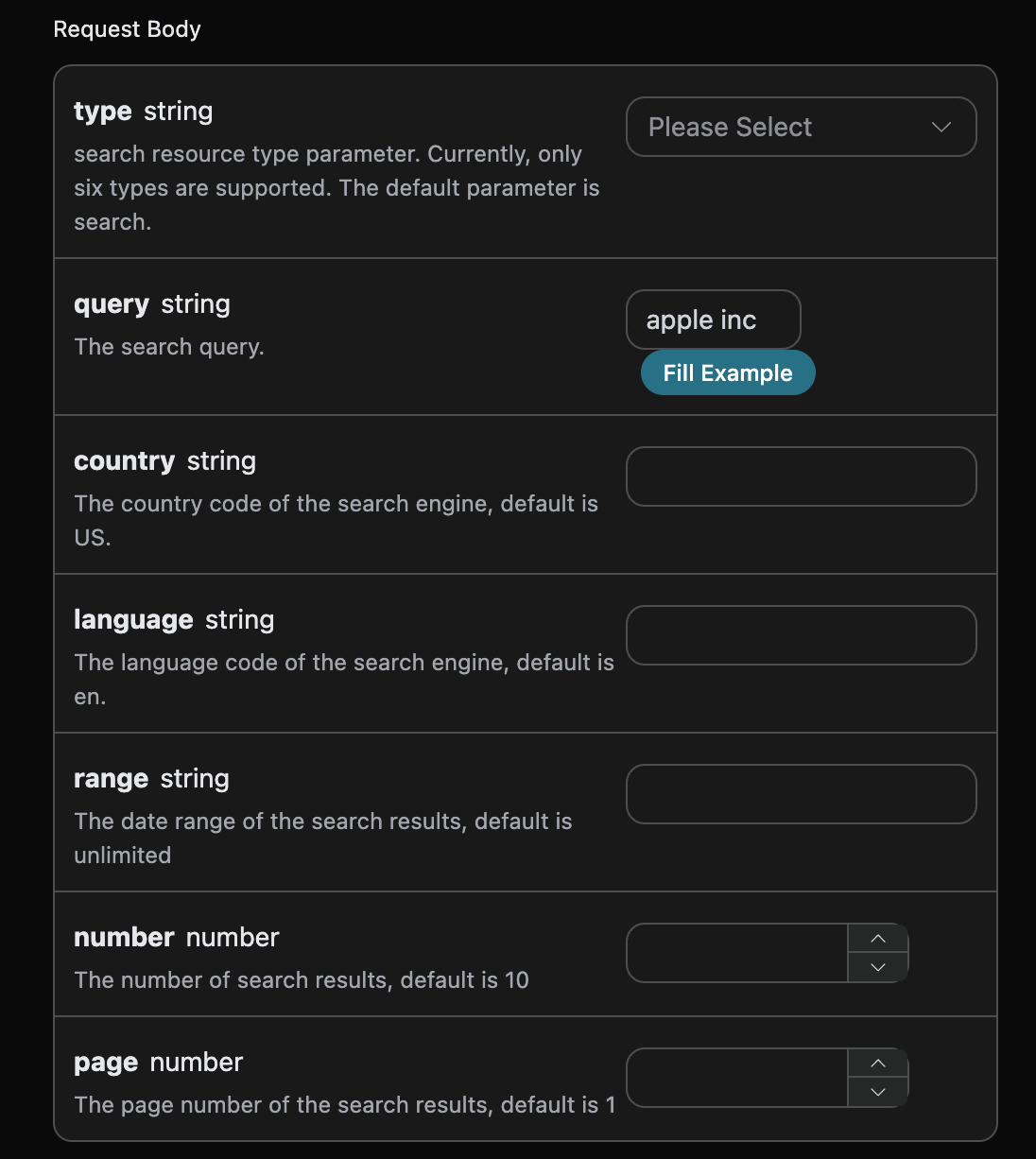
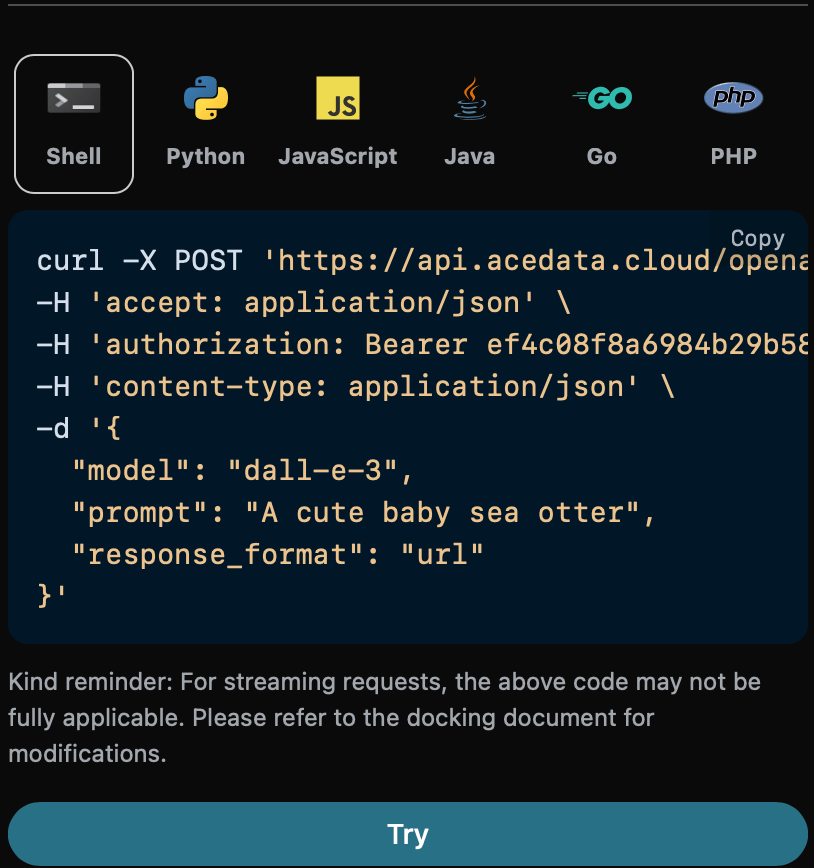
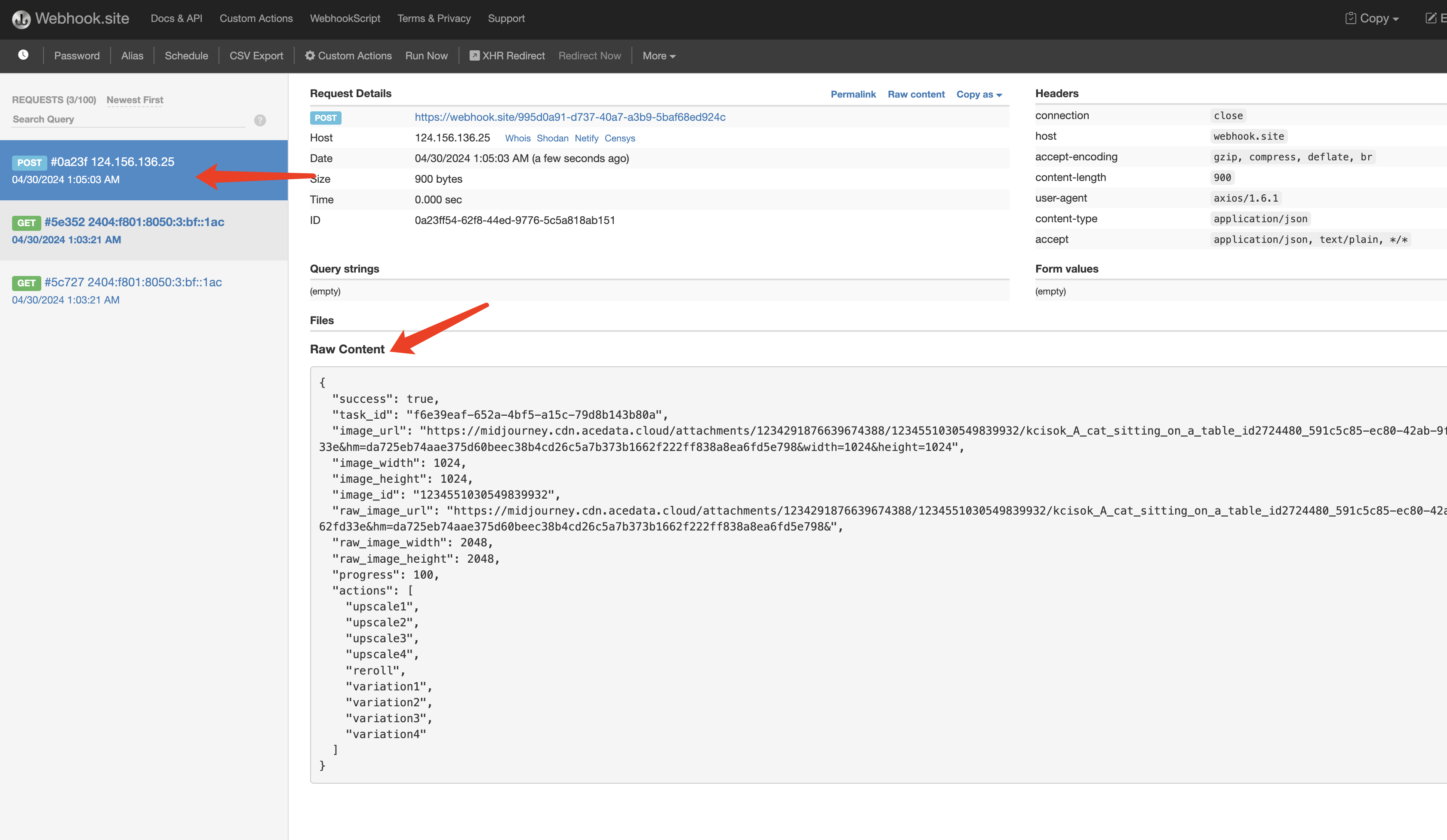
上市了!")



Ace Data Cloud X402 目前使用两类 scheme:exact 和 upto。它们解决的是不同计费问题。
exact
exact 表示本次请求在进入上游 API 前就能确定价格。客户端签名的金额就是最终扣款金额。
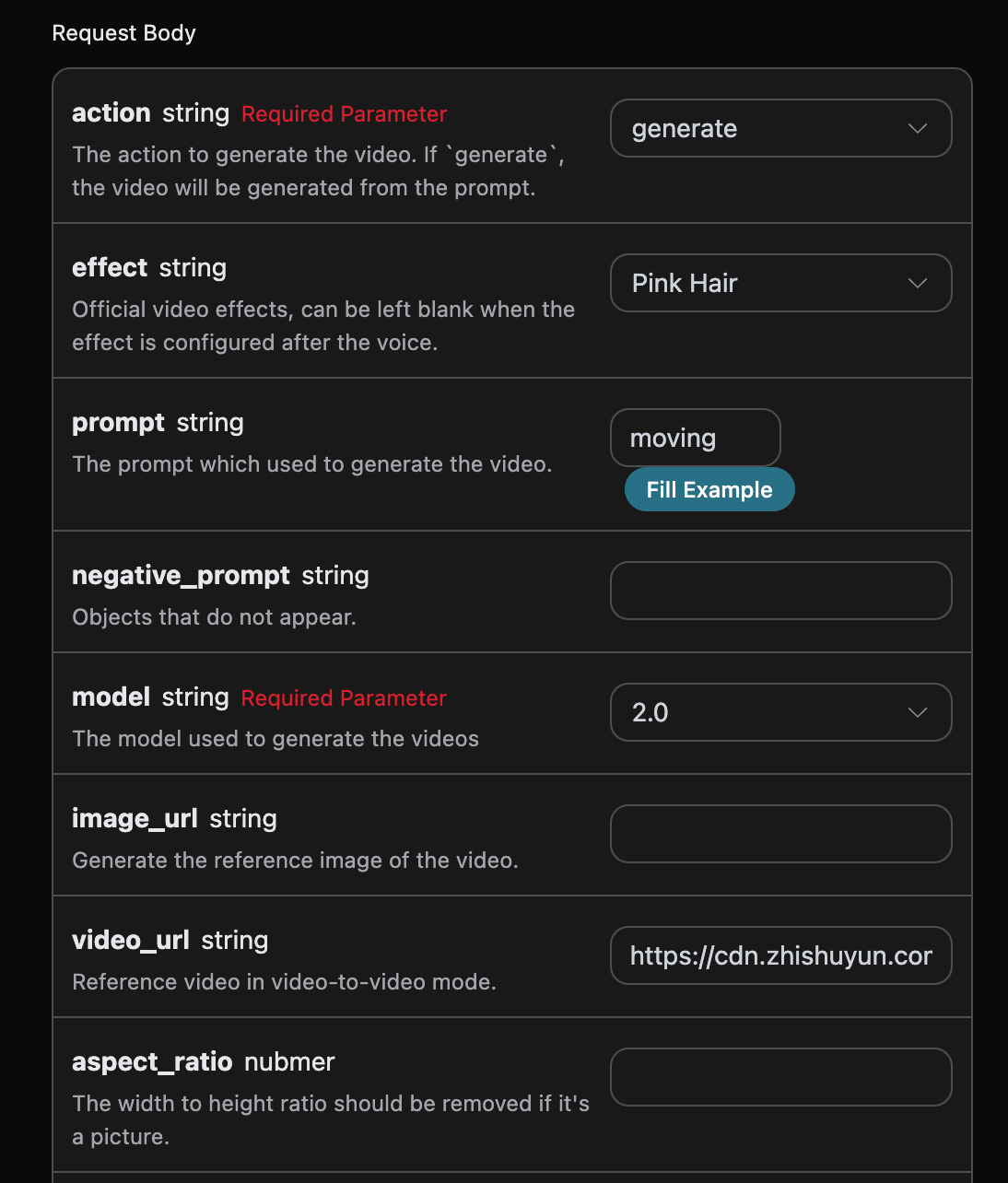
适合:
- 固定价格的图片生成;
- 固定价格的视频任务创建;
- 固定价格的搜索或工具 API;
- 订单支付。
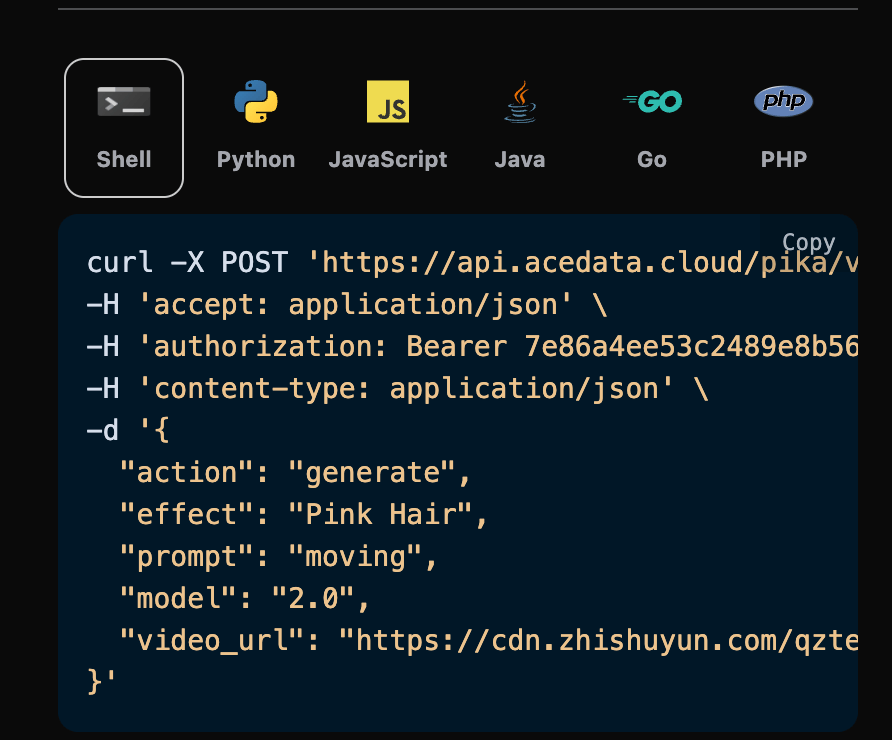
EVM exact 使用 USDC EIP-3009 TransferWithAuthorization:
1 |
{ |
Facilitator 在 /verify 阶段验证签名和金额,在 /settle 阶段把这笔授权提交到链上。
upto
upto 表示客户端授权一个最大上限,Ace Data Cloud 在请求完成后按实际用量结算,实际扣款不能超过上限。
适合:
