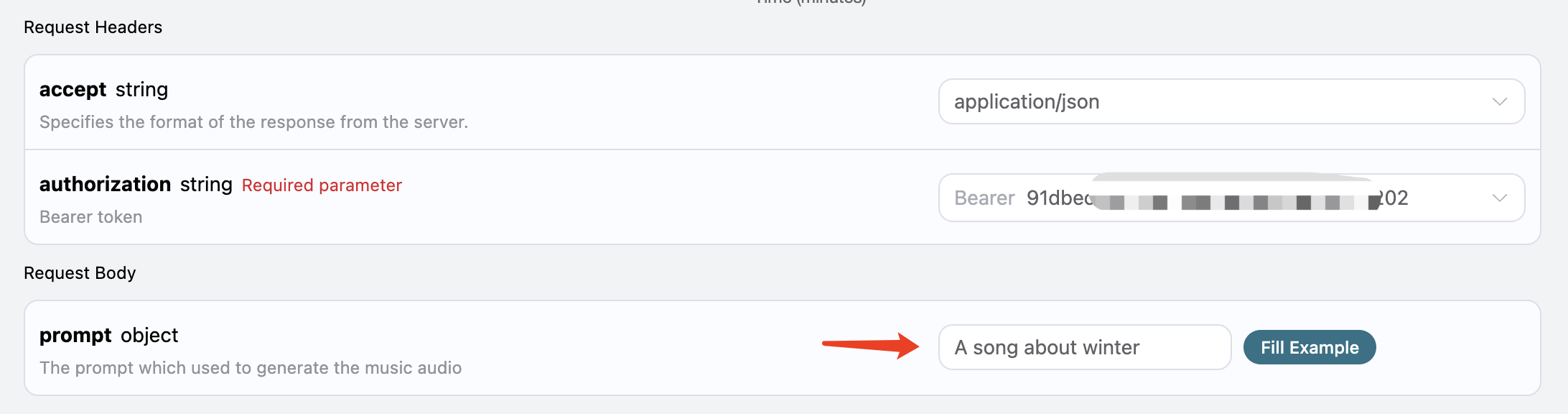
{ "success": true, "task_id": "f45388a9-4169-41d4-aec8-fb8259c48d36", "trace_id": "1df9f664-fd74-476b-8038-b0b5f62ddf87", "data": [ { "id": "02702b40-272d-4838-8644-675105930658", "title": "Vibe", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/e850008a-d9a1-4c8f-acbd-a37f228946bc/image/02702b40-272d-4838-8644-675105930658.jpg", "lyric": "[Intro]\nYeah, yeah\nKeep talking, keep talking\nI love the way you sound\n[Verse 1]\nYour voice is like a drug I can't put down\nEvery word you say just pulls me in\nI'm addicted to the way you laugh out loud\nAnd how you whisper when the room goes dim\nTell me 'bout your day, tell me 'bout your fears\nI could listen to you talk for years\n[Pre-Chorus]\nDon't stop now, don't you dare\nI need your voice filling up the air\n[Chorus]\nKeep talking, keep talking to me\nYour words are all I fucking need\nKeep talking, keep talking, I'm high\nOff every sound you make tonight\nKeep talking\n[Verse 2]\nYou could read the phone book, I don't care\nJust the rhythm of your breathing's enough\nWhen you say my name, it's like a prayer\nAnd your silence hits me twice as rough\nEvery conversation feels like home\nNever want to hear this dial tone\n[Pre-Chorus]\nDon't stop now, don't you dare\nI need your voice filling up the air\n[Chorus]\nKeep talking, keep talking to me\nYour words are all I fucking need\nKeep talking, keep talking, I'm high\nOff every sound you make tonight\nKeep talking\n[Bridge]\nWhen the world gets loud and crazy\nYour voice cuts through the noise\nYou're my favorite conversation\nYou're my drug of choice\nKeep talking, keep talking\nKeep talking, keep talking\nKeep talking, keep talking\nKeep talking, keep talking\n[Chorus]\nKeep talking, keep talking to me\nYour words are all I fucking need\nKeep talking, keep talking, I'm high\nOff every sound you make tonight\nKeep talking\n[Outro]\nYeah, yeah\nKeep talking, keep talking\nNever stop that sound", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/e850008a-d9a1-4c8f-acbd-a37f228946bc/audio/02702b40-272d-4838-8644-675105930658.m4a", "video_url": null, "created_at": "2025-06-18T15:47:54.705246Z", "model": "FUZZ-1.0", "lyrics_timestamped": { "words": [ { "text": "[Intro]", "start": 0.64, "end": 0.64, "line_index": 0, "index_range": null, "wav2vec2_format": null }, ... { "text": "sound", "start": 179.84, "end": 180.48, "line_index": 63, "index_range": null, "wav2vec2_format": null } ] }, "state": "succeeded", "style": "Pop, upbeat tempo, modern production", "duration": 181.12 }, { "id": "be3fe757-621e-4017-9056-20aa7f01919e", "title": "Revive", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/e850008a-d9a1-4c8f-acbd-a37f228946bc/image/be3fe757-621e-4017-9056-20aa7f01919e.jpg", "lyric": "[Verse 1]\nI'm walking through the motions, moving day by day\nColors seem a little faded, nothing much to say\nFriends keep calling, asking if I'm doing fine\nBut I just smile and tell them everything's divine\n[Pre-Chorus]\nSomething's missing, can't quite name it\nFeels like I'm just going through the stages\n[Chorus]\nI'm barely breathing, barely feeling\nLike I'm floating through a life that isn't mine\nBarely breathing, barely healing\nSearching for a reason, searching for a sign\nTo feel alive again\nTo feel alive again\n[Verse 2]\nMorning coffee tastes like water, sunrise looks like rain\nEveryone around me laughs but I can't feel the same\nUsed to dance in silly moments, used to sing out loud\nNow I'm standing in the silence of a faceless crowd\n[Pre-Chorus]\nSomething's shifting, can't ignore it\nMaybe it's