAooooAKKKKACiiigAooooAKKKKACiiigAooooAKKKKAP/Z"
}'
|
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import requests
url = "https://api.acedata.cloud/midjourney/imagine"
headers = {
"accept": "application/json",
"authorization": "Bearer {token}",
"content-type": "application/json"
}
payload = {
"prompt": "A cute cat ",
"action": "variation_region",
"image_id": "1265875488702726144",
"mask": "/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAIBAQEBAQIBAQECAgICAgQDAgICAgUEBAMEBgUGBgYFBgYGBwkIBgcJBwYGCAsICQoKCgoKBggLDAsKDAkKCgr/2wBDAQICAgICAgUDAwUKBwYHKACiiigAooooAKKKKACiiigAooo..."
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
|
请求成功后,API 将返回换脸后端图片结果信息。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
{
"image_url": "https://platform.cdn.acedata.cloud/midjourney/6c9450d8-1c22-4f85-a527-e7a7bfb4a61b.png?imageMogr2/thumbnail/!50p",
"image_width": 1024,
"image_height": 1024,
"actions": [
"upscale1",
"upscale2",
"upscale3",
"upscale4",
"reroll",
"variation1",
"variation2",
"variation3",
"variation4"
],
"raw_image_url": "https://platform.cdn.acedata.cloud/midjourney/6c9450d8-1c22-4f85-a527-e7a7bfb4a61b.png",
"raw_image_width": 2048,
"raw_image_height": 2048,
"progress": 100,
"image_id": "1265876571323891712",
"task_id": "6c9450d8-1c22-4f85-a527-e7a7bfb4a61b",
"success": true
}
|
可以发现这是对掩码区域的图像进行了重绘操作,返回的结果与上文的是一致的,结果如下图所示:

可以看到,我们就成功实现了对生成的图片的自定义区域进行局部重绘。
由于 Midjourney 生成图片需要等待一段时间,所以本 API 也默认设计为了长等待模式。但在部分场景下,长等待可能会带来一些额外的资源开销,因此本 API 也提供了异步 Webhook 回调的方式,当图片生成成功或失败时,其结果都会通过 HTTP 请求的方式发送到指定的 Webhook 回调 URL。回调 URL 接收到结果之后可以进行进一步的处理。
下面演示具体的调用流程。
首先,Webhook 回调是一个可以接收 HTTP 请求的服务,开发者应该替换为自己搭建的 HTTP 服务器的 URL。此处为了方便演示,使用一个公开的 Webhook 样例网站 https://webhook.site/[2],打开该网站即可得到一个 Webhook URL,如图所示:

将此 URL 复制下来,就可以作为 Webhook 来使用,此处的样例为 https://webhook.site/995d0a91-d737-40a7-a3b9-5baf68ed924c[3]。
接下来,我们可以设置字段 callback_url 为上述 Webhook URL,同时填入 prompt,如图所示:
点击测试之后会立即得到一个 task_id 的响应,用于标识当前生成任务的 ID,如图所示:
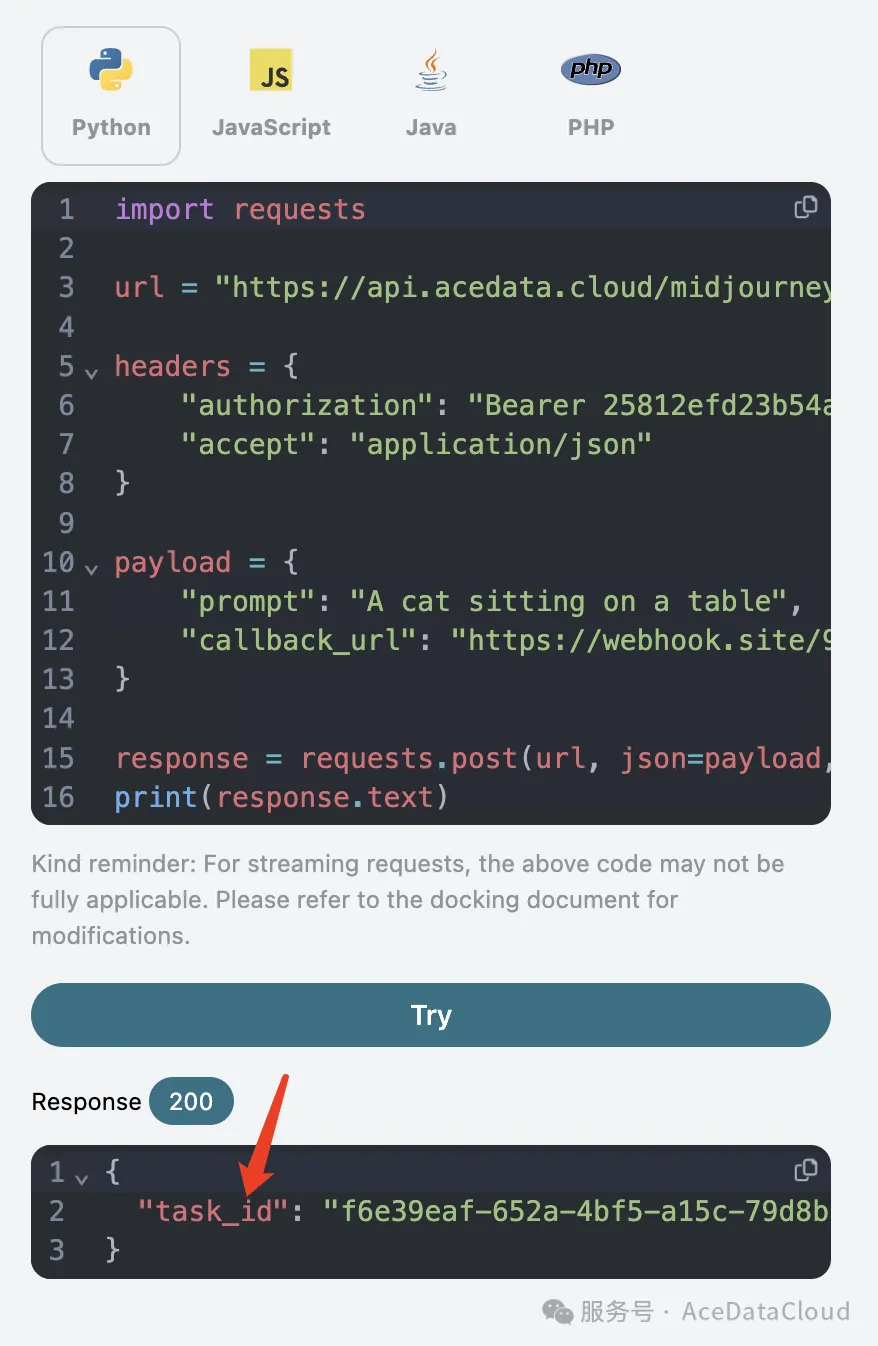