- 聊天补全:最终价格取决于 prompt tokens 和 completion tokens;
- 流式响应:真实输出长度结束后才知道;
- 未来的后置计量 API。
upto 使用 Permit2 PermitWitnessTransferFrom。客户端签名的不是固定转账,而是一个带 witness 的上限授权:
1 |
{ |
permitted.amount 是上限,不一定是最终扣款。Gateway 在 /record 阶段会把实际用量转换成 amount 传给 Facilitator。Facilitator 只允许结算 amount <= permitted.amount。
Base upto 的程序运行结果:
1 |
payer 0x5d4f08D5c2bb60703284bc06671Eb680fA41B105 |
说明:
- 402 中返回的授权上限是
95215atomic USDC,客户端按这个上限签名。 - 模型实际响应后只结算
3atomic USDC,链上交易已在 BaseScan 可查。 - 这个结果能说明
upto的关键差异:签名金额是上限,链上 settlement 可以小于上限。 - 如果实际用量超过上限,Facilitator 应拒绝 settlement,客户端需要重新按更高上限授权。
SKALE upto 的程序运行结果:
1 |
=== Live X402 upto E2E (skale) === |
SKALE 链上结果:
1 |
Permit2 approve |
结果说明:
- SKALE
upto已完成 HTTP 402 -> HTTP 200,并在/record后完成链上 settlement。 - 该验证请求的签名上限是
4760750atomic USDC,实际 settlement 是151atomic USDC。 - 使用 SKALE
upto前,付款钱包需要先对 SKALE USDC 完成 Permit2 approve;未授权时会返回PERMIT2_ALLOWANCE_REQUIRED。 - EVM typed data 会绑定 chain id、Permit2 spender、USDC 合约、收款地址和 facilitator 地址。请始终使用 402 响应中的实时参数构造签名。
为什么需要 Permit2 approve
upto 最终由 x402 proxy 通过 Permit2 从付款钱包拉取 USDC。第一次使用前,付款钱包需要给 Permit2 一次 ERC-20 allowance。
Python CLI:
1 |
pip install 'acedatacloud-x402[cli]' |
程序方式:
1 |
from acedatacloud_x402 import EVMAccountSigner, approve_permit2 |