time to break these patterns\n[Chorus]\nI'm barely breathing, barely feeling\nLike I'm floating through a life that isn't mine\nBarely breathing, barely healing\nSearching for a reason, searching for a sign\nTo feel alive again\nTo feel alive again\n[Bridge]\nBut there's a beating in my chest\nA whisper saying \"don't give up yet\"\nMaybe tomorrow I'll remember\nHow to laugh and how to let\nMy heart wake up from this long sleep\nFind the fire I used to keep\n[Chorus]\nI'm barely breathing, barely feeling\nLike I'm floating through a life that isn't mine\nBarely breathing, barely healing\nSearching for a reason, searching for a sign\nTo feel alive again\nTo feel alive again\n[Outro]\nI'm gonna feel alive again\nI'm gonna feel alive again", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/e850008a-d9a1-4c8f-acbd-a37f228946bc/audio/be3fe757-621e-4017-9056-20aa7f01919e.m4a", "video_url": null, "created_at": "2025-06-18T15:48:01.139081Z", "model": "FUZZ-1.0", "lyrics_timestamped": { "words": [ { "text": "[Verse", "start": 0.64, "end": 0.64, "line_index": 0, "index_range": null, "wav2vec2_format": null }, ... { "text": "again", "start": 202.88, "end": 211.84, "line_index": 54, "index_range": null, "wav2vec2_format": null } ] }, "state": "succeeded", "style": "Pop, upbeat tempo, clean production, emotional vocals", "duration": 211.84 } ] }
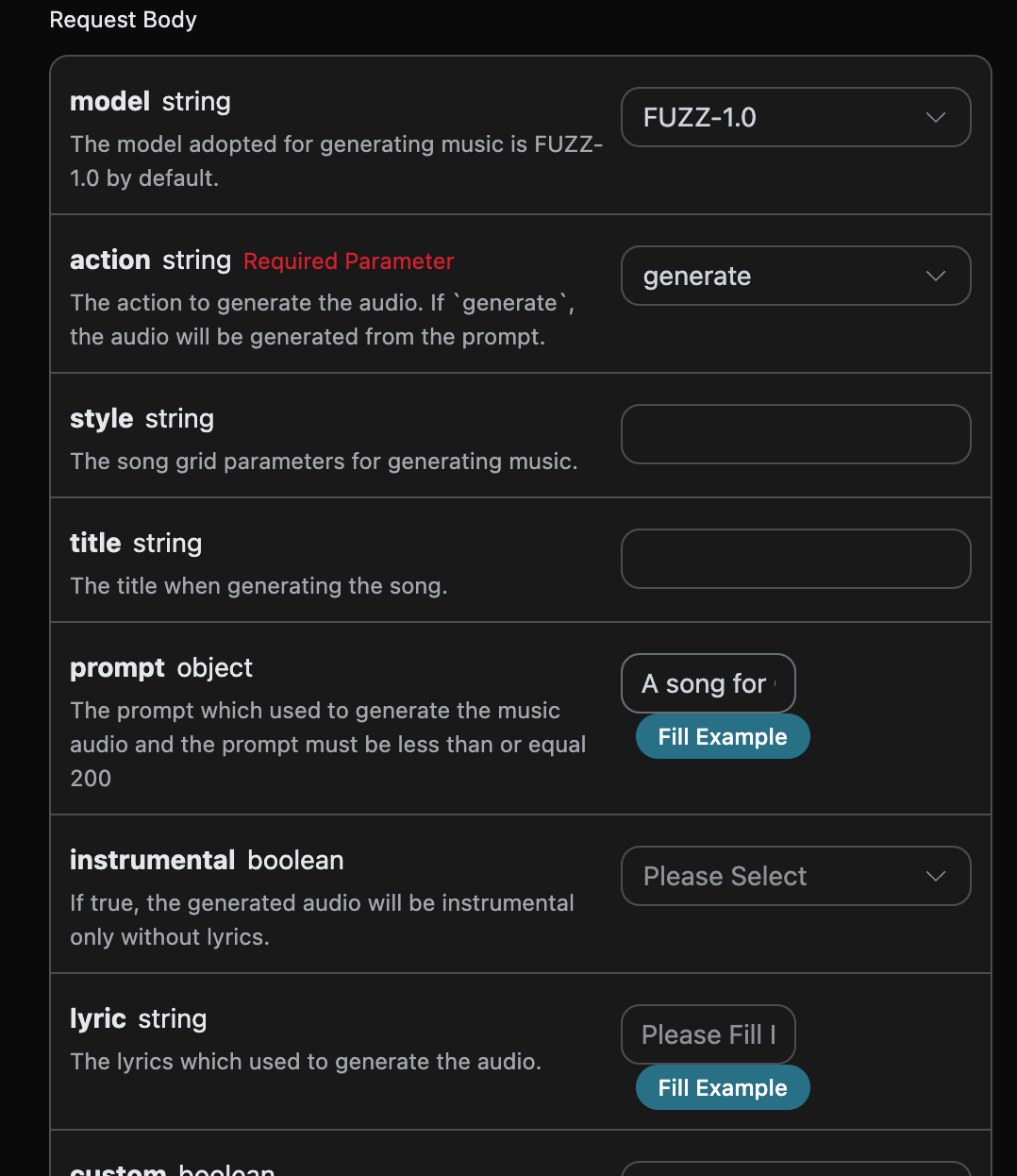
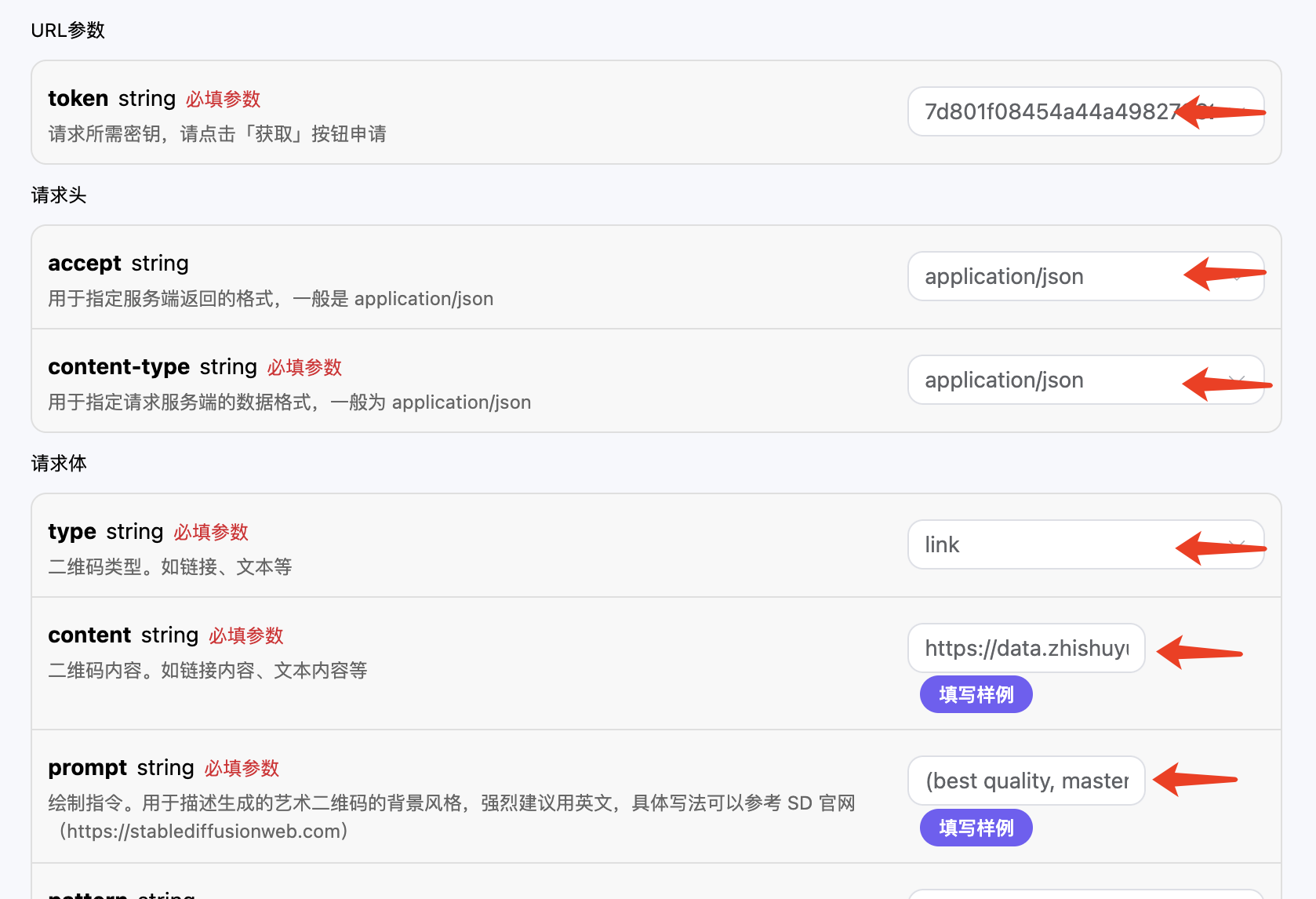
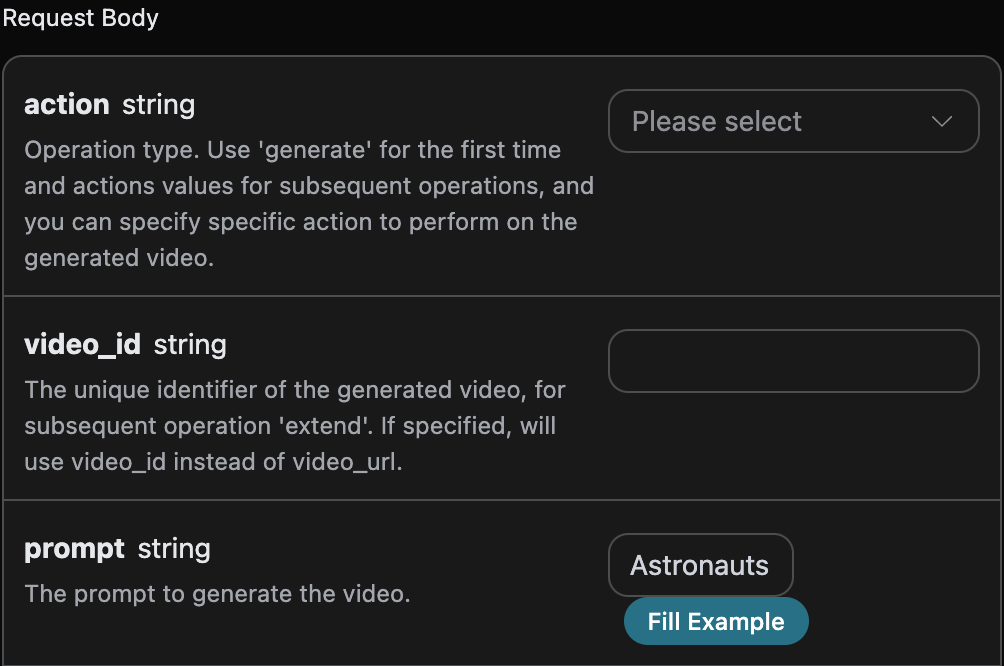
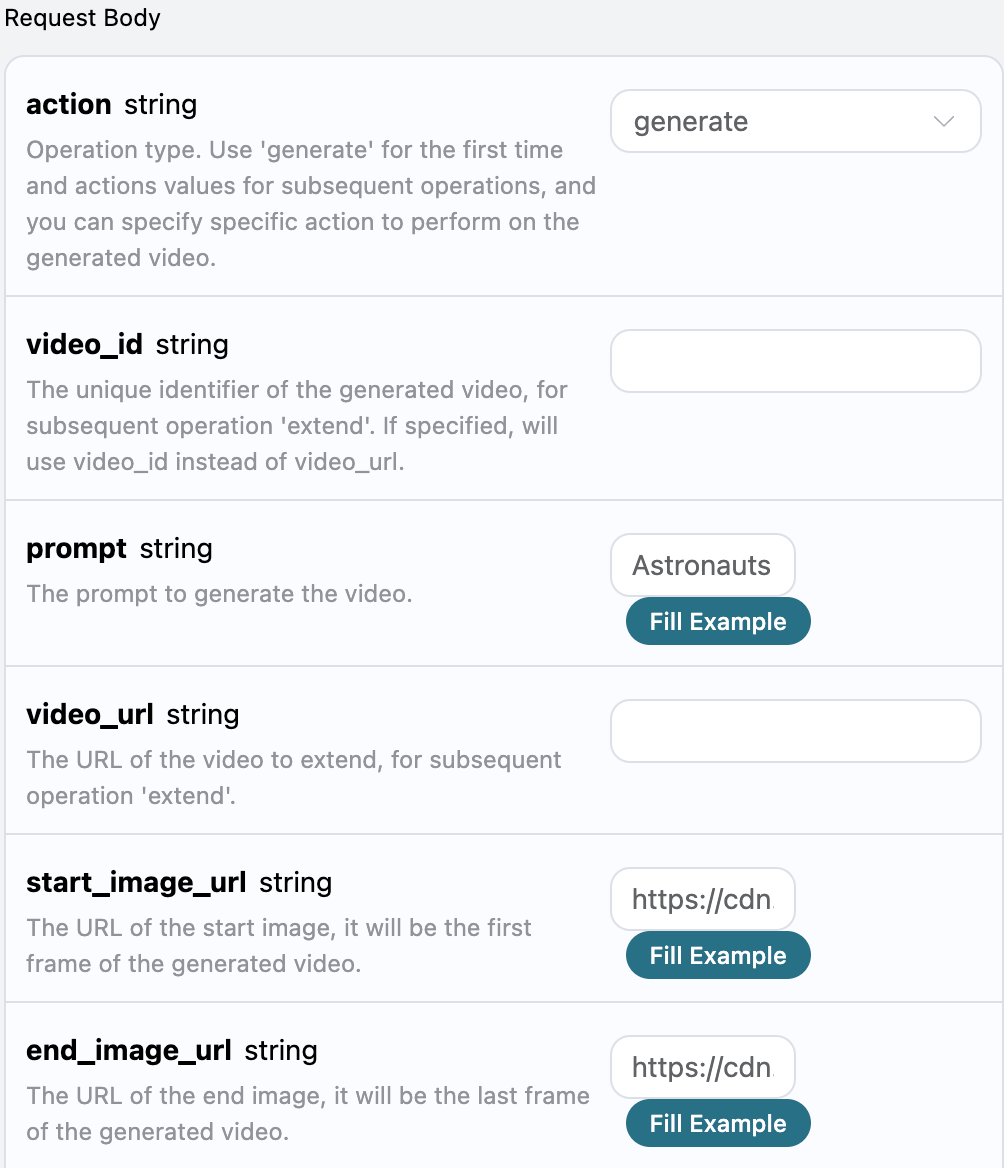
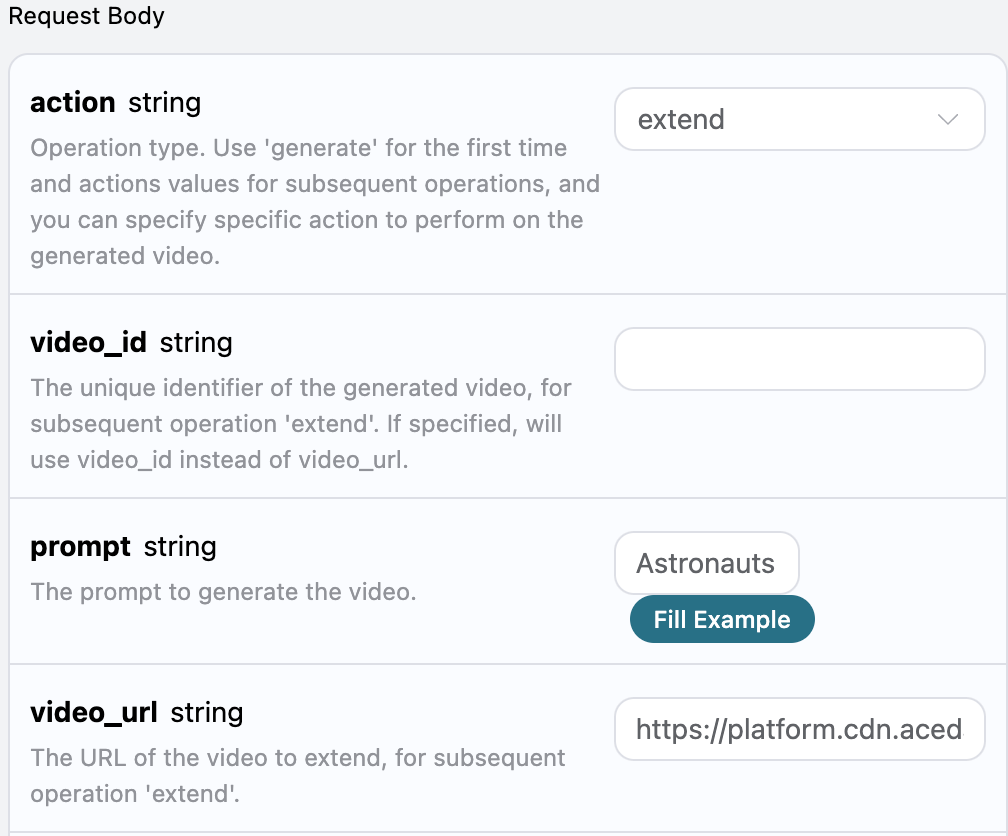
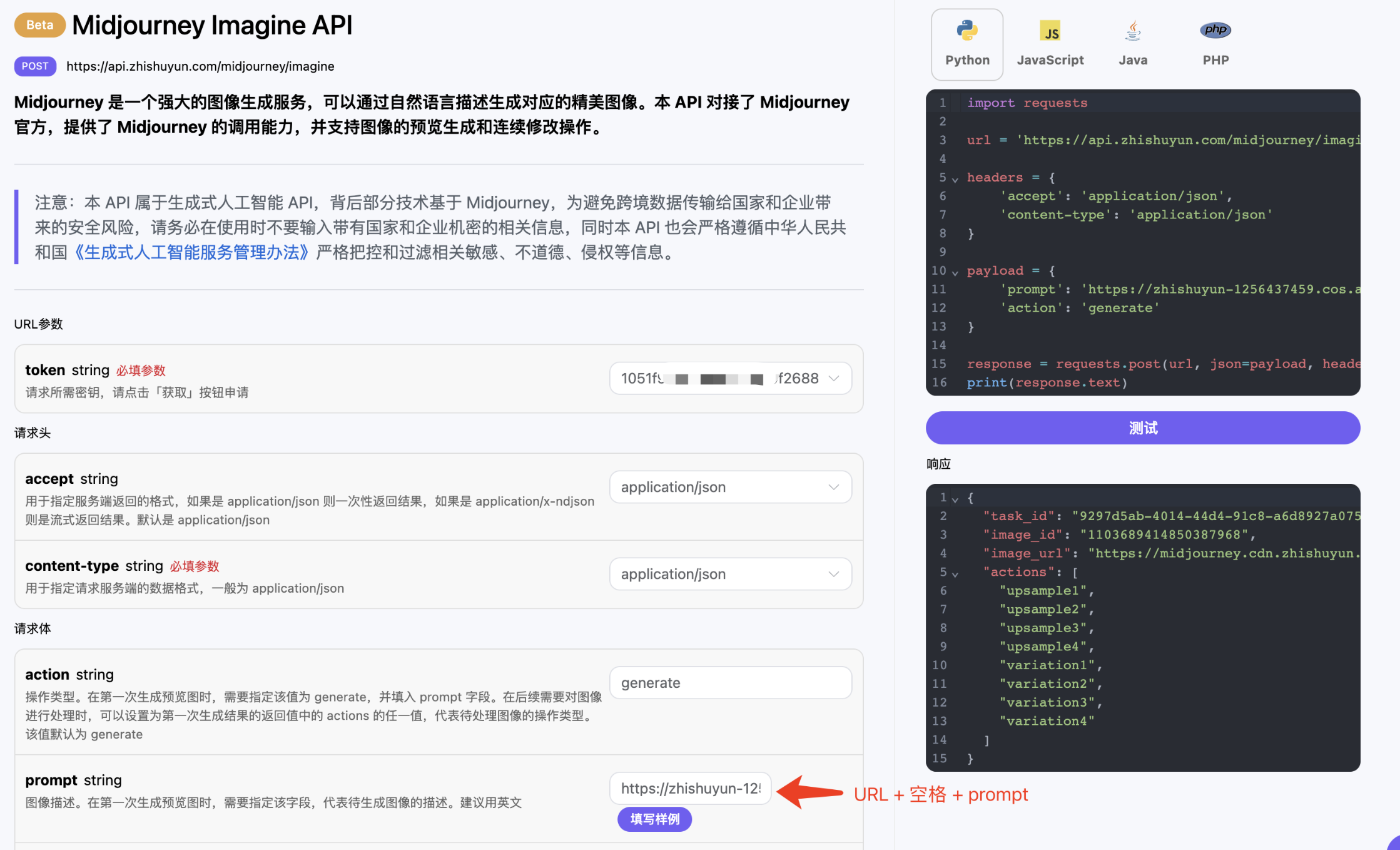
返回结果一共有多个字段,介绍如下:
success,此时音乐生成任务的状态情况。
data,此次音乐任务的结果 - id,此时音乐生成任务的 ID。
prompt,此时音乐生成任务的提示词。
audio_url,此时音乐生成任务的音频链接。
image_url,此时音乐生成任务的封面链接。
state,此时音乐生成任务的状态。
duration,此时音乐的时长信息。
style,此时音乐的风格信息。
model,此时音乐生成任务采用的模型信息。
lyric,此时音乐生成任务的歌词信息。
可以看到我们得到了想生成的音乐信息,我们只需要根据结果中 data 的音乐链接地址获取生成的 Riffusion 音乐即可。
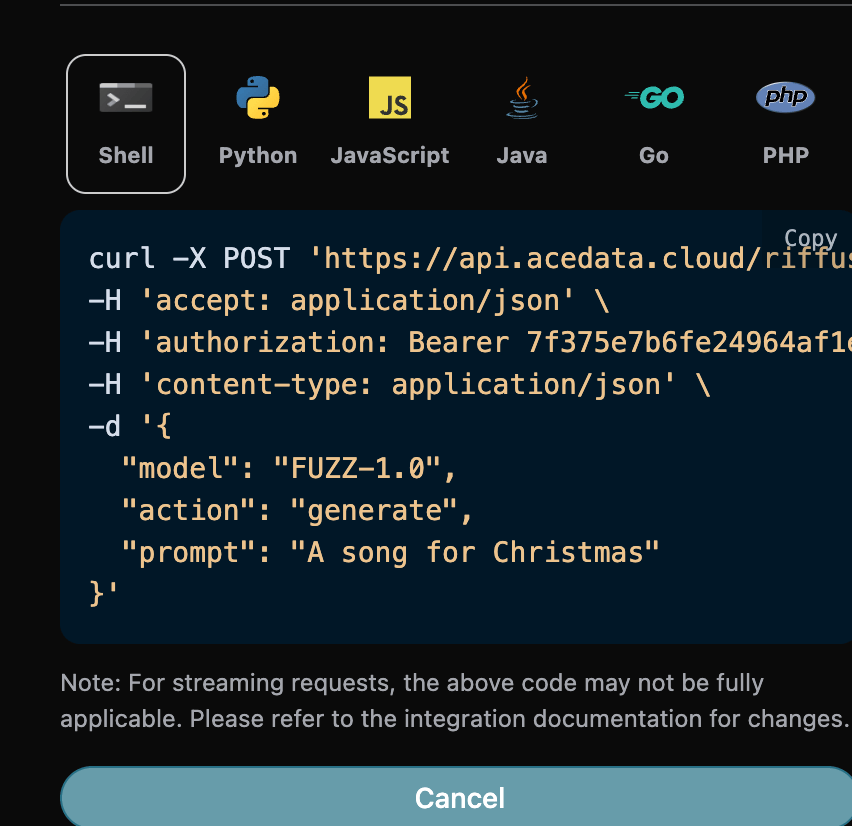
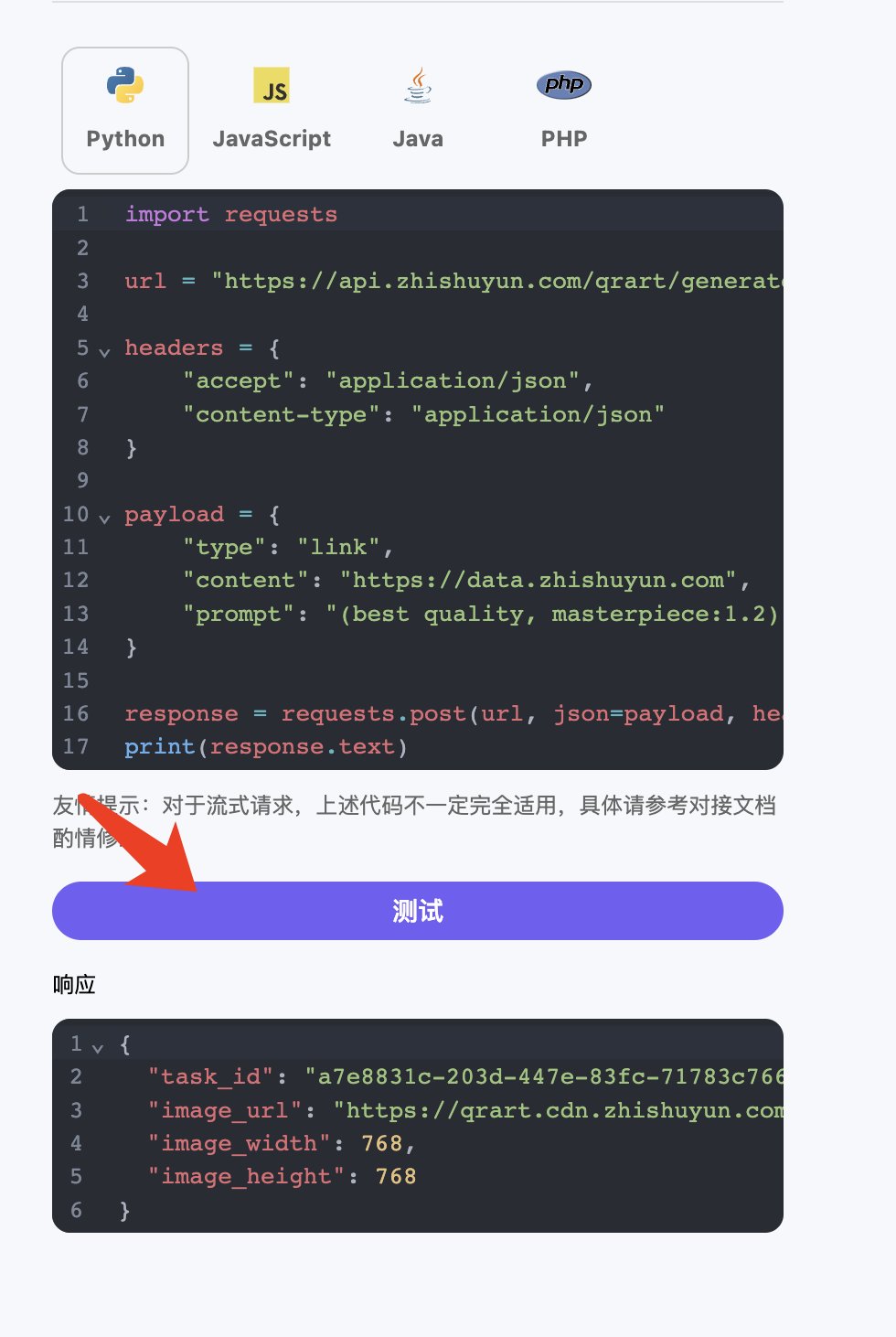
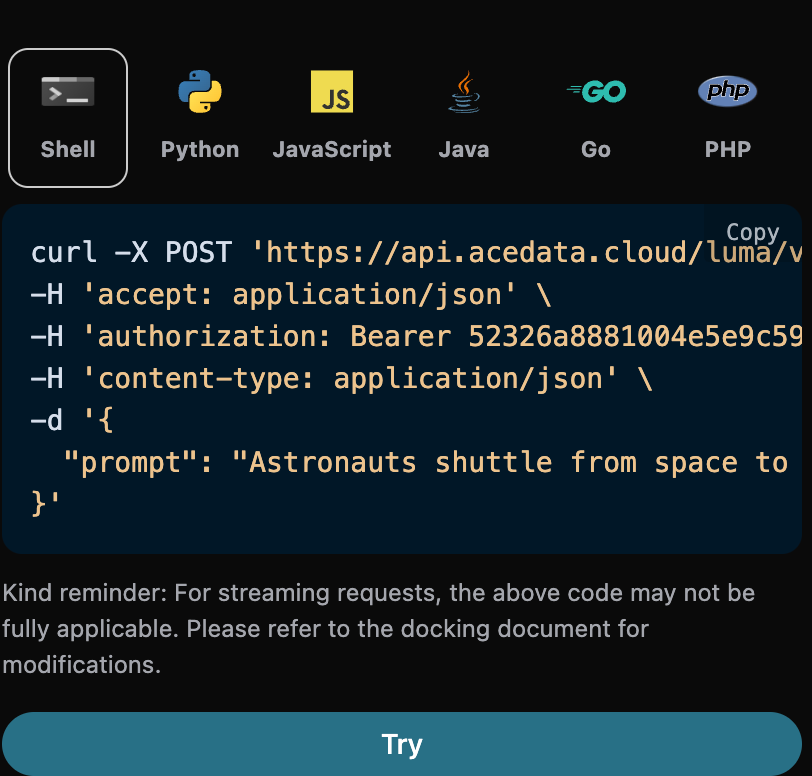
另外如果想生成对应的对接代码,可以直接复制生成,例如 CURL 的代码如下:
1 2 3 4 5 6 7 8 9
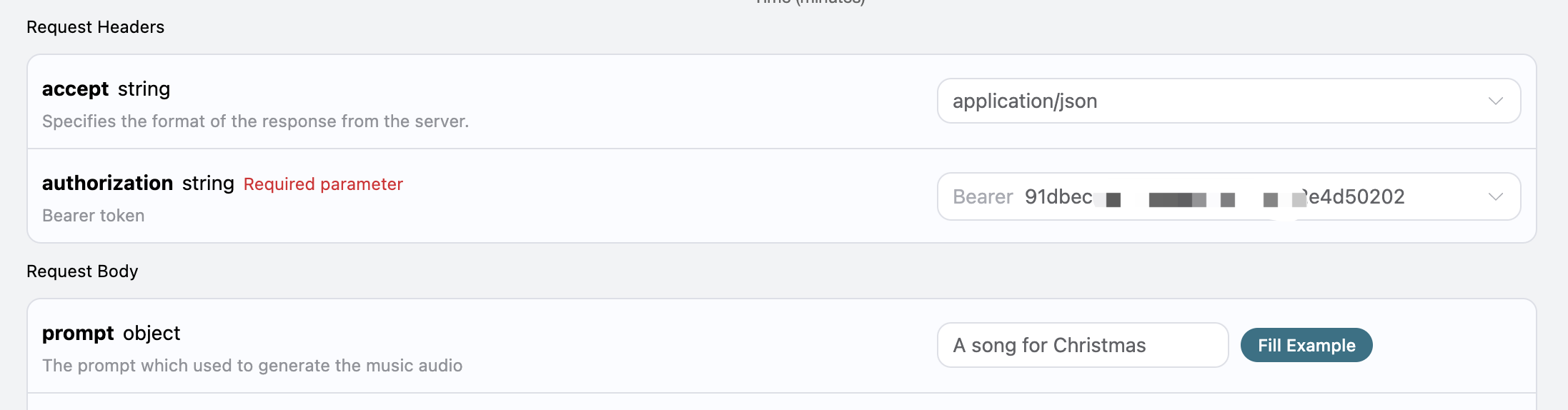
curl -X POST 'https://api.acedata.cloud/riffusion/audios' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "model": "FUZZ-1.0", "action": "generate", "prompt": "A song for Christmas" }'
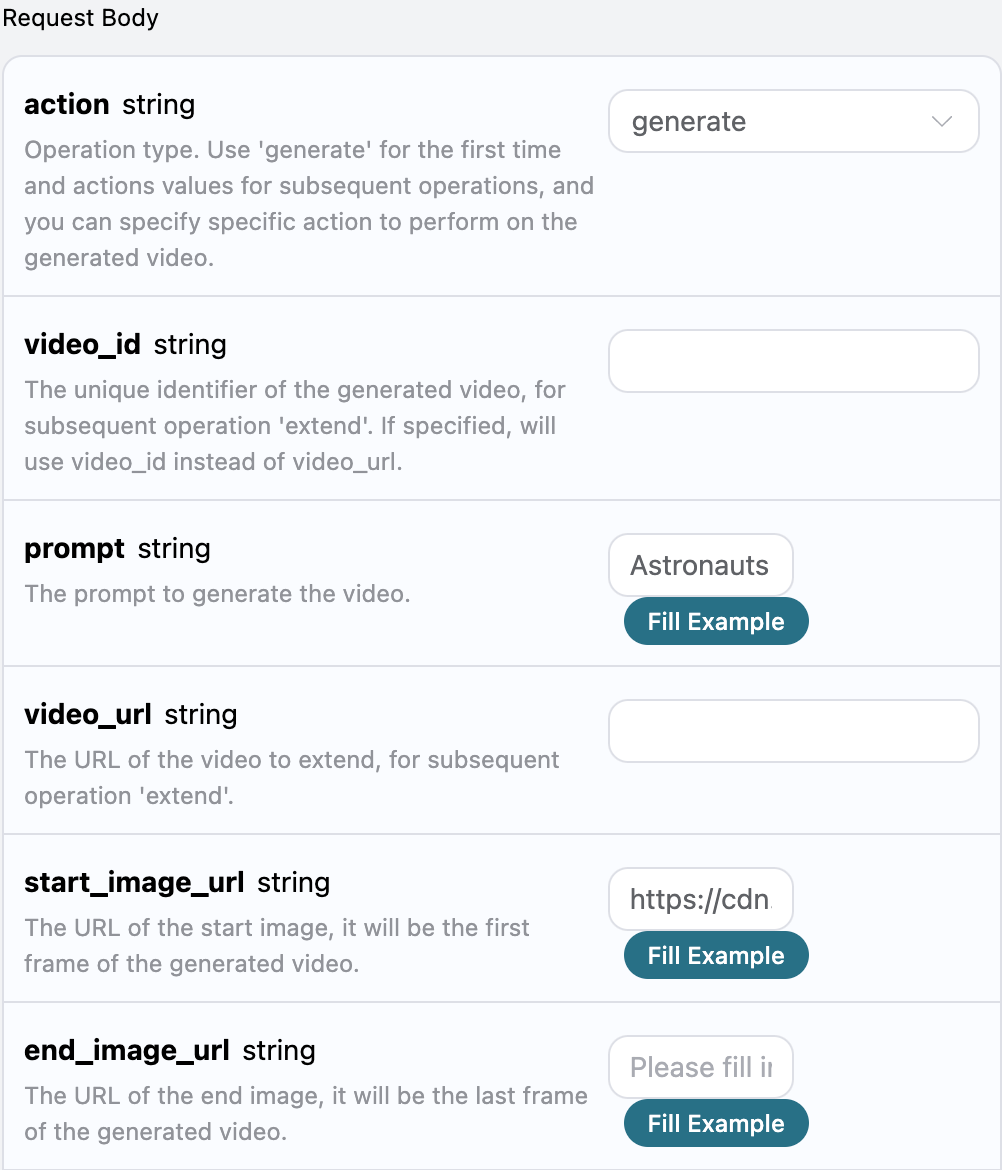
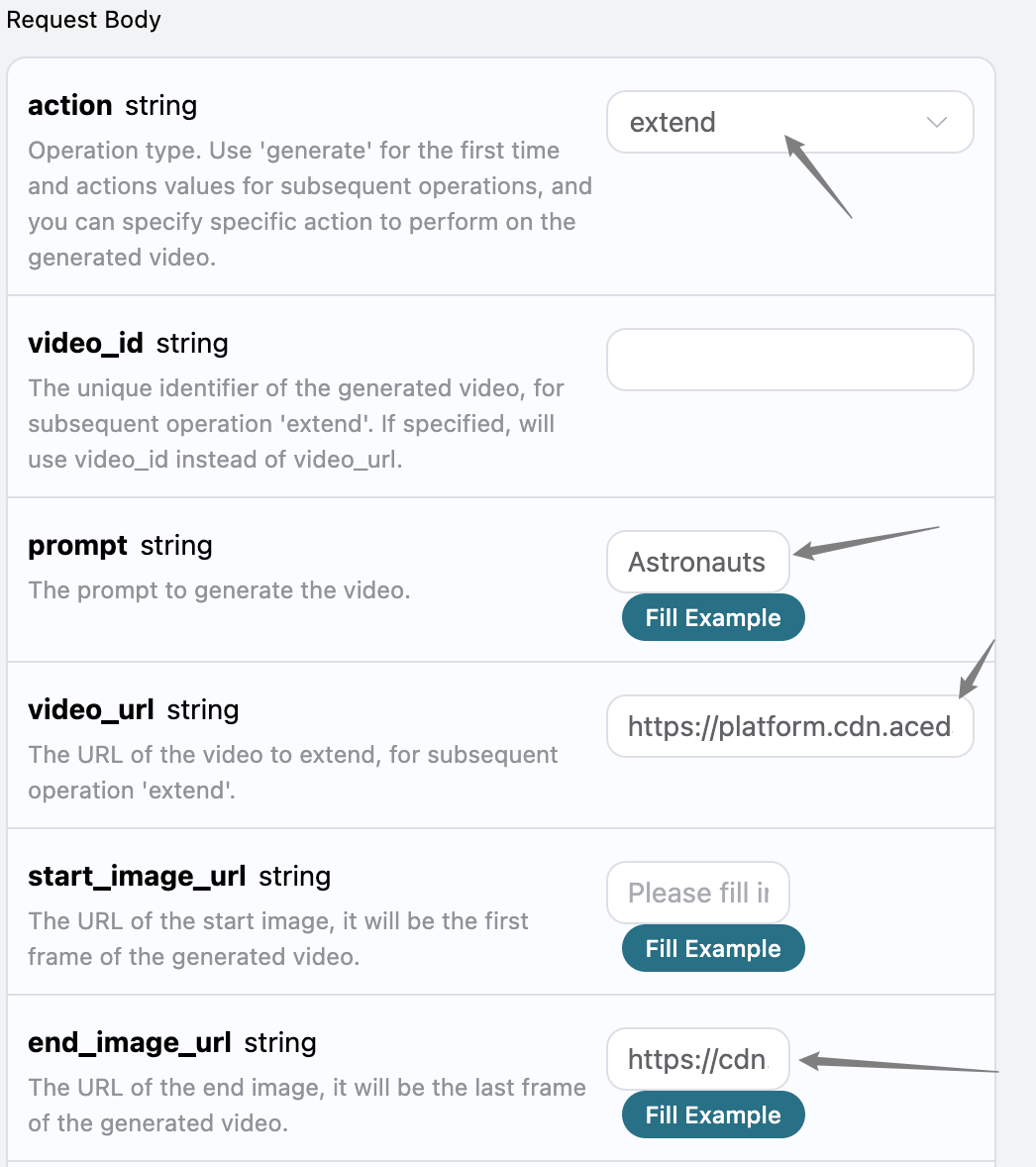
自定义生成
如果想自定义生成歌词,可以输入歌词:
这时候 lyric 字段可以传入类似如下内容:
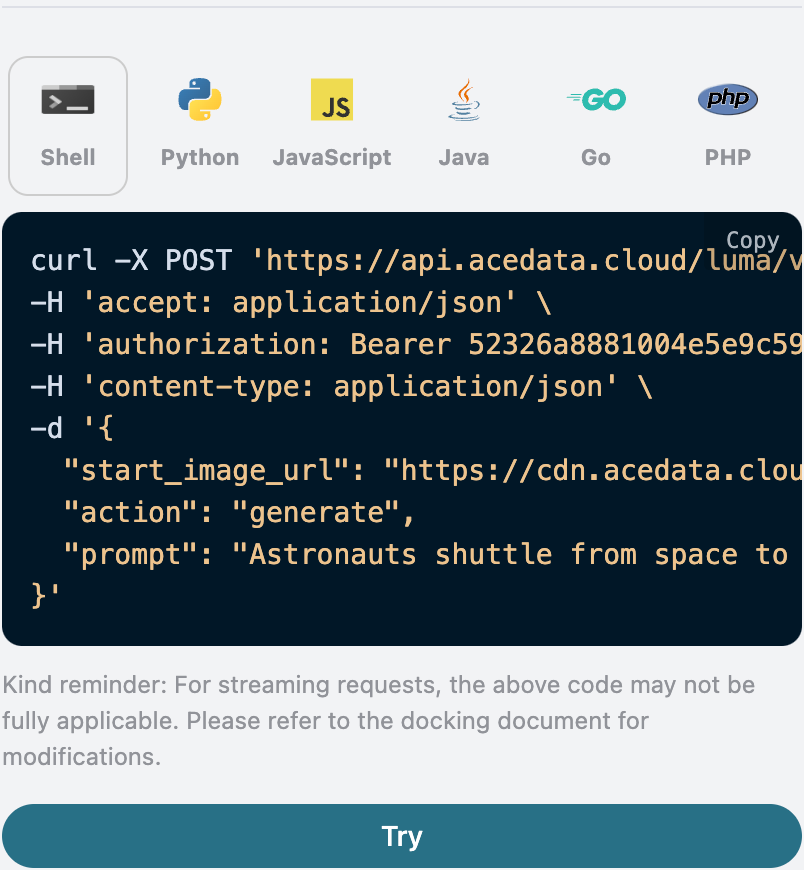
1
[Verse]Woke up withthe sun inmy eyesNo clouds above just blue inthe skiesShoes onmy feet I’m ready to runEvery step feels like a loaded gun[Chorus]Happy days are rolling inLet the joy beneathmy skinNo more shadows no more liesJust the truth that lifts me high[Verse 2]Dancing throughthe city streetsA rhythm pounding inmy heartbeatStrangers smile it’s catching onThis world’s a stage we’re all a song[Chorus]Happy days are rolling inLet the joy beneathmy skinNo more shadows no more liesJust the truth that lifts me high[Bridge]Throw your worries out the doorLet them sink tothe ocean floorWe’re alive andit’s enoughLife is messy butit’s love[Chorus]Happy days are rolling inLet the joy beneathmy skinNo more shadows no more liesJust the truth that lifts me high
curl -X POST 'https://api.acedata.cloud/riffusion/audios' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "model": "FUZZ-1.0", "action": "generate", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "custom": true }'