稍等片刻,等图片生成结束,可以发发现 Webhook URL 收到了一个 HTTP 请求,如图所示:
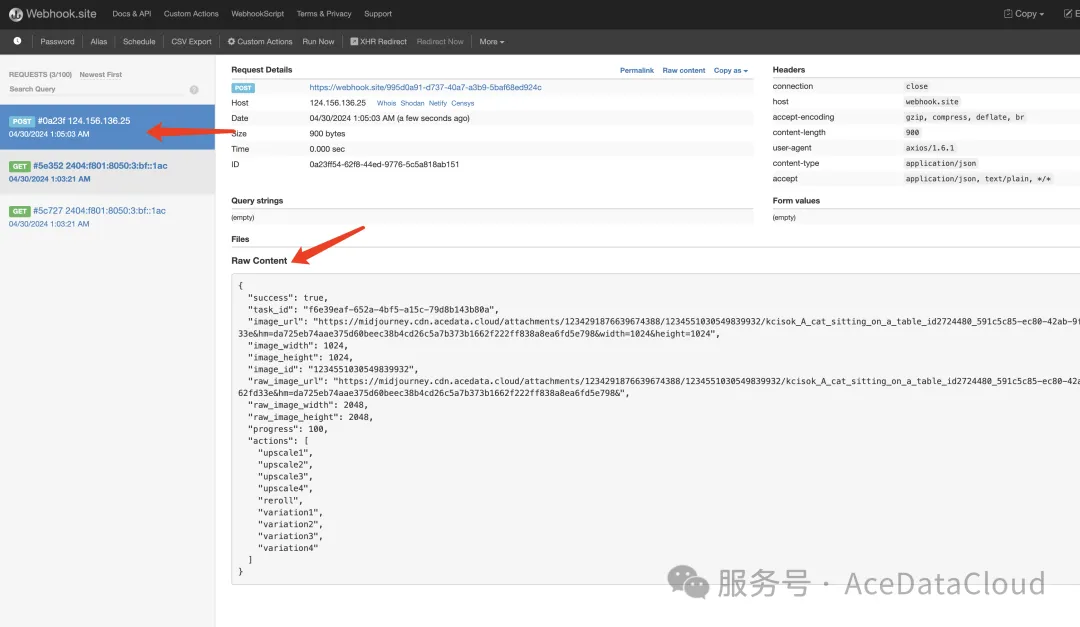
其结果就是当前任务的结果,内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
{
"success": true,
"task_id": "f6e39eaf-652a-4bf5-a15c-79d8b143b80a",
"image_url": "https://midjourney.cdn.acedata.cloud/attachments/1234291876639674388/1234551030549839932/kcisok_A_cat_sitting_on_a_table_id2724480_591c5c85-ec80-42ab-9fe5-9adfbed192e4.png?ex=663124be&is=662fd33e&hm=da725eb74aae375d60beec38b4cd26c5a7b373b1662f222ff838a8ea6fd5e798&width=1024&height=1024",
"image_width": 1024,
"image_height": 1024,
"image_id": "1234551030549839932",
"raw_image_url": "https://midjourney.cdn.acedata.cloud/attachments/1234291876639674388/1234551030549839932/kcisok_A_cat_sitting_on_a_table_id2724480_591c5c85-ec80-42ab-9fe5-9adfbed192e4.png?ex=663124be&is=662fd33e&hm=da725eb74aae375d60beec38b4cd26c5a7b373b1662f222ff838a8ea6fd5e798&",
"raw_image_width": 2048,
"raw_image_height": 2048,
"progress": 100,
"actions": [
"upscale1",
"upscale2",
"upscale3",
"upscale4",
"reroll",
"variation1",
"variation2",
"variation3",
"variation4"
]
}
|
其中 success 字段标识了该任务是否执行成功,如果执行成功,还会有同样的 actions, image_id, image_url 字段,和上文介绍的返回结果是一样的,另外还有 task_id 用于标识任务,以实现 Webhook 结果和最初 API 请求的关联。
如果图片生成失败,Webhook URL 则会收到类似如下内容:
1
2
3
4
5
6
7
8
|
{
"success": false,
"task_id": "7ba0feaf-d20b-4c22-a35a-31ec30fc7715",
"error": {
"code": "bad_request",
"message": "Unrecognized argument(s): `-c`, `x`"
}
}
|
这里的 success 字段会是 false,同时还会有 error.code 和 error.message 字段描述了任务错误的详情信息,Webhook 服务器根据对应的结果进行处理即可。
Midjourney 官方在生成图片的时候是有进度的,在最开始是一张模糊的照片,然后经过几次迭代之后,图片逐渐变得清晰,最后得到完整的图片。
所以,一张图片的生成过程大约可以分为「发送命令」->「开始生图(多次迭代逐渐清晰)」->「生图完毕」的阶段。
在没开启流式输出的情况下,本 API 从发起请求到返回结果,实际上是从上述「发送命令」->「生图完毕」的全过程,中间生图的过程也全被包含在里面,由于 Midjourney 本身生成图片速度较慢,整个过程大约需要等待一分钟或更久。
所以为了更好的用户体验,本 API 支持流式输出,即当「开始生图」的时候就开始返回结果,每当绘制进度有变化,就会流式将结果输出,直至生图结束。
如果想流式返回响应,可以更改请求头里面的 accept 参数,修改为 application/x-ndjson,不过调用代码需要有对应的更改才能支持流式响应。
Python 样例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import requests