授权完成后,每次请求仍然需要签一个新的 upto envelope,因为 nonce、deadline、witness 和金额上限都不同。
零金额结算
upto 支持实际金额为 0 的情况。例如上游 API 没有成功产生可计费用量,Gateway 可以传入 amount = "0"。Facilitator 会返回成功,但不会发链上交易。
这可以避免“请求没有成功但仍然扣链上费用”的问题。
选择建议
| 场景 | 建议 |
|---|---|
| 固定价格 API | 使用 exact,逻辑简单。 |
| 订单支付 | 使用 exact。 |
| 聊天补全、按 token 计费 | 优先使用 Base upto。 |
| 还没有做 Permit2 approve | 先用 exact 跑通,再切 upto。 |
SKALE upto |
已完成链上验证;上线前确认 chain id、facilitator 地址和 Permit2 allowance 与 402 响应一致。 |
如果你不确定该选哪个,先使用 SDK 默认行为;SDK 会选择服务器返回的匹配网络 payment requirement。
SKALE upto 检查清单
SKALE upto 已完成 HTTP paid retry 和链上 settlement 验证。接入或排查时,请确认以下参数来自同一次 402 响应,并在客户端签名时保持一致:
| 参数 | 检查点 |
|---|---|
network |
必须为 skale。 |
scheme |
必须为 upto。 |
extra.chainId |
当前 SKALE Base chain id 为 1187947933。 |
asset |
使用 402 响应中的 SKALE USDC 合约地址。 |
extra.facilitatorAddress |
必须参与 witness,并与 Facilitator 支持能力一致。 |
| Permit2 allowance | 付款钱包需要先对 SKALE USDC 授权 Permit2。 |
常见错误及处理方式:
| 错误 | 处理方式 |
|---|---|
invalid_upto_evm_payload_invalid_signature |
检查 chain id、facilitator 地址、Permit2 domain、spender、签名账户和 witness 是否与 402 响应一致。 |
PERMIT2_ALLOWANCE_REQUIRED |
对目标链 USDC 执行 Permit2 approve 后重新发起请求。 |
amount exceeds permitted amount |
实际用量超过签名上限,需要重新按更高上限签名。 |