{ "success": true, "task_id": "978c2912-6a90-4048-b4c1-43f9cf18c28d", "trace_id": "08dfbb99-43ce-4f65-8fd1-74b98f2b121a", "data": [ { "id": "eac9ab69-e210-490b-9f8d-095a6f074f40", "title": "VibeRise", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/3f3e1354-52ad-4f5b-902c-5f83abd17def/image/eac9ab69-e210-490b-9f8d-095a6f074f40.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/3f3e1354-52ad-4f5b-902c-5f83abd17def/audio/eac9ab69-e210-490b-9f8d-095a6f074f40.m4a", "video_url": null, "created_at": "2025-06-23T01:57:33.438644Z", "model": "FUZZ-1.0", "lyrics_timestamped": { "words": [ { "end": 0.64, "index_range": null, "line_index": 0, "start": 0.64, "text": "[Verse]", "wav2vec2_format": null }, { "end": 0.64, "index_range": null, "line_index": 1, "start": 0.64, "text": "Woke", "wav2vec2_format": null }, ... ] }, "state": "succeeded", "style": "funk vibes, raspy, raw vocal texture", "duration": 158.08 }, { "id": "64fffe1f-b1aa-46dc-8012-b80ba319cf35", "title": "Pure Dawn", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/3f3e1354-52ad-4f5b-902c-5f83abd17def/image/64fffe1f-b1aa-46dc-8012-b80ba319cf35.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/3f3e1354-52ad-4f5b-902c-5f83abd17def/audio/64fffe1f-b1aa-46dc-8012-b80ba319cf35.m4a", "video_url": null, "created_at": "2025-06-23T01:57:33.963497Z", "model": "FUZZ-1.0", "lyrics_timestamped": { "words": [ { "end": 0.64, "index_range": null, "line_index": 0, "start": 0.64, "text": "[Verse]", "wav2vec2_format": null }, { "end": 0.64, "index_range": null, "line_index": 1, "start": 0.64, "text": "Woke", "wav2vec2_format": null }, ... ] }, "state": "succeeded", "style": "contemporary country", "duration": 175.36 } ] }
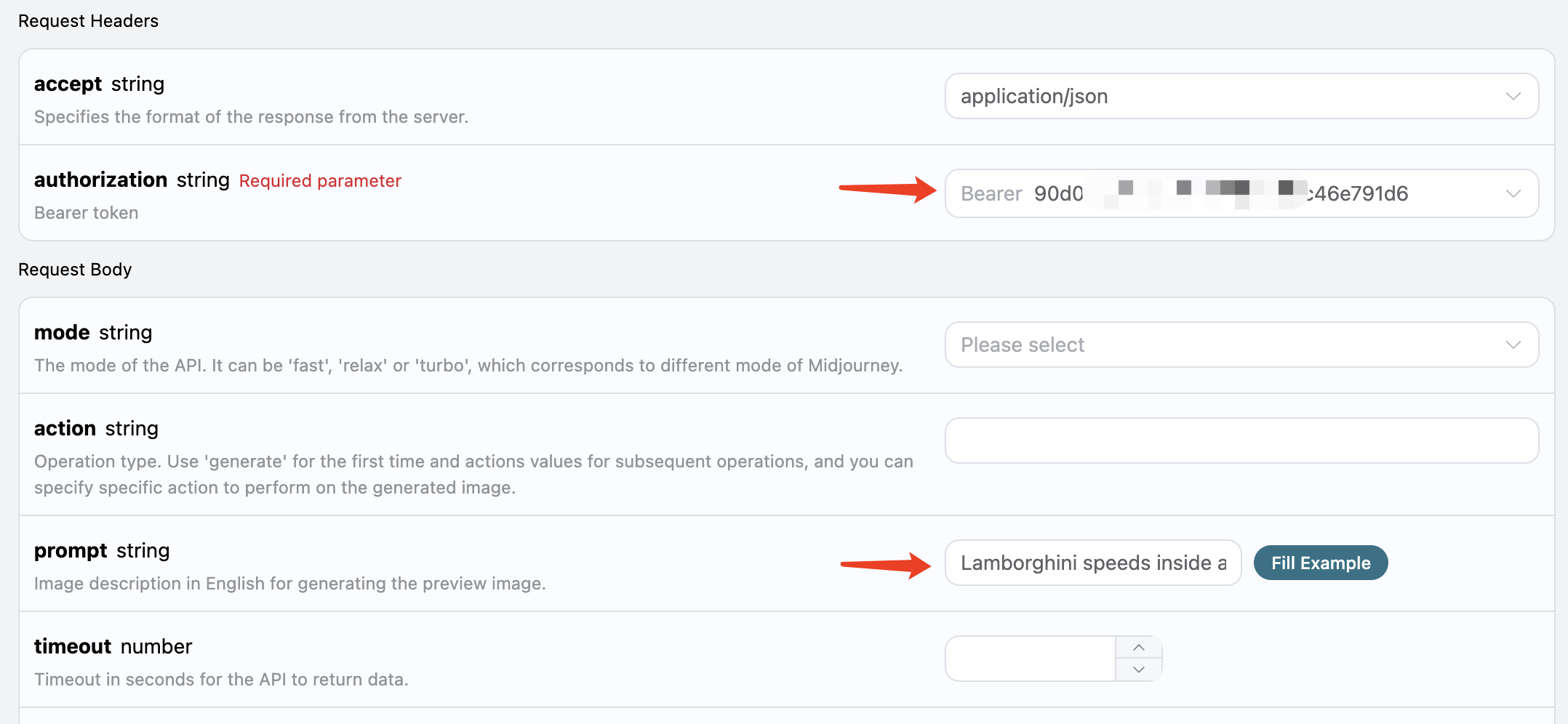
curl -X POST 'https://api.acedata.cloud/riffusion/audios' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "action": "cover", "model": "FUZZ-1.0 Pro", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_id": "b7376272-3902-49b4-a83b-62f7e6ab505c" }'
{ "success": true, "task_id": "fe02997d-f58e-4886-9aa3-4074c9a430eb", "trace_id": "997bde4c-6063-4fc2-9b03-d837f1efc72d", "data": [ { "id": "be254182-d4b7-42b3-9ee2-b86db086cff1", "title": "Sunny Rise", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/c2f707a9-017d-4354-8bfa-436266dadbf6/image/be254182-d4b7-42b3-9ee2-b86db086cff1.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/c2f707a9-017d-4354-8bfa-436266dadbf6/audio/be254182-d4b7-42b3-9ee2-b86db086cff1.m4a", "video_url": null, "created_at": "2025-06-23T01:59:17.666629Z", "model": null, "lyrics_timestamped": { "words": [ { "end": 0.64, "index_range": null, "line_index": 0, "start": 0.64, "text": "[Verse]", "wav2vec2_format": null }, ... { "end": 237.44, "index_range": null, "line_index": 29, "start": 236.8, "text": "high", "wav2vec2_format": null } ] }, "state": "succeeded", "style": "", "duration": 239.46235827664398 }, { "id": "9b9d2810-eb2b-44d3-85c0-cb259afa13c3", "title": "Uplift", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/c2f707a9-017d-4354-8bfa-436266dadbf6/image/9b9d2810-eb2b-44d3-85c0-cb259afa13c3.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/c2f707a9-017d-4354-8bfa-436266dadbf6/audio/9b9d2810-eb2b-44d3-85c0-cb259afa13c3.m4a", "video_url": null, "created_at": "2025-06-23T01:59:23.065712Z", "model": null, "lyrics_timestamped": { "words": [ { "end": 0.64, "index_range": null, "line_index": 0, "start": 0.64, "text": "[Verse]", "wav2vec2_format": null }, ... }, { "end": 236.16, "index_range": null, "line_index": 29, "start": 225.28, "text": "high", "wav2vec2_format": null } ] }, "state": "succeeded", "style": "", "duration": 239.5299546485261 } ] }
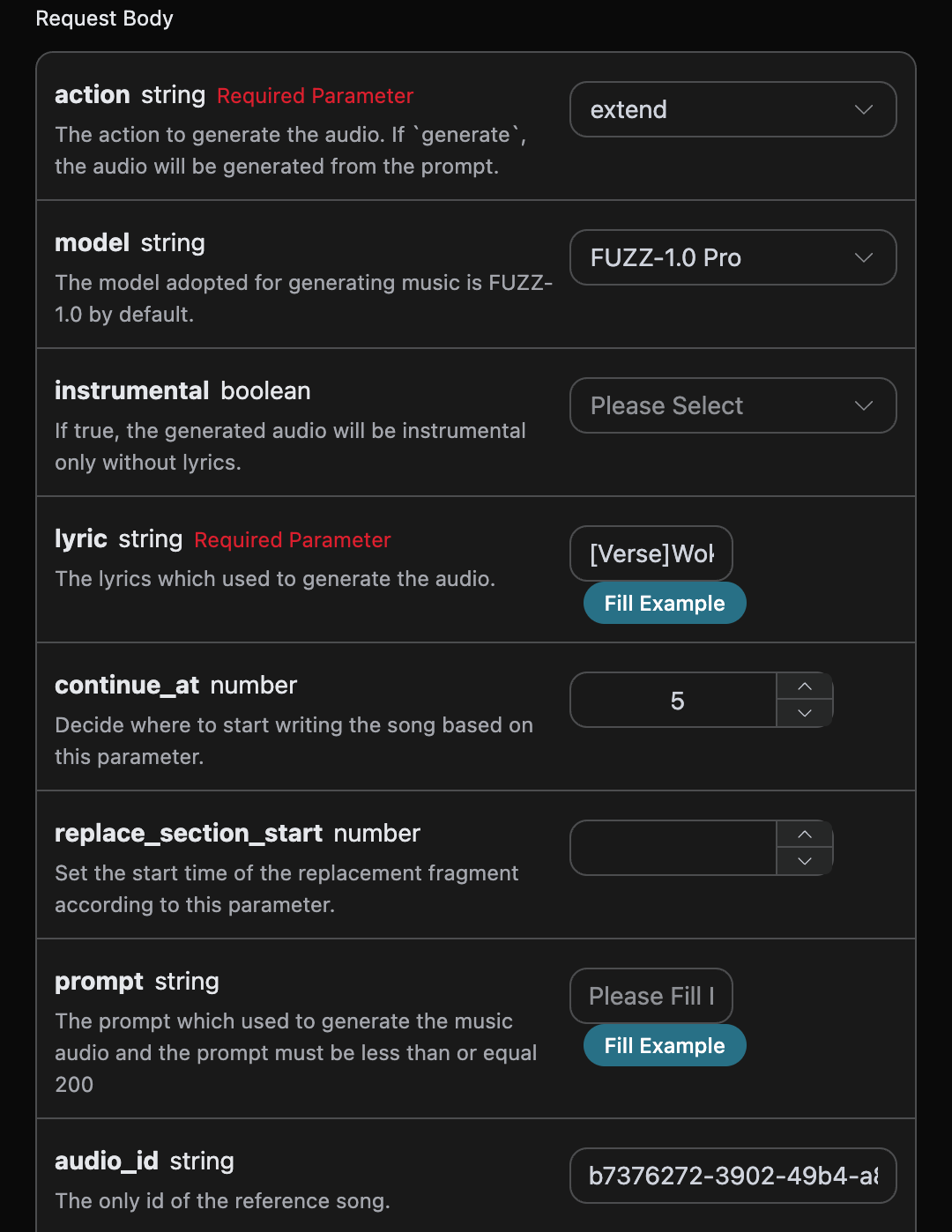
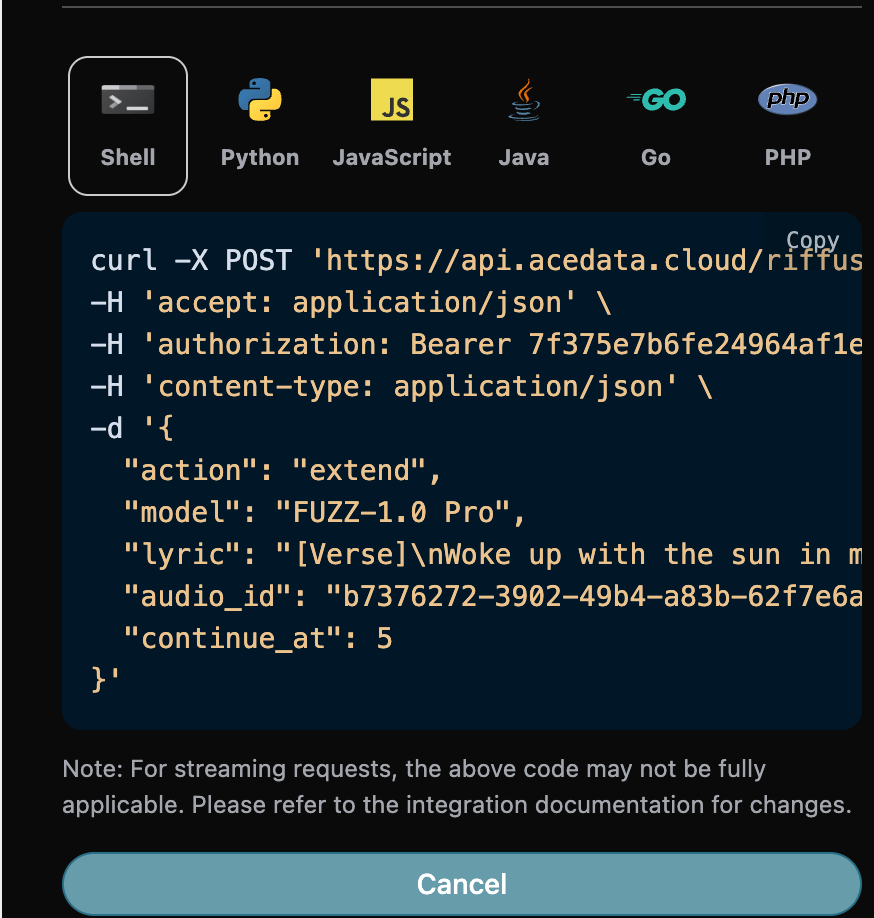