url = 'https://api.acedata.cloud/midjourney/imagine'
headers = {
'content-type': 'application/json',
'accept': 'application/x-ndjson',
'authorization': 'Bearer {token}'
}
body = {
"prompt": "a beautiful cat --v 6"
}
r = requests.post(url, headers=headers, json=body, stream=True)
for line in r.iter_lines():
print(line.decode())
|
运行结果:
1
2
3
|
{"image_url":"https://midjourney.cdn.acedata.cloud/attachments/1234291876639674388/1234558451443699803/eae94f0f-0ba5-4b3c-9bad-59fb33ac2cbc_grid_0.webp?ex=66312ba7&is=662fda27&hm=4625d5f12158bffc07c4faaf6ce75af6f1396122f148b33b91f3e20b48fecc8b&width=256&height=256","image_width":256,"image_height":256,"image_id":"1234558451443699803","raw_image_url":"https://midjourney.cdn.acedata.cloud/attachments/1234291876639674388/1234558451443699803/eae94f0f-0ba5-4b3c-9bad-59fb33ac2cbc_grid_0.webp?ex=66312ba7&is=662fda27&hm=4625d5f12158bffc07c4faaf6ce75af6f1396122f148b33b91f3e20b48fecc8b&","raw_image_width":512,"raw_image_height":512,"progress":35,"actions":[],"task_id":"49589d2c-b6b3-4fbf-9f82-93068509c76f","success":true}
{"image_url":"https://midjourney.cdn.acedata.cloud/attachments/1234291876639674388/1234558458595115149/eae94f0f-0ba5-4b3c-9bad-59fb33ac2cbc_grid_0.webp?ex=66312ba9&is=662fda29&hm=9af53fa645127131a88dfbb3930add7abda710c12a3d6c30c457d6a067b36bab&width=256&height=256","image_width":256,"image_height":256,"image_id":"1234558458595115149","raw_image_url":"https://midjourney.cdn.acedata.cloud/attachments/1234291876639674388/1234558458595115149/eae94f0f-0ba5-4b3c-9bad-59fb33ac2cbc_grid_0.webp?ex=66312ba9&is=662fda29&hm=9af53fa645127131a88dfbb3930add7abda710c12a3d6c30c457d6a067b36bab&","raw_image_width":512,"raw_image_height":512,"progress":75,"actions":[],"task_id":"49589d2c-b6b3-4fbf-9f82-93068509c76f","success":true}