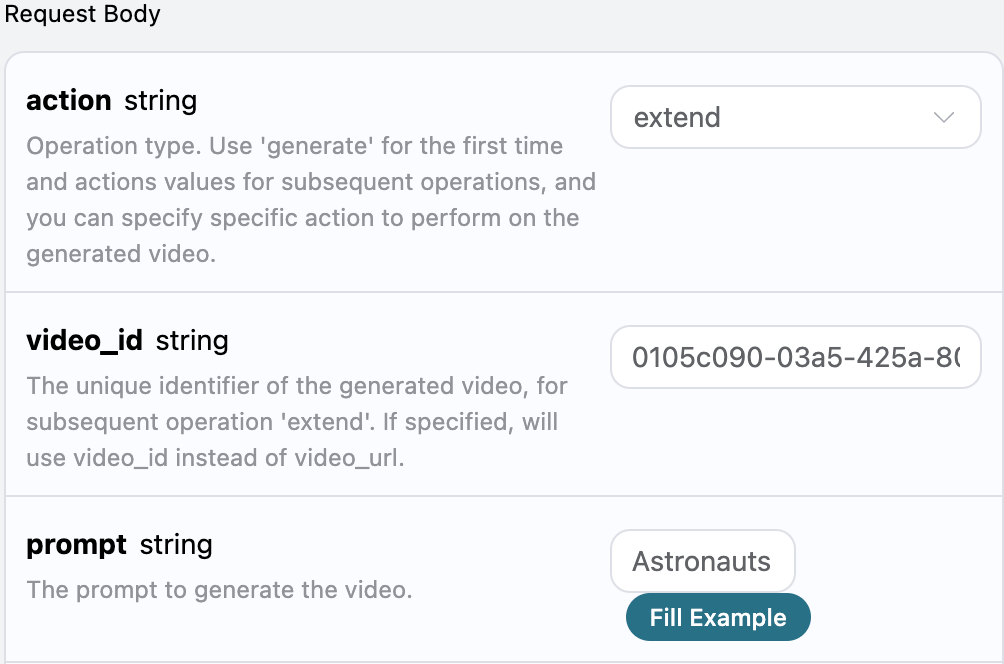
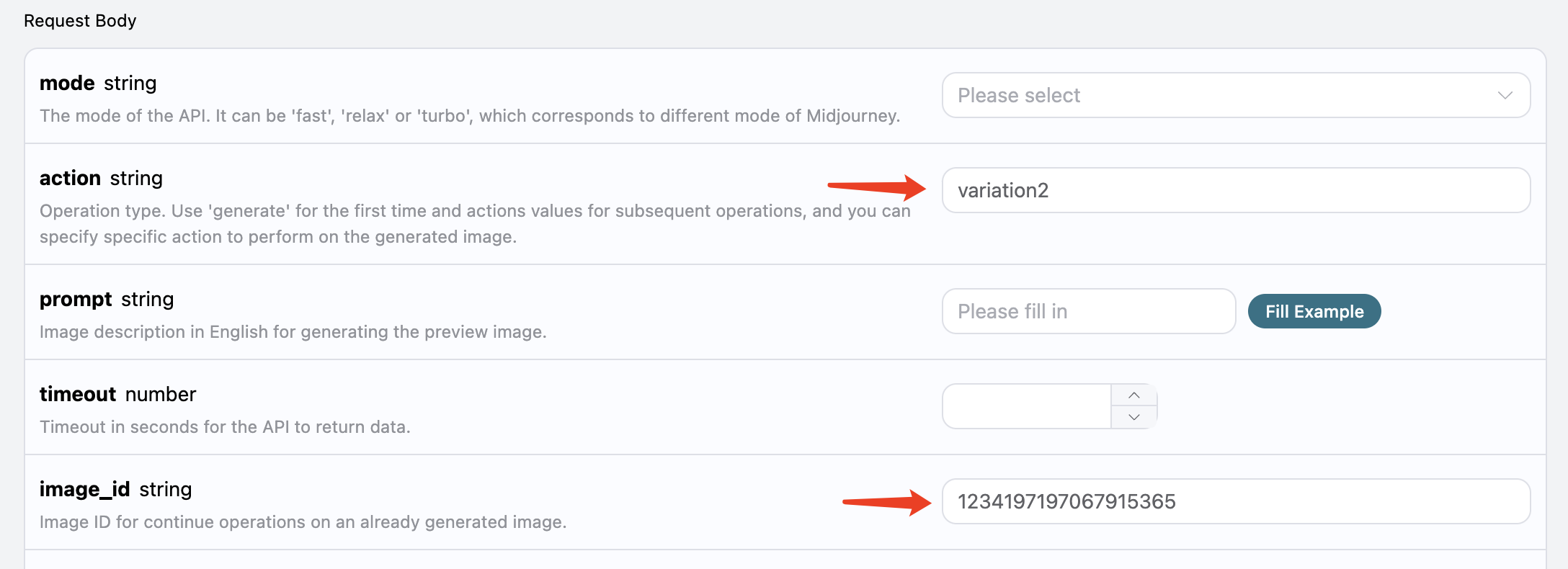
curl -X POST 'https://api.acedata.cloud/riffusion/audios' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "action": "extend", "model": "FUZZ-1.0 Pro", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_id": "b7376272-3902-49b4-a83b-62f7e6ab505c", "continue_at": 5 }'
{ "success": true, "task_id": "6388a0aa-b5ab-4485-baad-f0e0b7a7848c", "trace_id": "da143dbe-8263-45ac-b05a-1ed57dd4aa79", "data": [ { "id": "209e27e0-500c-44f3-9134-280690014920", "title": "City Rhythm", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/3a8378d5-94d4-49b7-9c0a-8432c0c4a39d/image/209e27e0-500c-44f3-9134-280690014920.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/3a8378d5-94d4-49b7-9c0a-8432c0c4a39d/audio/209e27e0-500c-44f3-9134-280690014920.m4a", "video_url": null, "created_at": "2025-06-23T02:00:53.473604Z", "model": null, "lyrics_timestamped": { "words": [ { "end": 4.48, "index_range": null, "line_index": 0, "start": 4.48, "text": "[Verse]", "wav2vec2_format": null }, ... { "end": 179.2, "index_range": null, "line_index": 29, "start": 178.56, "text": "high", "wav2vec2_format": null } ] }, "state": "succeeded", "style": "", "duration": 197.00850340136054 }, { "id": "ff50012e-ad1b-4b71-8d0e-6a633428a54f", "title": "Bright", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/3a8378d5-94d4-49b7-9c0a-8432c0c4a39d/image/ff50012e-ad1b-4b71-8d0e-6a633428a54f.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/3a8378d5-94d4-49b7-9c0a-8432c0c4a39d/audio/ff50012e-ad1b-4b71-8d0e-6a633428a54f.m4a", "video_url": null, "created_at": "2025-06-23T02:00:52.795796Z", "model": null, "lyrics_timestamped": { "words": [ { "end": 0.64, "index_range": null, "line_index": 0, "start": 0.64, "text": "[Verse]", "wav2vec2_format": null }, ... { "end": 186.88, "index_range": null, "line_index": 29, "start": 186.24, "text": "high", "wav2vec2_format": null } ] }, "state": "succeeded", "style": "", "duration": 213.85757369614512 } ] }
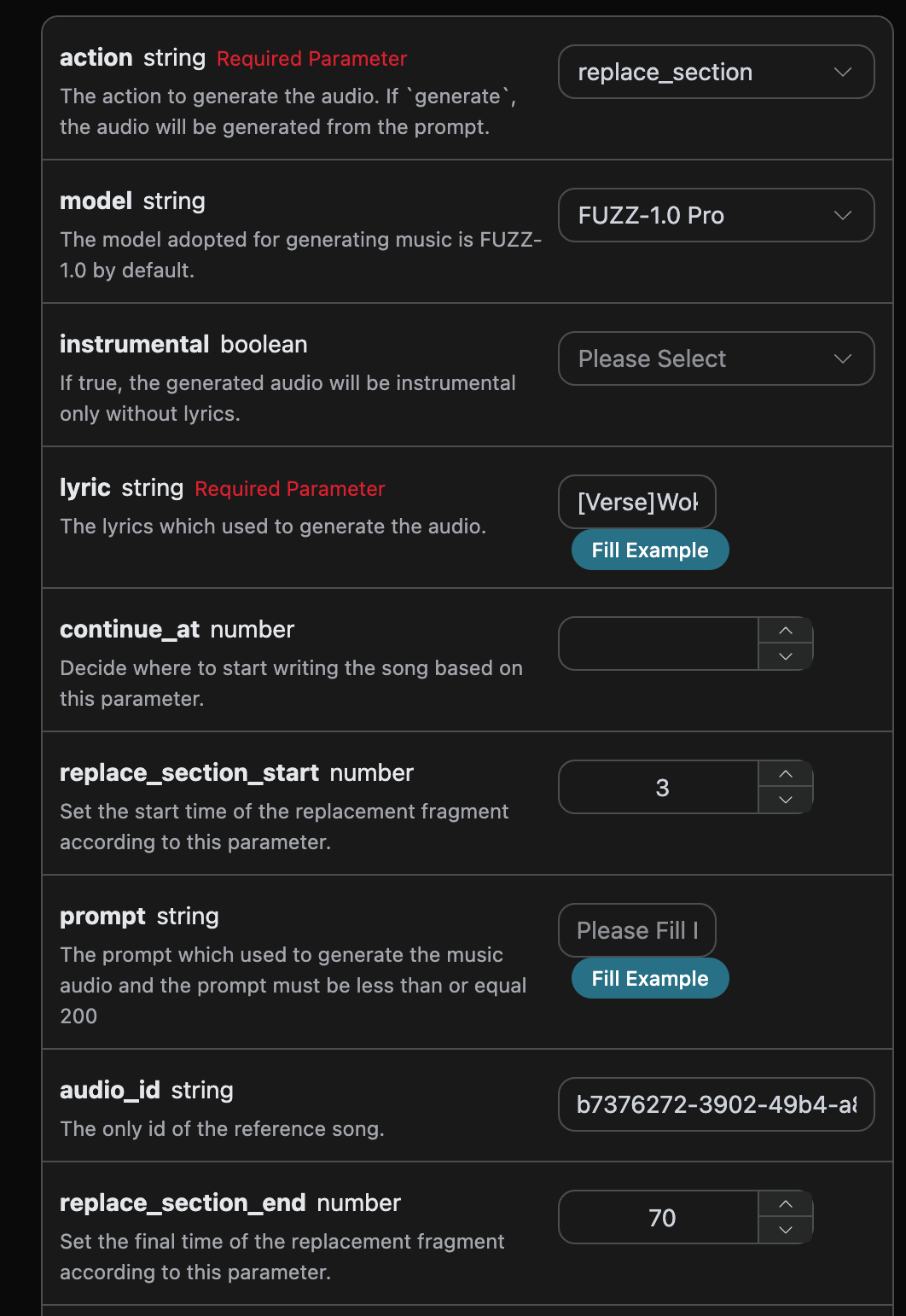
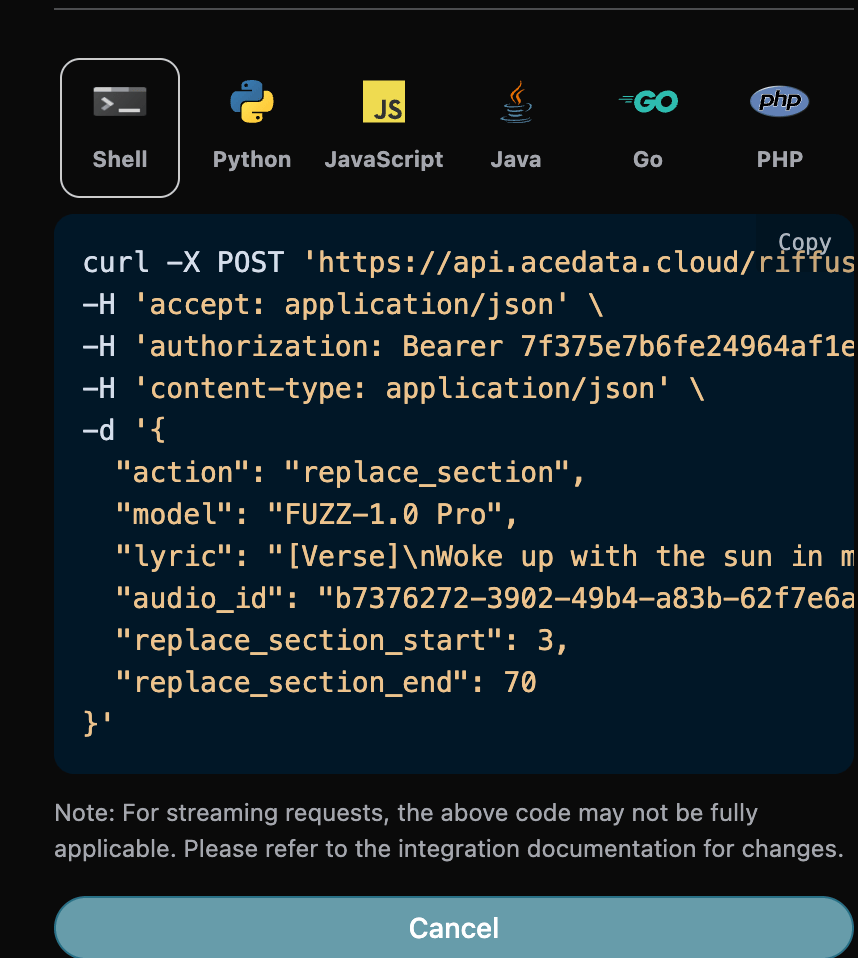
curl -X POST 'https://api.acedata.cloud/riffusion/audios' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "action": "replace_section", "model": "FUZZ-1.0 Pro", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_id": "b7376272-3902-49b4-a83b-62f7e6ab505c", "replace_section_start": 3, "replace_section_end": 70 }'
{ "success": true, "task_id": "73defcbf-f876-4dd6-b60e-4c1c5ecd4565", "trace_id": "9f639389-7218-4cdb-ade9-b34228bb0f21", "data": [ { "id": "037f5e9d-9da4-4d79-b58f-1f433b40d54d", "title": "Sunrise Joy", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/881ad27f-39c1-4c31-a789-ecc822e13b8c/image/037f5e9d-9da4-4d79-b58f-1f433b40d54d.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/881ad27f-39c1-4c31-a789-ecc822e13b8c/audio/037f5e9d-9da4-4d79-b58f-1f433b40d54d.m4a", "video_url": null, "created_at": "2025-06-23T02:18:43.031184Z", "model": null, "lyrics_timestamped": { "words": [ { "end": 3.84, "index_range": null, "line_index": 0, "start": 3.84, "text": "[Verse]", "wav2vec2_format": null }, ... { "end": 159.36, "index_range": null, "line_index": 29, "start": 159.36, "text": "high", "wav2vec2_format": null } ] }, "state": "succeeded", "style": "", "duration": 199.2201133786848 }, { "id": "97638295-068f-4cbc-b076-66f522449bd5", "title": "Sunrise", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/881ad27f-39c1-4c31-a789-ecc822e13b8c/image/97638295-068f-4cbc-b076-66f522449bd5.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/881ad27f-39c1-4c31-a789-ecc822e13b8c/audio/97638295-068f-4cbc-b076-66f522449bd5.m4a", "video_url": null, "created_at": "2025-06-23T02:18:56.267775Z", "model": null, "lyrics_timestamped": { "words": [ { "end": 3.84, "index_range": null, "line_index": 0, "start": 3.84, "text": "[Verse]", "wav2vec2_format": null }, ... { "end": 159.36, "index_range": null, "line_index": 29, "start": 159.36, "text": "high", "wav2vec2_format": null } ] }, "state": "succeeded", "style": "", "duration": 199.2201133786848 } ] }