{"image_url":"https://midjourney.cdn.acedata.cloud/attachments/1234291876639674388/1234558483408490566/kcisok_A_landscape_painting_of_a_beautiful_sunset_id5963392_eae94f0f-0ba5-4b3c-9bad-59fb33ac2cbc.png?ex=66312baf&is=662fda2f&hm=185ea8f130806bf8bd96911bd251808455fd65596edcdb459f9b3cfd7860387c&width=1024&height=1024","image_width":1024,"image_height":1024,"image_id":"1234558483408490566","raw_image_url":"https://midjourney.cdn.acedata.cloud/attachments/1234291876639674388/1234558483408490566/kcisok_A_landscape_painting_of_a_beautiful_sunset_id5963392_eae94f0f-0ba5-4b3c-9bad-59fb33ac2cbc.png?ex=66312baf&is=662fda2f&hm=185ea8f130806bf8bd96911bd251808455fd65596edcdb459f9b3cfd7860387c&","raw_image_width":2048,"raw_image_height":2048,"progress":100,"actions":["upscale1","upscale2","upscale3","upscale4","reroll","variation1","variation2","variation3","variation4"],"task_id":"49589d2c-b6b3-4fbf-9f82-93068509c76f","success":true}
|
可以看到,启用流式输出之后,返回结果就是逐行的 JSON 了。
在 Node.js 环境中,实现代码可写为如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
const axios = require("axios");
const url = "https://api.acedata.cloud/midjourney/imagine";
const headers = {
"content-type": "application/json",
accept: "application/x-ndjson",
authorization: "Bearer {token}",
};
const body = {
prompt: "a beautiful cat --v 6",
action: "generate",
};
axios
.post(url, body, { headers: headers, responseType: "stream" })
.then((response) => {
console.log(response.status);
response.data.on("data", (chunk) => {
console.log(chunk.toString());
});
})
.catch((error) => {
console.error(error);
});
|
这些示例运行的结果都是相似的。
请注意,流式输出结果中有一个称为 progress 的字段,表示生成进度,范围从 0 到 100。如果需要,您可以在页面上显示这些信息。
注意:当生成未完全完成时,actions 字段为空,表示无法对中间图像执行进一步处理操作。生成完成后,在生成过程中生成的 image_url 将被销毁。
此外,您可以通过指定 accept=application/x-ndjson 的请求头和 callback_url 的请求体,将流式结果与异步回调结合起来,然后 callback_url 可以接收到多个流式结果的 POST 请求。
[1]
Midjourney Imagine API: https://platform.acedata.cloud/documents/e52c028d-897a-4d51-b110-60fccbe6118d
[2]
https://webhook.site/: https://webhook.site/
[3]
https://webhook.site/995d0a91-d737-40a7-a3b9-5baf68ed924c: https://webhook.site/995d0a91-d737-40a7-a3b9-5baf68ed924c
· 立即解锁 Midjourney API