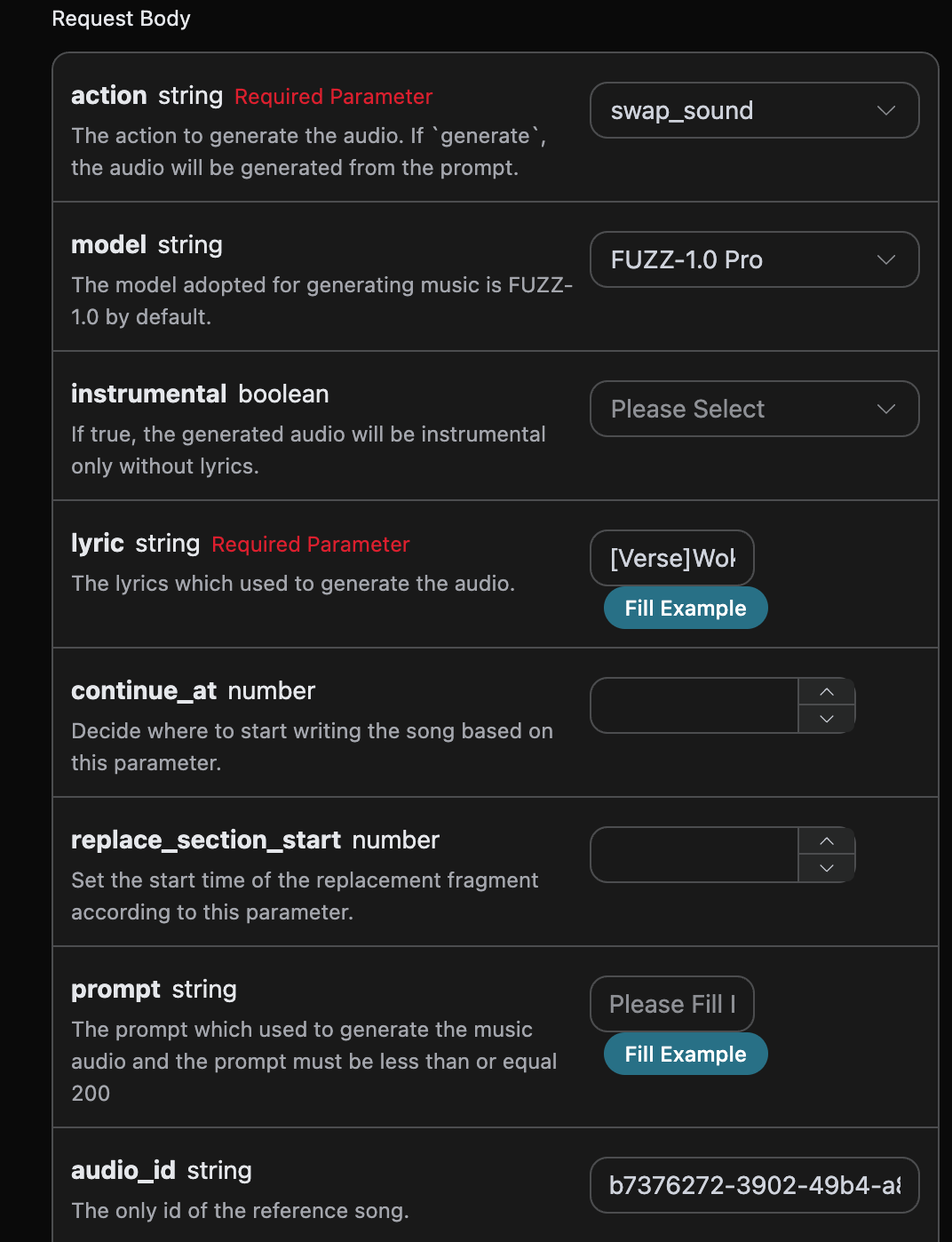
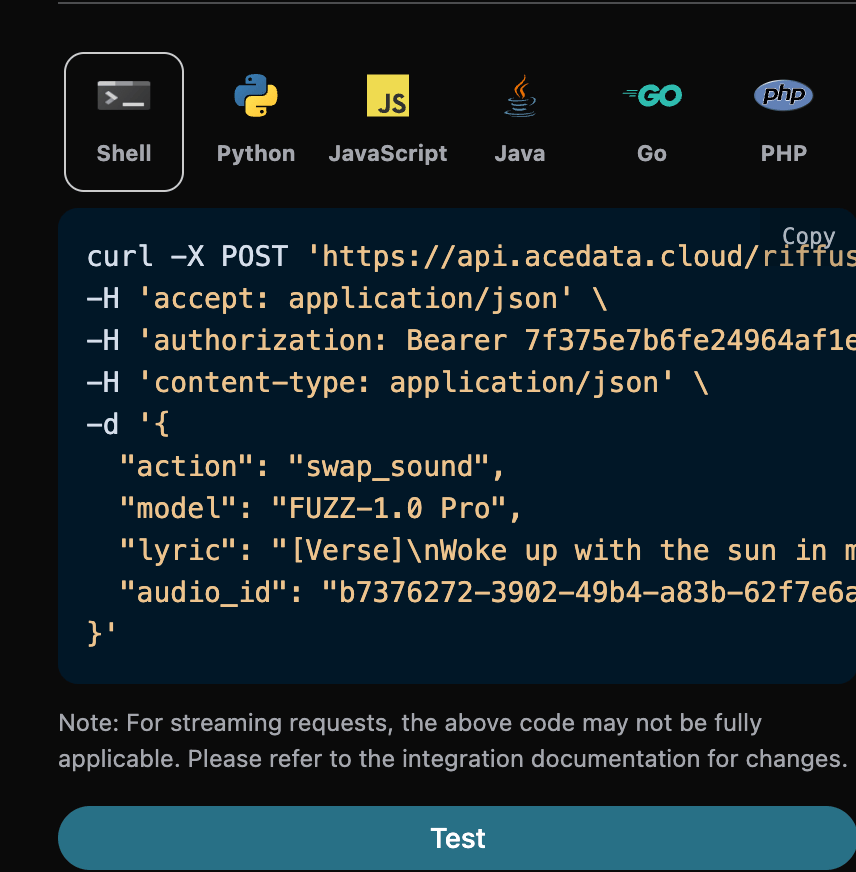
curl -X POST 'https://api.acedata.cloud/riffusion/audios' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "action": "swap_sound", "model": "FUZZ-1.0 Pro", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_id": "b7376272-3902-49b4-a83b-62f7e6ab505c" }'
{ "success": true, "task_id": "93279260-5ca1-42d8-bde1-1fa62e0f5027", "trace_id": "bc4e28db-4897-4ffc-9e03-45f43da7a21c", "data": [ { "id": "242035c0-8ac2-4f0b-a19c-ac2fa49d4df3", "title": "Brightside", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/36494e8a-eb82-4d89-bbfa-ec719e19572b/image/242035c0-8ac2-4f0b-a19c-ac2fa49d4df3.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/36494e8a-eb82-4d89-bbfa-ec719e19572b/audio/242035c0-8ac2-4f0b-a19c-ac2fa49d4df3.m4a", "video_url": null, "created_at": "2025-06-23T02:02:32.799561Z", "model": null, "lyrics_timestamped": { "words": [ { "end": 1.28, "index_range": null, "line_index": 0, "start": 1.28, "text": "[Verse]", "wav2vec2_format": null }, ... { "end": 195.84, "index_range": null, "line_index": 29, "start": 195.84, "text": "high", "wav2vec2_format": null } ] }, "state": "succeeded", "style": "", "duration": 197.2696371882086 }, { "id": "594fe702-6c71-4b0c-abb6-21b58efc74a6", "title": "Sunrise", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/36494e8a-eb82-4d89-bbfa-ec719e19572b/image/594fe702-6c71-4b0c-abb6-21b58efc74a6.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/36494e8a-eb82-4d89-bbfa-ec719e19572b/audio/594fe702-6c71-4b0c-abb6-21b58efc74a6.m4a", "video_url": null, "created_at": "2025-06-23T02:02:30.523279Z", "model": null, "lyrics_timestamped": { "words": [ { "end": 0.64, "index_range": null, "line_index": 0, "start": 0.64, "text": "[Verse]", "wav2vec2_format": null }, ... { "end": 192.64, "index_range": null, "line_index": 29, "start": 192.64, "text": "high", "wav2vec2_format": null } ] }, "state": "succeeded", "style": "", "duration": 196.7198866213152 } ] }
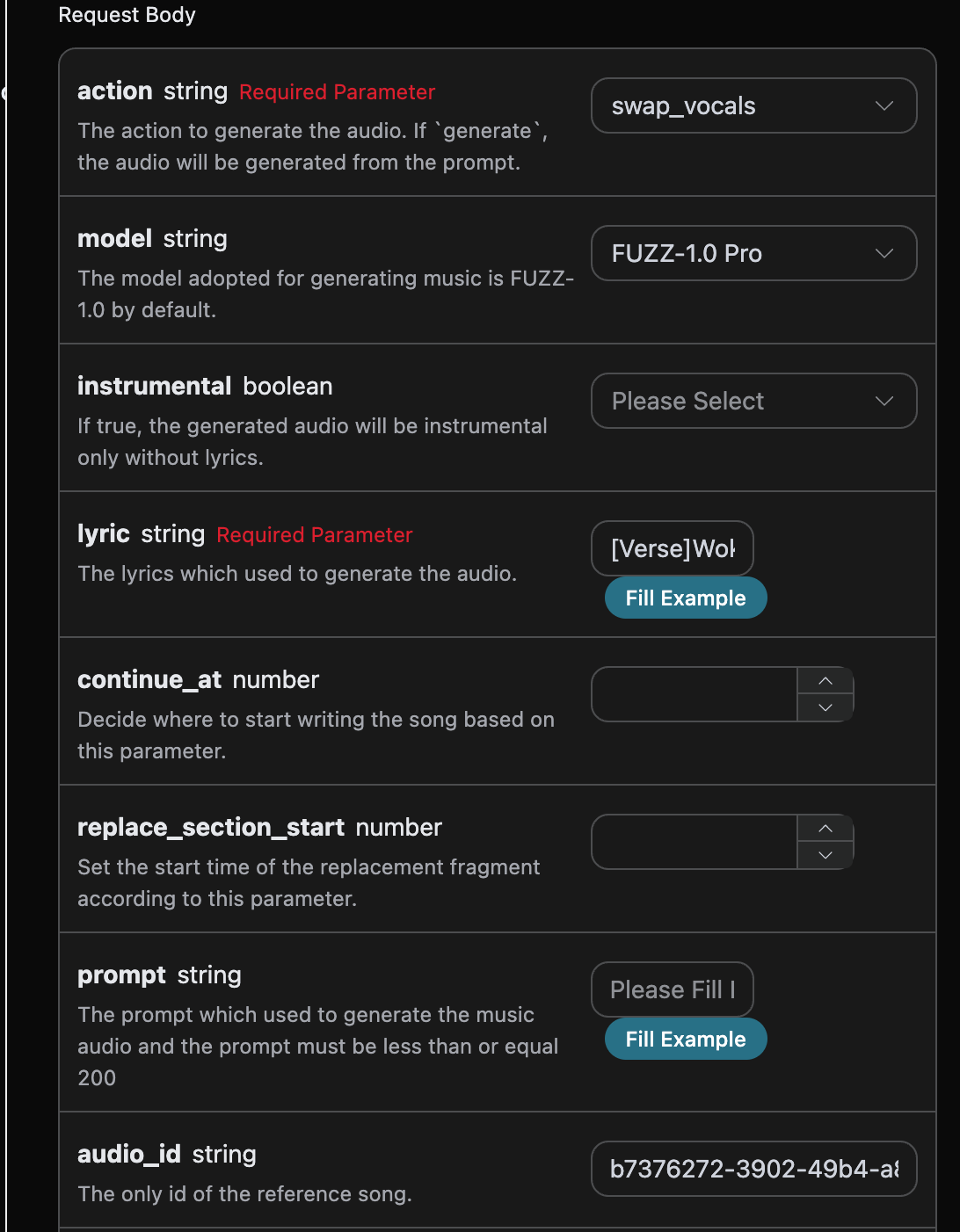
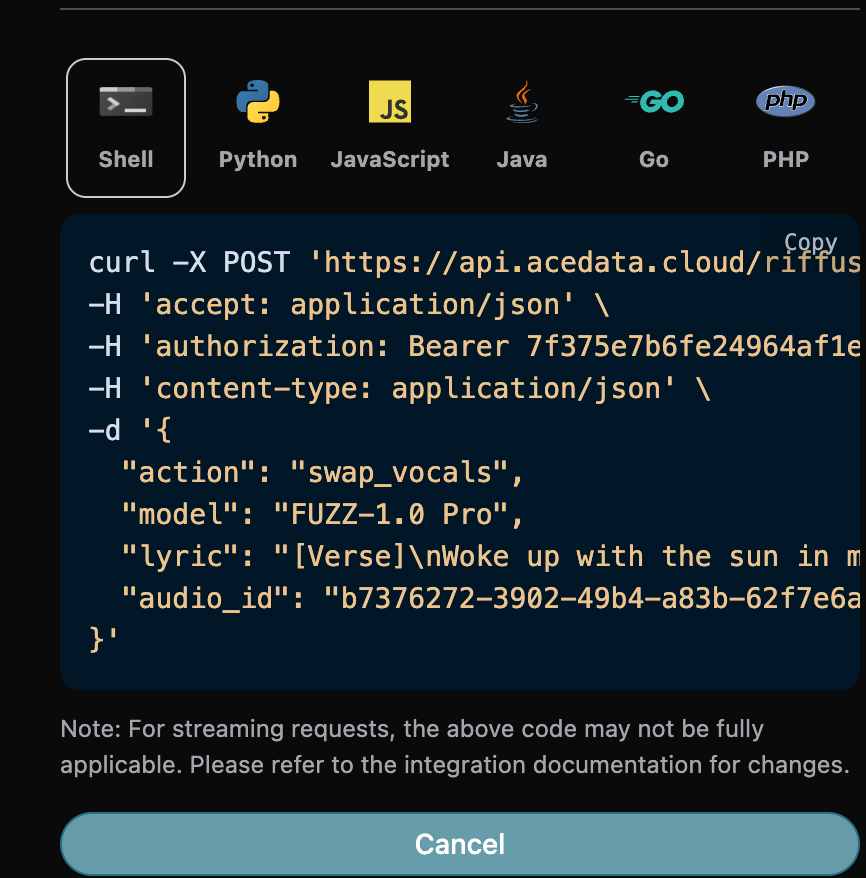
curl -X POST 'https://api.acedata.cloud/riffusion/audios' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "action": "swap_vocals", "model": "FUZZ-1.0 Pro", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_id": "b7376272-3902-49b4-a83b-62f7e6ab505c" }'
{ "success": true, "task_id": "a6e0d456-189b-4c78-9232-2fe72166ab39", "trace_id": "ee5769d4-ae94-4e5a-a85f-b3c0ddc2e48e", "data": [ { "id": "b8b1ed14-f43c-4738-a697-60ba24b6049d", "title": "Uplift", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/25ce4ddd-e48c-42e2-9ea3-8e03380508f2/image/b8b1ed14-f43c-4738-a697-60ba24b6049d.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/25ce4ddd-e48c-42e2-9ea3-8e03380508f2/audio/b8b1ed14-f43c-4738-a697-60ba24b6049d.m4a", "video_url": null, "created_at": "2025-06-23T02:04:18.477032Z", "model": null, "lyrics_timestamped": { "words": [ { "end": 2.56, "index_range": null, "line_index": 0, "start": 2.56, "text": "[Verse]", "wav2vec2_format": null }, ... { "end": 186.88, "index_range": null, "line_index": 29, "start": 171.52, "text": "high", "wav2vec2_format": null } ] }, "state": "succeeded", "style": "", "duration": 195.55968253968254 }, { "id": "dfd6eb9c-a1f3-4e1f-bbf9-e0b9625e459f", "title": "Vivid Rise", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/25ce4ddd-e48c-42e2-9ea3-8e03380508f2/image/dfd6eb9c-a1f3-4e1f-bbf9-e0b9625e459f.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/25ce4ddd-e48c-42e2-9ea3-8e03380508f2/audio/dfd6eb9c-a1f3-4e1f-bbf9-e0b9625e459f.m4a", "video_url": null, "created_at": "2025-06-23T02:04:27.140387Z", "model": null, "lyrics_timestamped": { "words": [ { "end": 1.28, "index_range": null, "line_index": 0, "start": 1.28, "text": "[Verse]", "wav2vec2_format": null }, ... { "end": 188.8, "index_range": null, "line_index": 29, "start": 188.16, "text": "high", "wav2vec2_format": null } ] }, "state": "succeeded", "style": "", "duration": 196.07185941043085 } ] }
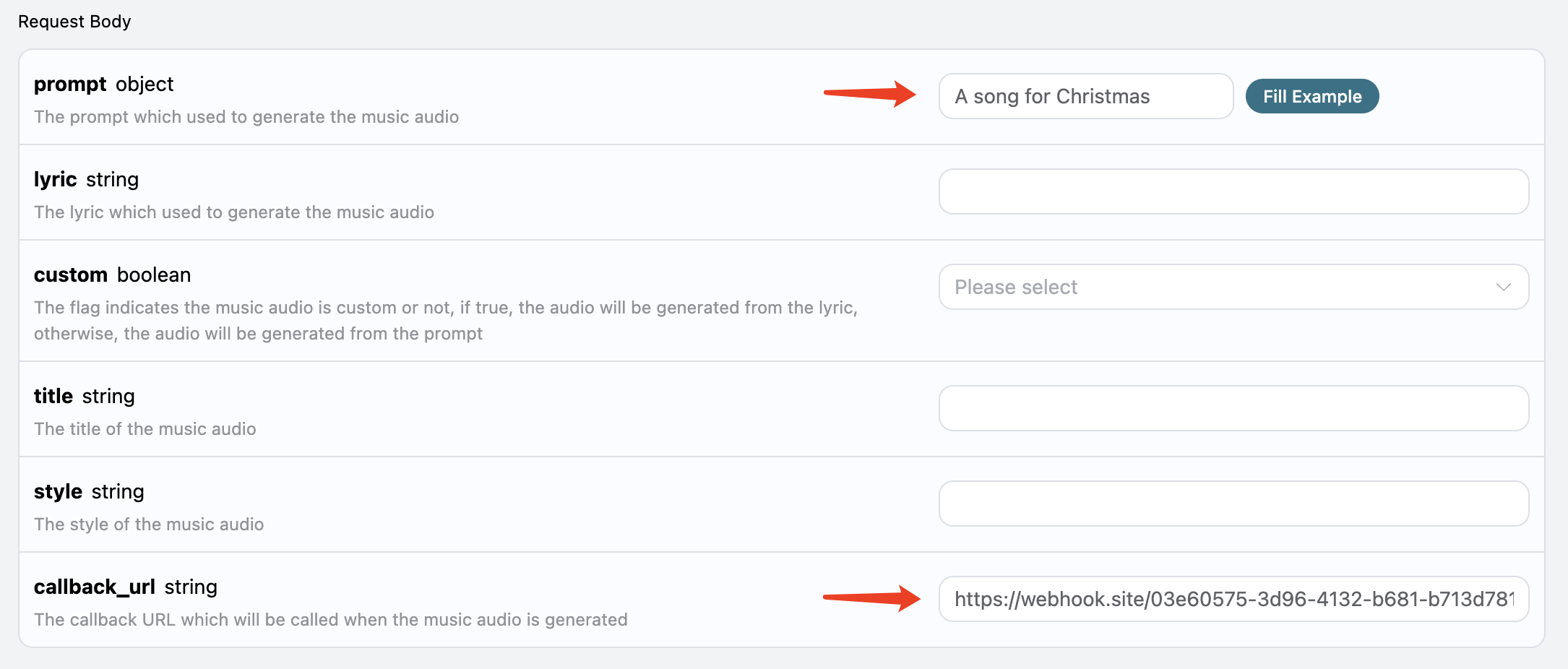
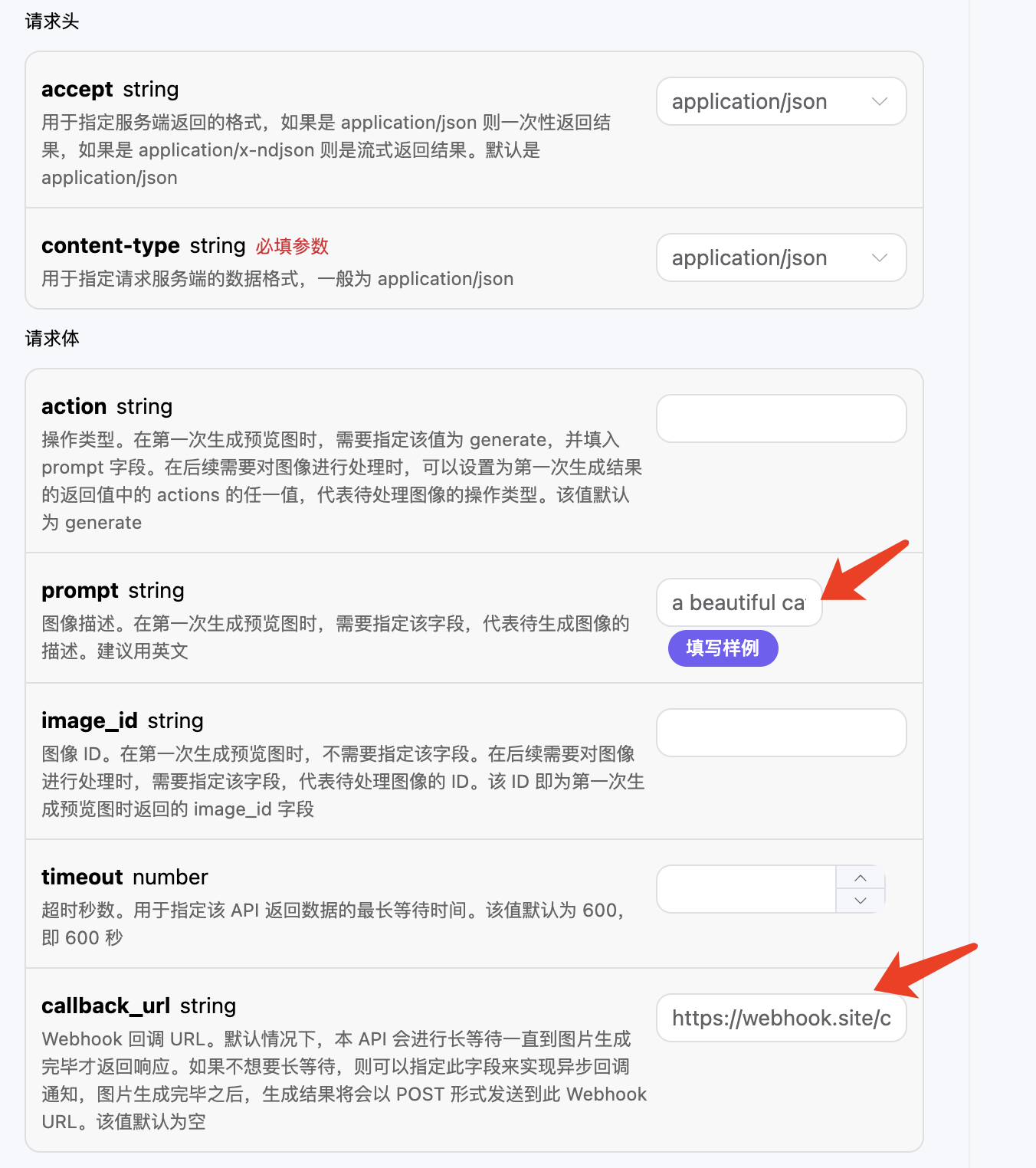
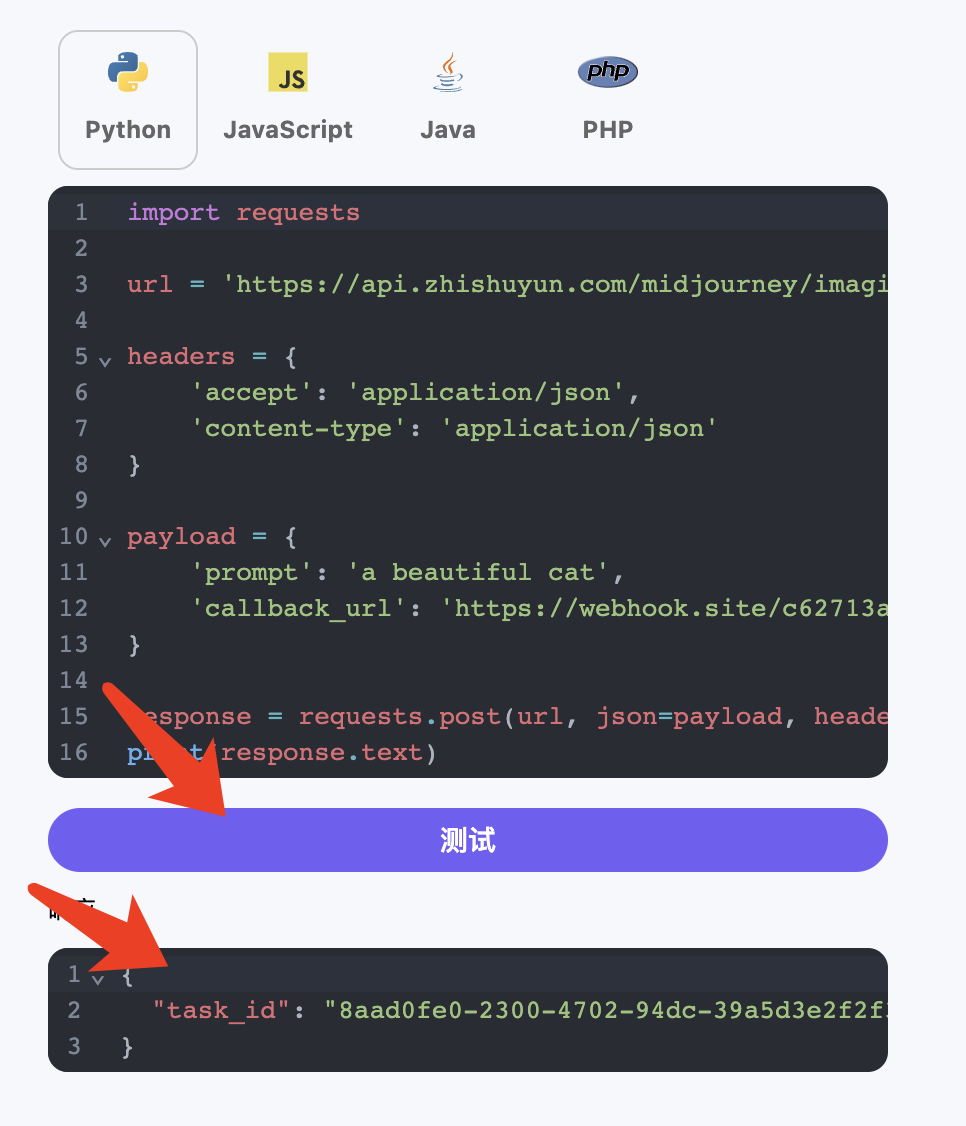
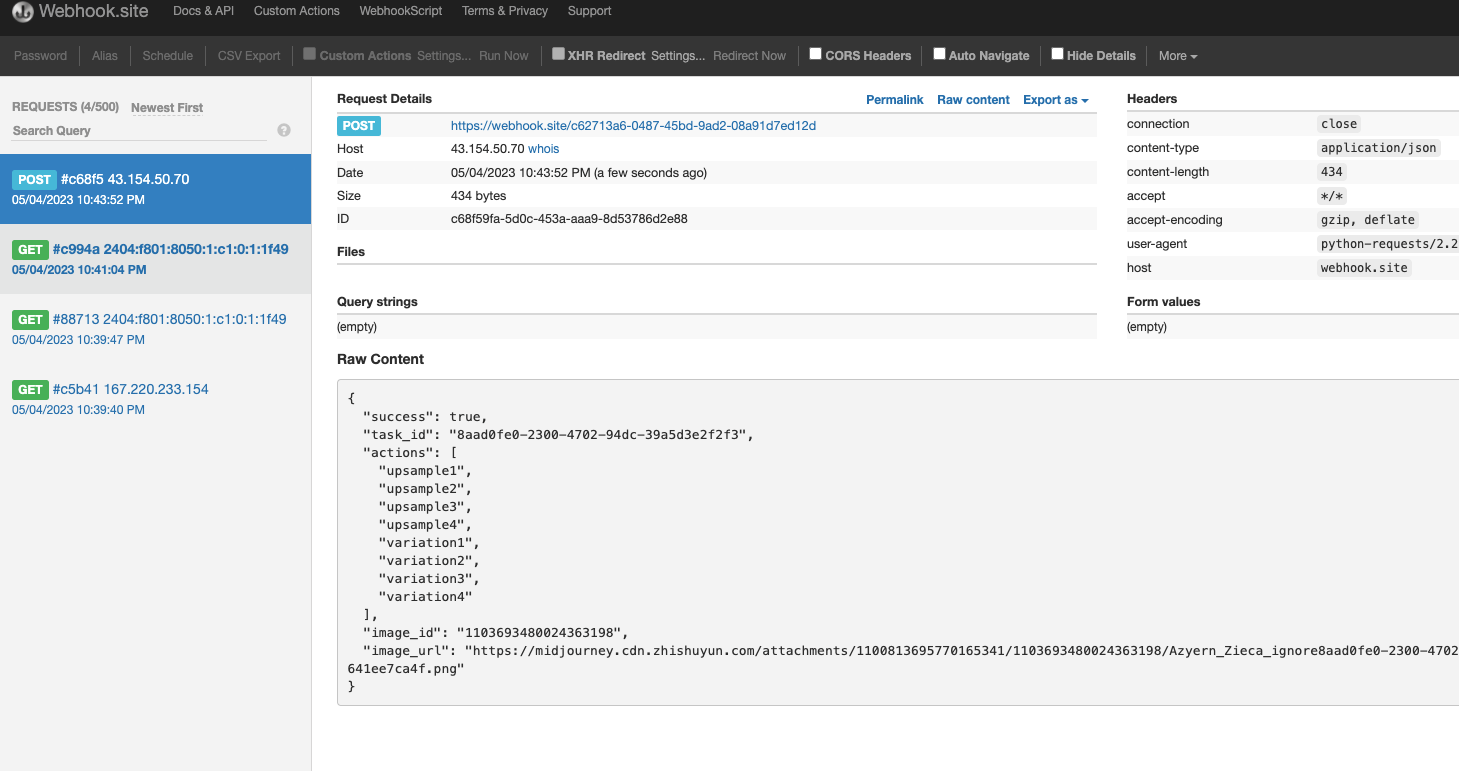
异步回调
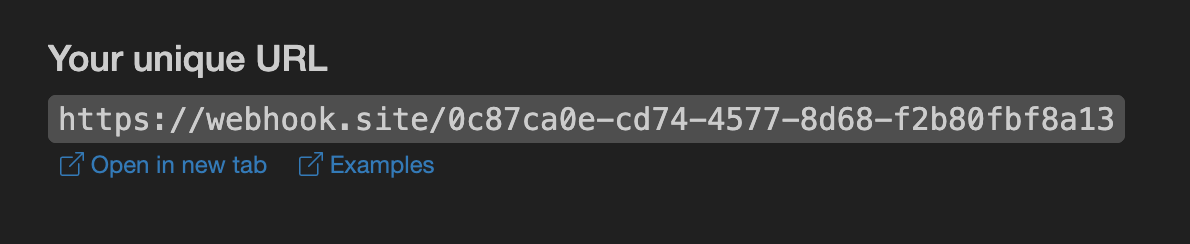
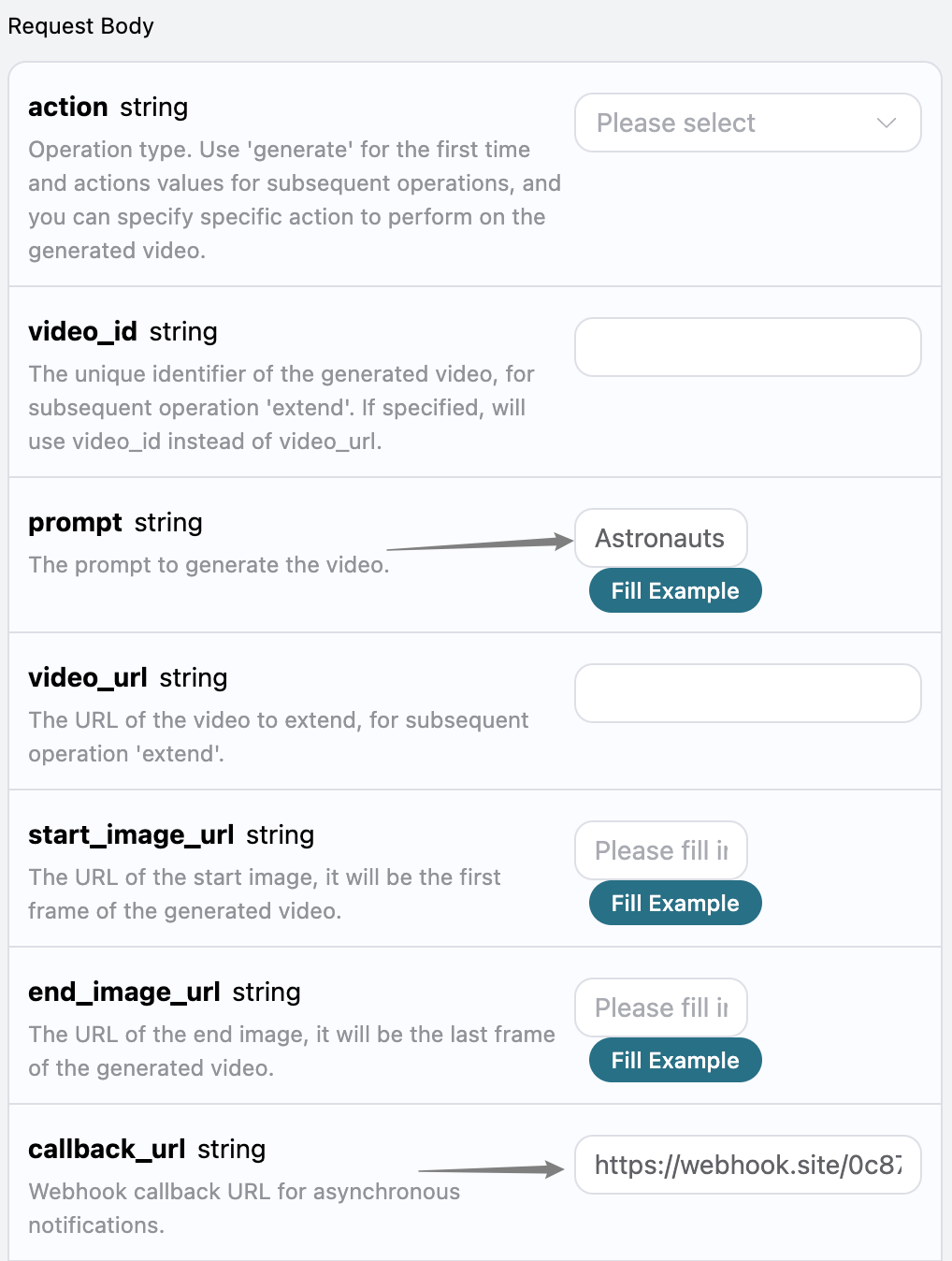
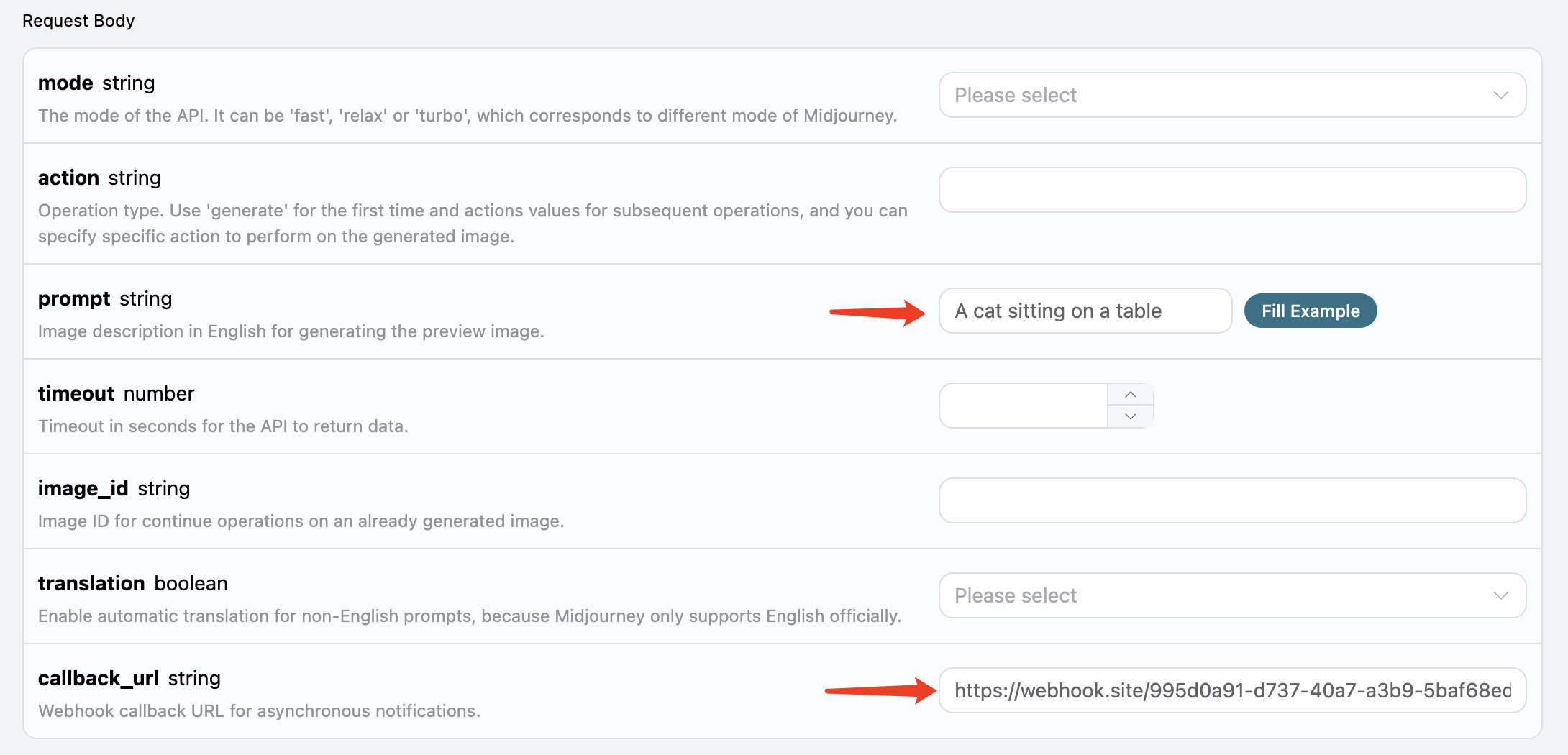
由于 Riffusion Audios Generation API 生成的时间有时候会相对较长,如果 API 长时间无响应,HTTP 请求会一直保持连接,导致额外的系统资源消耗,所以本 API 也提供了异步回调的支持。
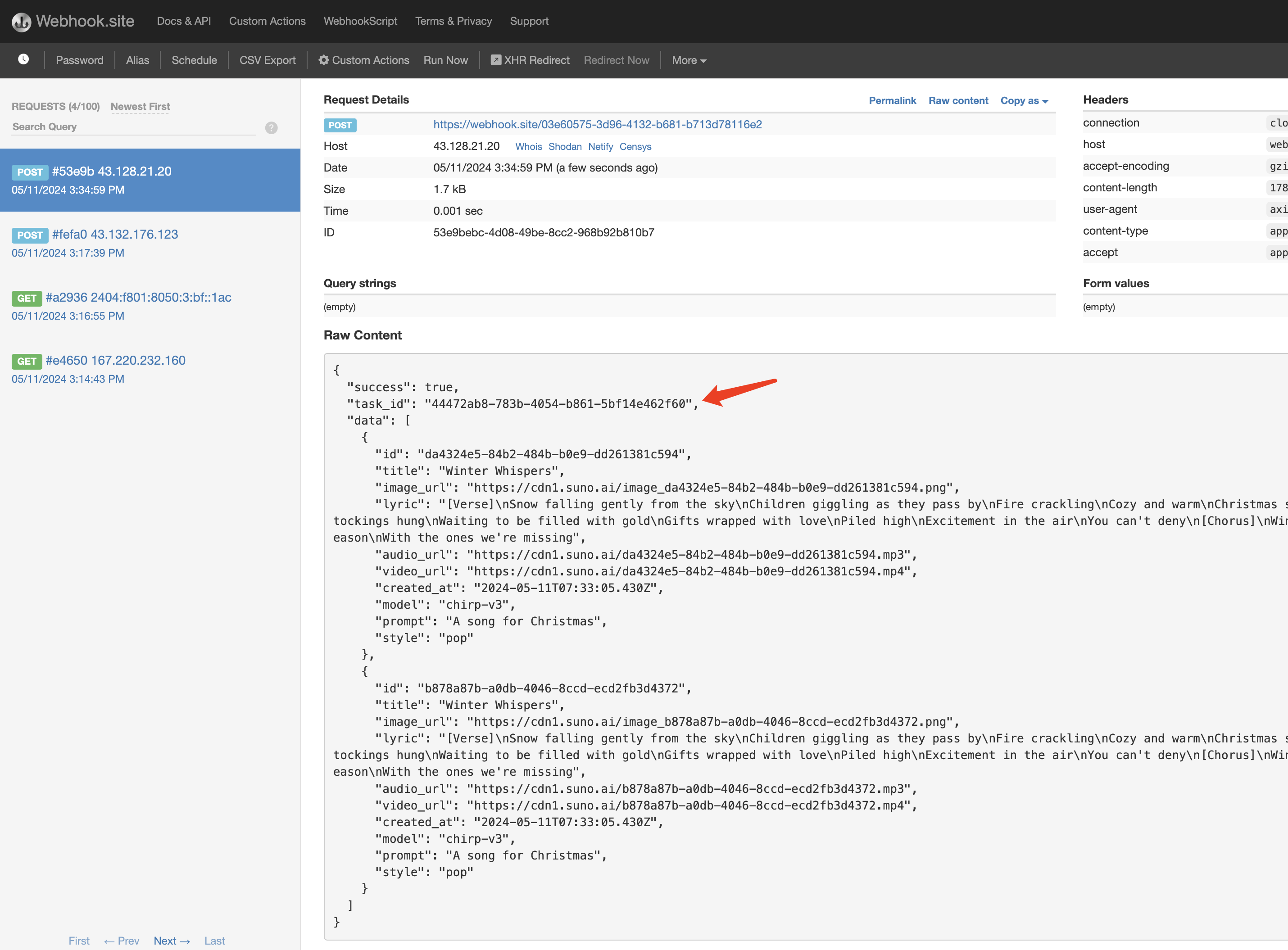
整体流程是:客户端发起请求的时候,额外指定一个 callback_url 字段,客户端发起 API 请求之后,API 会立马返回一个结果,包含一个 task_id 的字段信息,代表当前的任务 ID。当任务完成之后,生成任务的结果会通过 POST JSON 的形式发送到客户端指定的 callback_url,其中也包括了 task_id 字段,这样任务结果就可以通过 ID 关联起来了。
{ "success": true, "task_id": "9939767a-7f9c-4f43-aabf-ca68fe385f3c", "trace_id": "13a86870-e705-45d0-8447-82a08701c0fa", "data": [ { "id": "72e6c476-0116-4da9-ae34-f78190020b35", "title": "Rise", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/9b9f3281-6b47-44ac-8e4b-3b0d105e163d/image/72e6c476-0116-4da9-ae34-f78190020b35.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/9b9f3281-6b47-44ac-8e4b-3b0d105e163d/audio/72e6c476-0116-4da9-ae34-f78190020b35.m4a", "video_url": null, "created_at": "2025-06-15T15:43:22.432605Z", "model": "FUZZ-1.0", "state": "succeeded", "style": "acoustic folk, finger picking", "duration": 184.96 }, { "id": "7f4f5c20-4395-4583-9dbb-735b9bb86957", "title": "Luminance", "image_url": "https://storage.googleapis.com/corpusant-app-public/riffs/9b9f3281-6b47-44ac-8e4b-3b0d105e163d/image/7f4f5c20-4395-4583-9dbb-735b9bb86957.jpg", "lyric": "[Verse]\nWoke up with the sun in my eyes\nNo clouds above just blue in the skies\nShoes on my feet I’m ready to run\nEvery step feels like a loaded gun\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Verse 2]\nDancing through the city streets\nA rhythm pounding in my heartbeat\nStrangers smile it’s catching on\nThis world’s a stage we’re all a song\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high\n[Bridge]\nThrow your worries out the door\nLet them sink to the ocean floor\nWe’re alive and it’s enough\nLife is messy but it’s love\n[Chorus]\nHappy days are rolling in\nLet the joy beneath my skin\nNo more shadows no more lies\nJust the truth that lifts me high", "audio_url": "https://storage.googleapis.com/corpusant-app-public/riffs/9b9f3281-6b47-44ac-8e4b-3b0d105e163d/audio/7f4f5c20-4395-4583-9dbb-735b9bb86957.m4a", "video_url": null, "created_at": "2025-06-15T15:43:21.574561Z", "model": "FUZZ-1.0", "state": "succeeded", "style": "deep bass, ethereal electronic", "duration": 165.12 } ] }
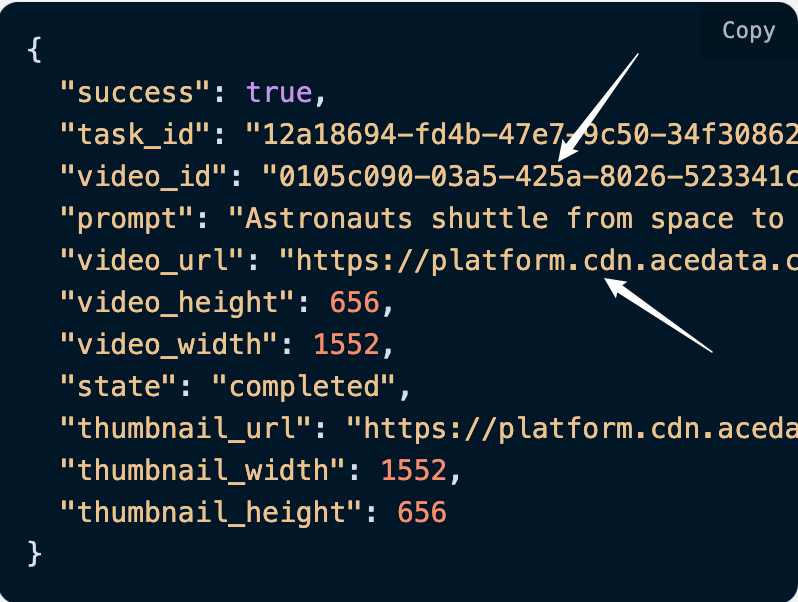
可以看到结果中有一个 task_id 字段,其他的字段都和上文类似,通过该字段即可实现任务的关联。
错误处理
在调用 API 时,如果遇到错误,API 会返回相应的错误代码和信息。例如:
400 token_mismatched:Bad request, possibly due to missing or invalid parameters.
400 api_not_implemented:Bad request, possibly due to missing or invalid parameters.
401 invalid_token:Unauthorized, invalid or missing authorization token.
429 too_many_requests:Too many requests, you have exceeded the rate limit.
500 api_error:Internal server error, something went wrong on the server.
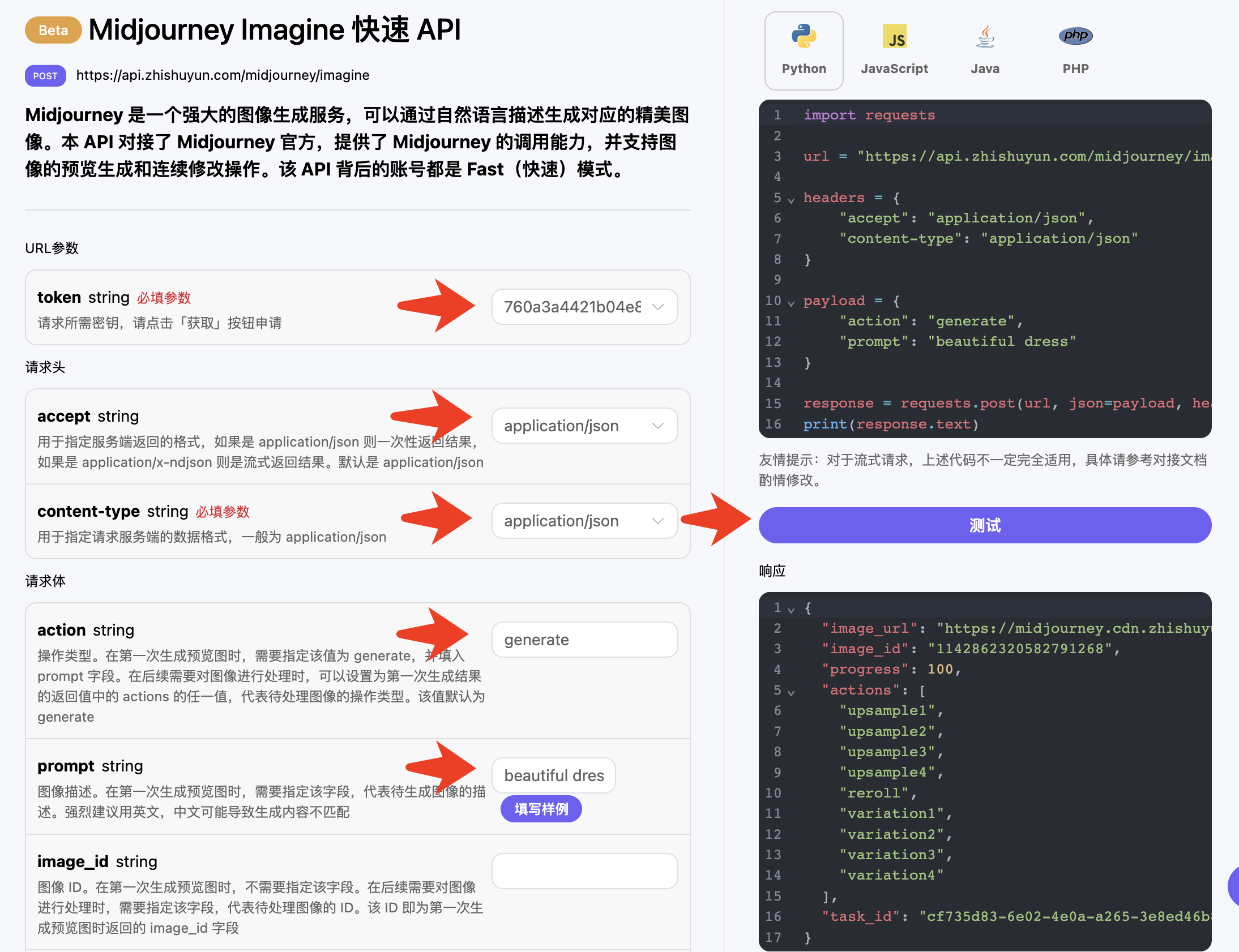
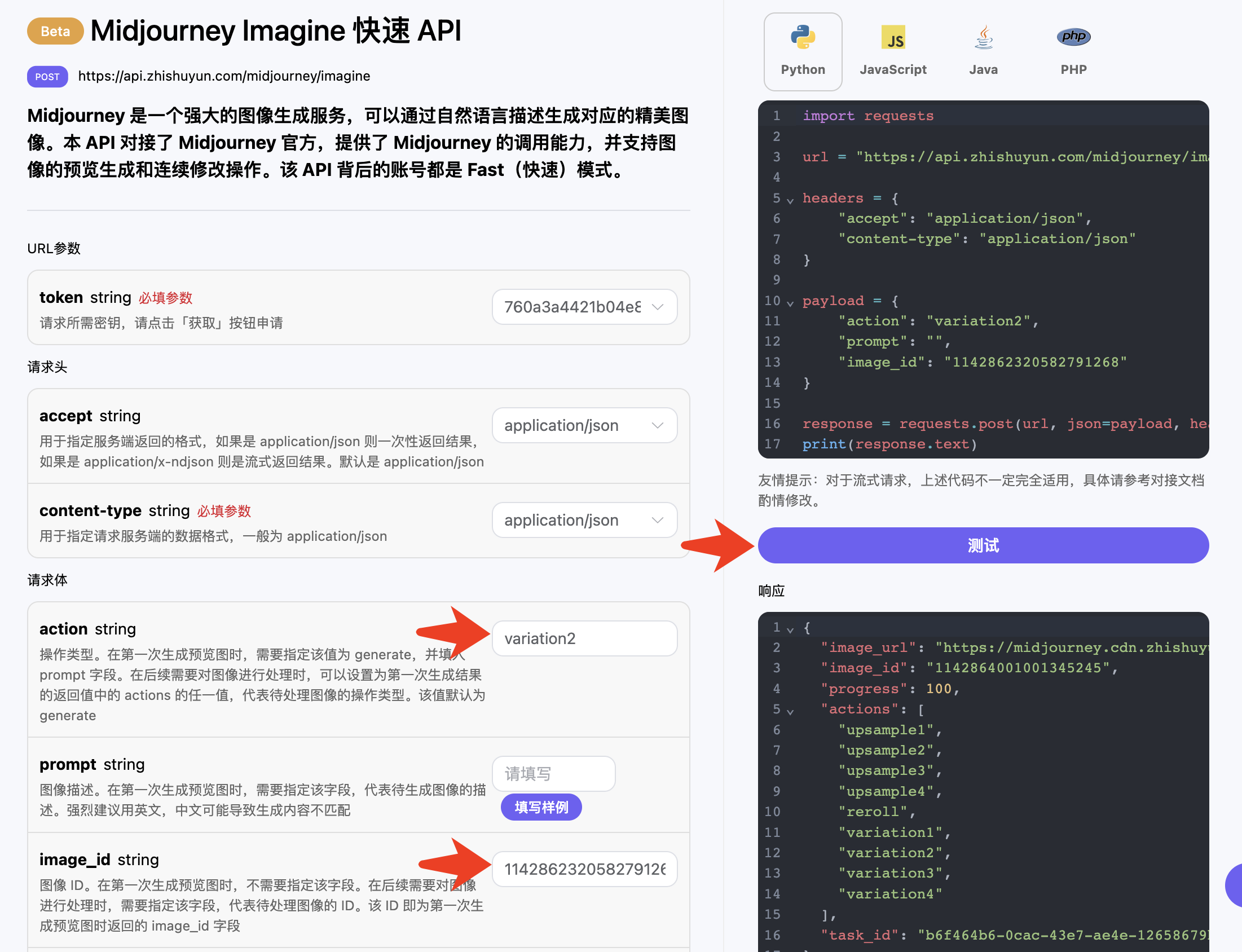
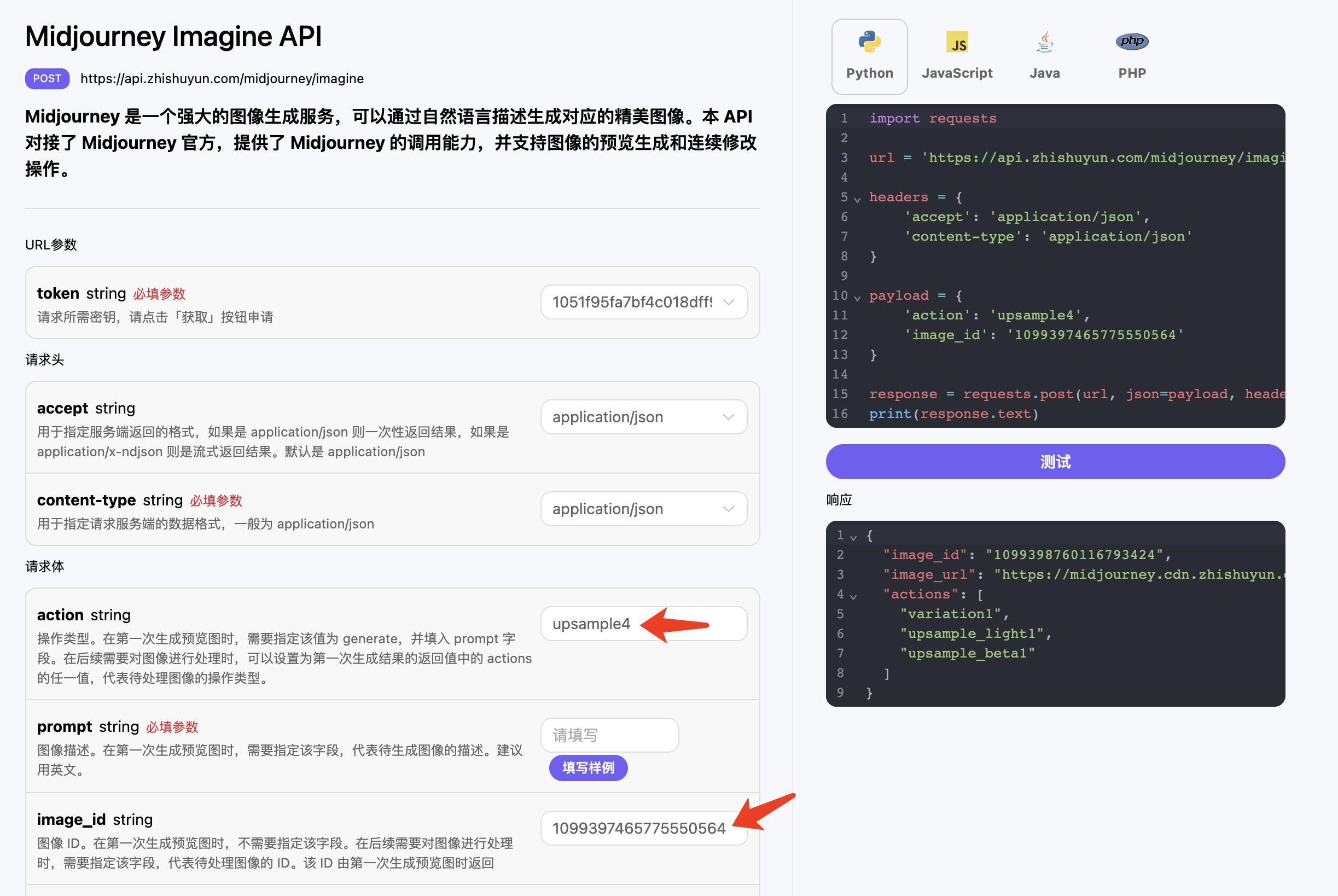
我们还可以通过 position 参数控制二维码的位置,比如说一张图片里面有一个女生穿裙子,而我们想要把二维码放在裙子的位置并与之融合起来,我们就可以尝试改下二维码的位置,调用样例如下:
1 2 3 4 5 6 7 8 9 10
curl -X POST "https://api.zhishuyun.com/qrart/generate?token={token}" \ -H "accept: application/json" \ -H "content-type: application/json" \ -d '{ "type": "link", "content": "https://data.zhishuyun.com", "prompt": "one of the beautiful girls in the moonlight in the background, in the style of pixelated chaos, rococo-inspired art, dark white and sky-blue, made of plastic, delicate flowers, gongbi, wimmelbilder", "position": "bottom", "aspect_ratio": "576x1008" }'
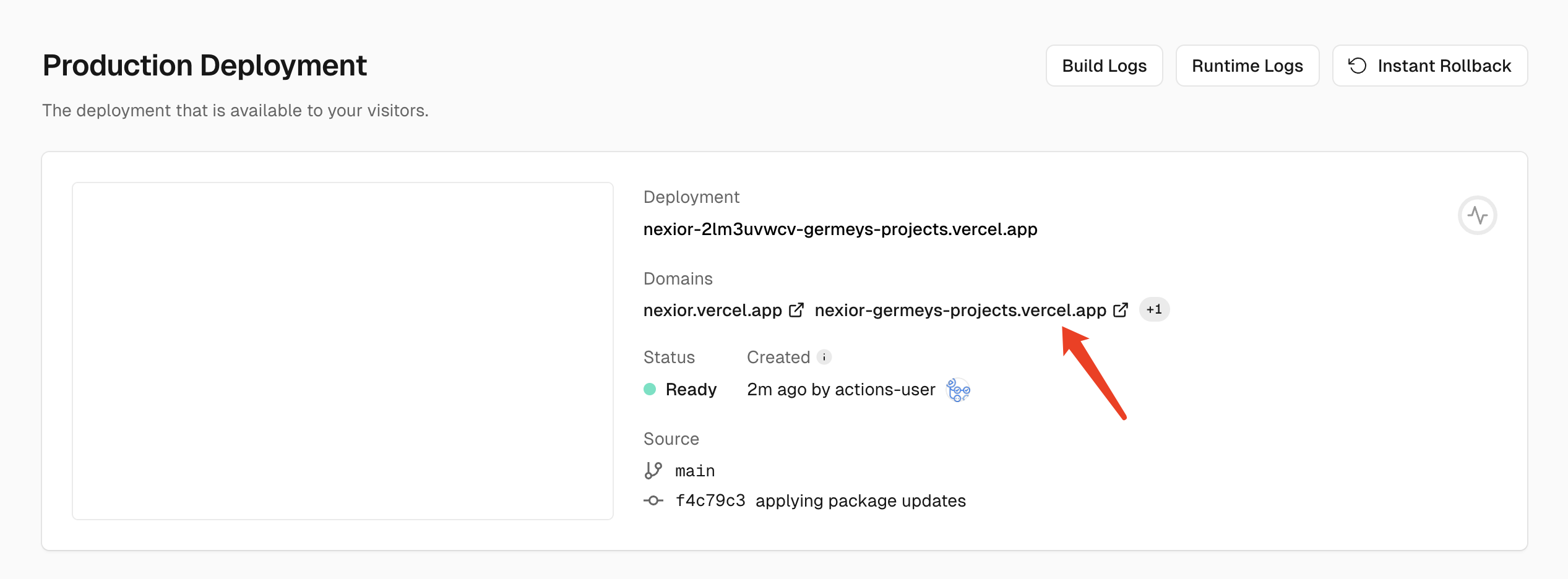
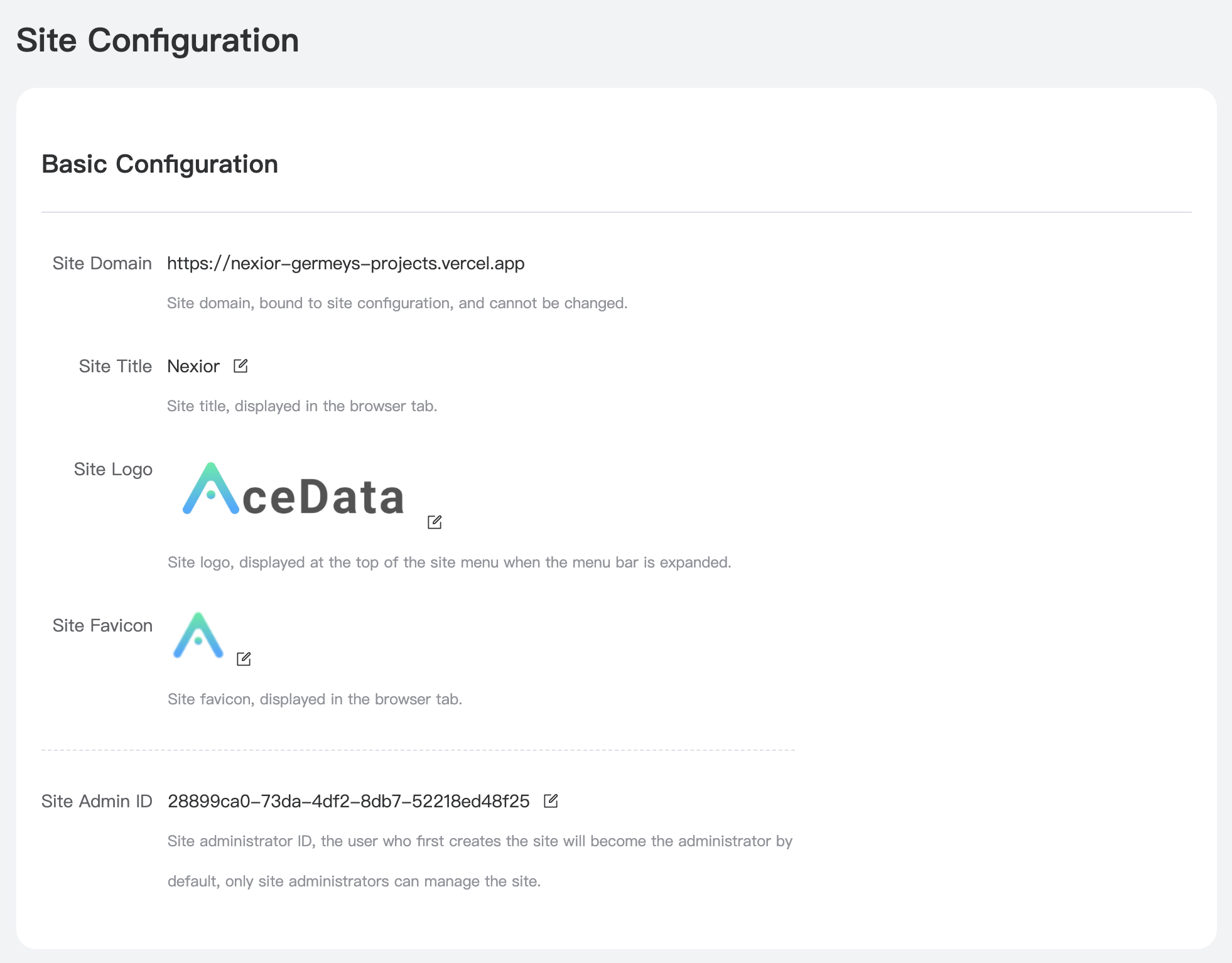
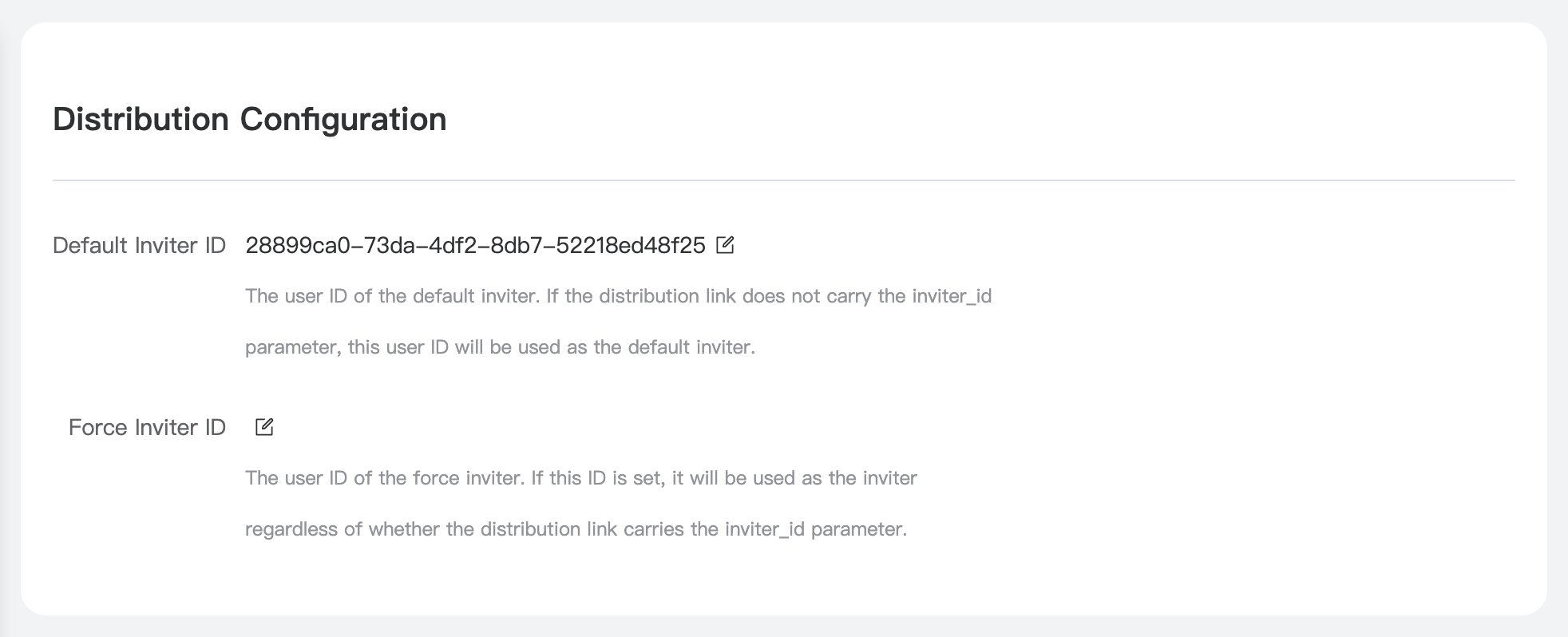
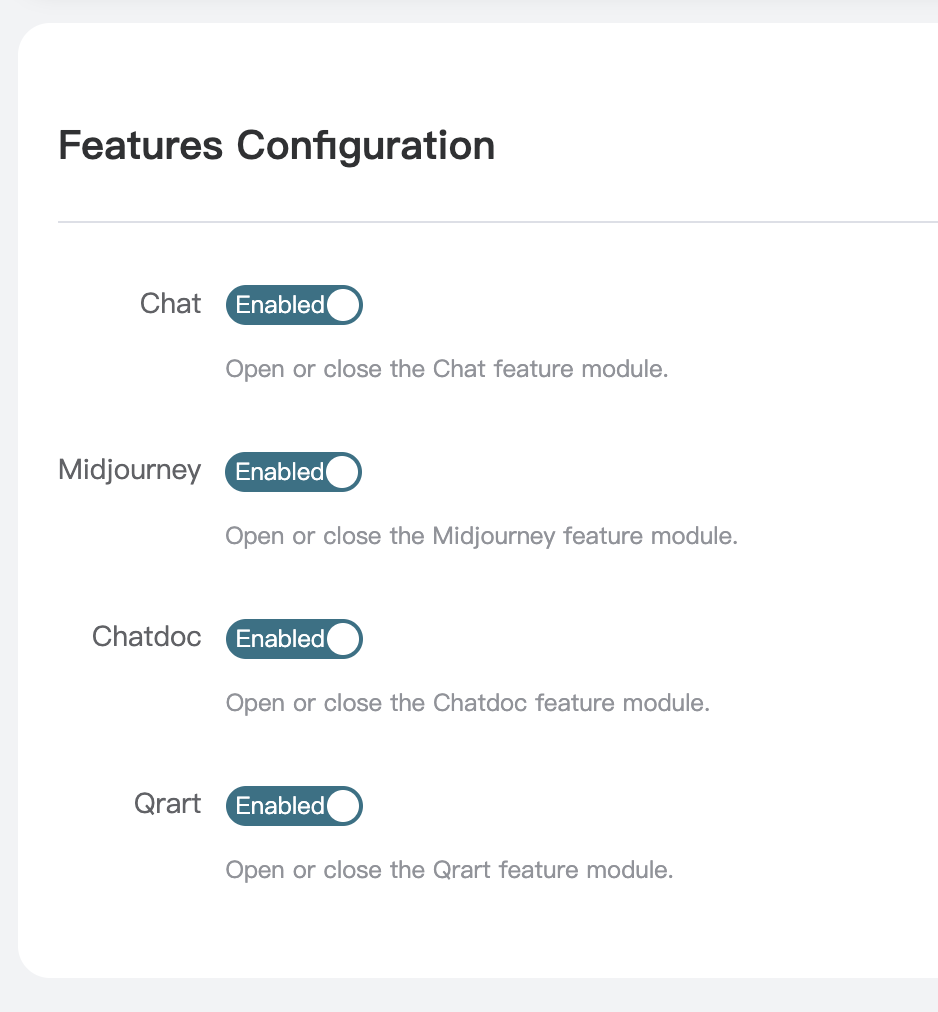
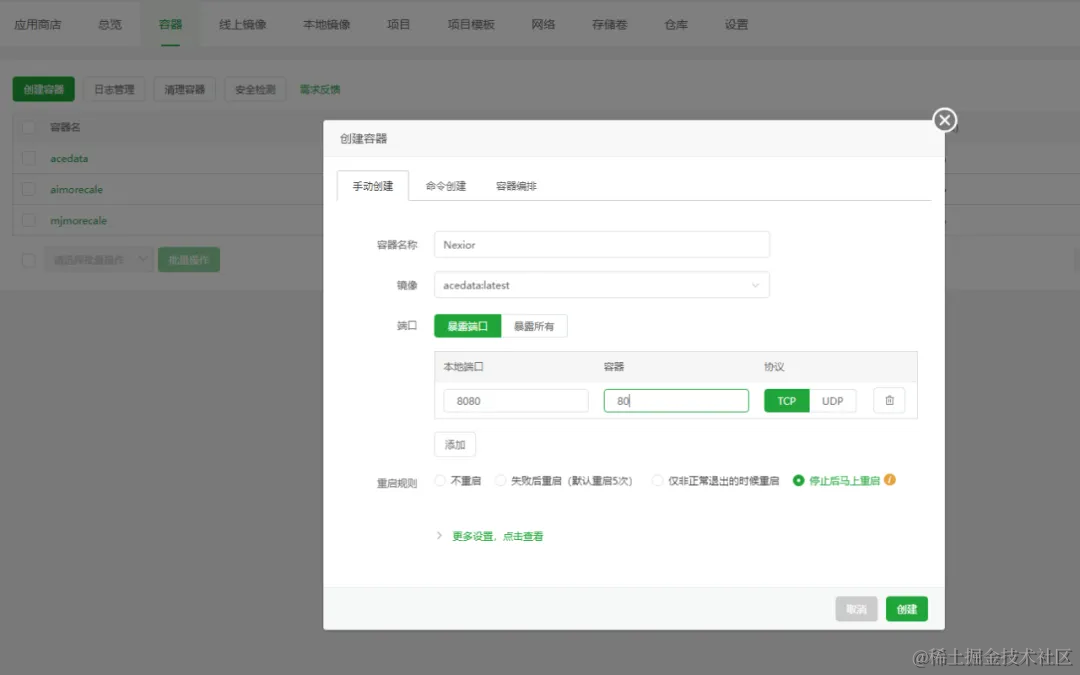
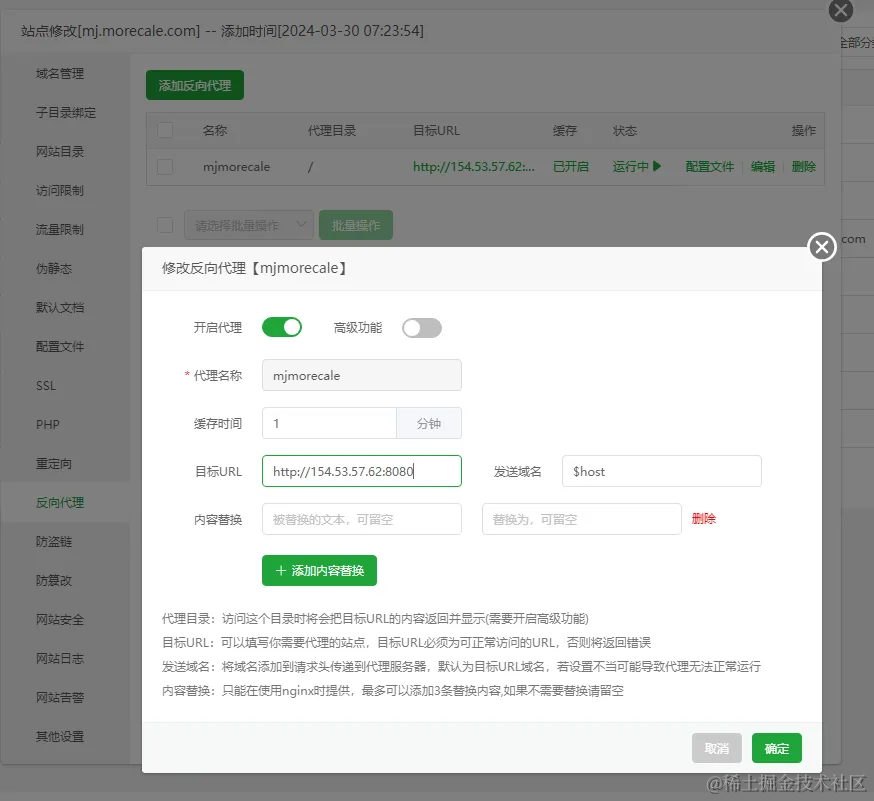
Nexior 是 GitHub 上的一个开源项目,利用它我们可以一键部署自己的 AI 应用站点,包括 AI 问答、Midjourney 绘画、知识库问答、艺术二维码等应用,无需自己开发 AI 系统、无需采购 AI 账号、无需关心 API 支持、无需配置支付系统,零启动成本,无风险通过 AI 赚取收益。
本文章会介绍 Nexior 项目在 Vercel 上的部署流程,无需任何编程技巧即可几分钟部署一套属于自己的 AI 站点,并轻松利用该站点获取收益。
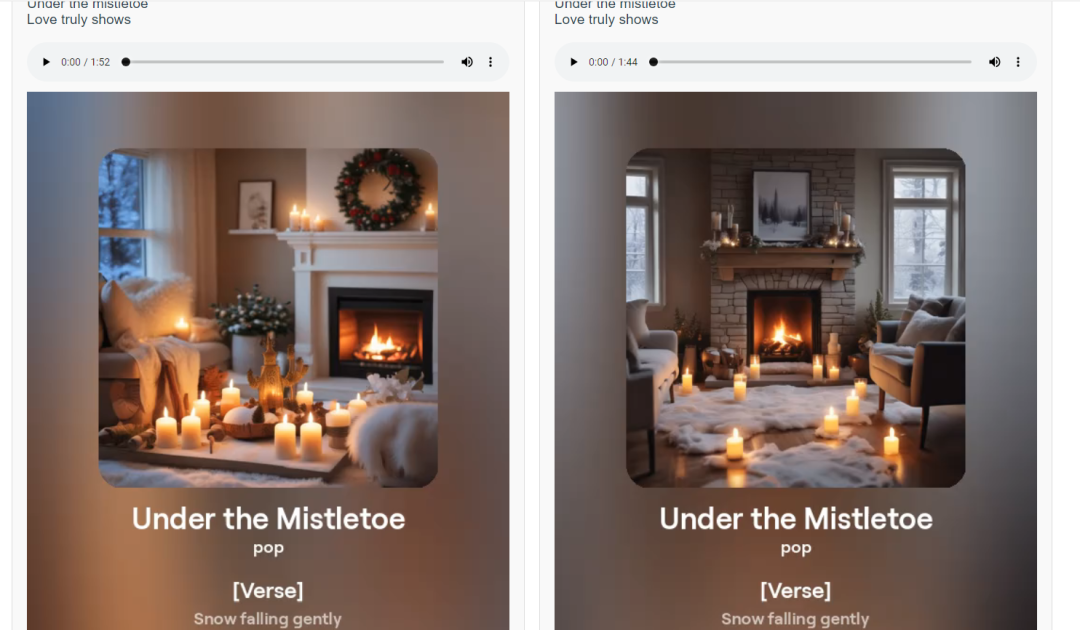
{ "success": true, "data": [ { "id": "2f16f7bc-4135-42c6-b3c5-6d6c49dc8cd5", "title": "Winter Wonderland", "image_url": "https://cdn1.suno.ai/image_2f16f7bc-4135-42c6-b3c5-6d6c49dc8cd5.png", "lyric": "[Verse]\nSnowflakes falling all around\nGlistening white\nCovering the ground\nChildren laughing\nFull of delight\nIn this winter wonderland tonight\nSanta's sleigh\nUp in the sky\nRudolph's nose shining bright\nOh my\nHear the jingle bells\nRinging so clear\nBringing joy and holiday cheer\n[Verse 2]\nRoasting chestnuts by the fire's glow\nChristmas lights\nThey twinkle and show\nFamilies gathering with love and cheer\nSpreading warmth to everyone near", "audio_url": "https://cdn1.suno.ai/2f16f7bc-4135-42c6-b3c5-6d6c49dc8cd5.mp3", "video_url": "https://cdn1.suno.ai/2f16f7bc-4135-42c6-b3c5-6d6c49dc8cd5.mp4", "created_at": "2024-05-10T16:21:37.624Z", "model": "chirp-v3", "prompt": "A song for Christmas", "style": "holiday" }, { "id": "5dca232b-17cc-4896-a2d1-4b59178bf410", "title": "Winter Wonderland", "image_url": "https://cdn1.suno.ai/image_5dca232b-17cc-4896-a2d1-4b59178bf410.png", "lyric": "[Verse]\nSnowflakes falling all around\nGlistening white\nCovering the ground\nChildren laughing\nFull of delight\nIn this winter wonderland tonight\nSanta's sleigh\nUp in the sky\nRudolph's nose shining bright\nOh my\nHear the jingle bells\nRinging so clear\nBringing joy and holiday cheer\n[Verse 2]\nRoasting chestnuts by the fire's glow\nChristmas lights\nThey twinkle and show\nFamilies gathering with love and cheer\nSpreading warmth to everyone near", "audio_url": "https://cdn1.suno.ai/5dca232b-17cc-4896-a2d1-4b59178bf410.mp3", "video_url": "https://cdn1.suno.ai/5dca232b-17cc-4896-a2d1-4b59178bf410.mp4", "created_at": "2024-05-10T16:21:37.624Z", "model": "chirp-v3", "prompt": "A song for Christmas", "style": "holiday" } ] }
可以看到这时候我们就得到了两首歌的内容,包括标题、预览图、歌词、音频、视频等内容。
字段说明如下:
success:生成是否成功,如果成功则为 true,否则为 false
data:是一个列表,包含了生成的歌曲的详细信息。
id:歌曲 ID
title:歌曲的标题
image_url:歌曲的封面图片
lyric:歌曲的歌词
audio_url:歌曲的音频文件,打开就是一个 mp3 音频。
video_url:歌曲的视频文件,打开就是一个 mp4 视频。
created_at:创建的时间
model:使用的模型,一般是最新的 v3 模型
style:风格
自定义生成
如果想自定义生成歌词,可以输入歌词:
这时候 lyric 字段可以传入类似如下内容:
1
[Verse]\nSnowflakes falling all around\nGlistening white\nCovering the ground\nChildren laughing\nFull of delight\nIn this winter wonderland tonight\nSanta's sleigh\nUp in the sky\nRudolph's nose shining bright\nOh my\nHear the jingle bells\nRinging so clear\nBringing joy and holiday cheer\n[Verse 2]\nRoasting chestnuts by the fire's glow\nChristmas lights\nThey twinkle and show\nFamilies gathering with love and cheer\nSpreading warmth to everyone near
注意,这里的歌词中 \n 是换行符,如果你不知道如何生成歌词,可以使用下文介绍的生成歌词的 API 自助生成。
curl -X POST 'https://api.acedata.cloud/suno/audios' \ -H 'authorization: Bearer {token}' \ -H 'accept: application/json' \ -H 'content-type: application/json' \ -d '{ "lyric": "[Verse]\\nSnowflakes falling all around\\nGlistening white\\nCovering the ground\\nChildren laughing\\nFull of delight\\nIn this winter wonderland tonight\\nSanta's sleigh\\nUp in the sky\\nRudolph's nose shining bright\\nOh my\\nHear the jingle bells\\nRinging so clear\\nBringing joy and holiday cheer\\n[Verse 2]\\nRoasting chestnuts by the fire's glow\\nChristmas lights\\nThey twinkle and show\\nFamilies gathering with love and cheer\\nSpreading warmth to everyone near", "custom": true }'
测试允许,生成的效果是类似的。
异步回调
由于 Suno 生成音乐的时间相对较长,大约需要 1-2 分钟,如果 API 长时间无响应,HTTP 请求会一直保持连接,导致额外的系统资源消耗,所以本 API 也提供了异步回调的支持。
整体流程是:客户端发起请求的时候,额外指定一个 callback_url 字段,客户端发起 API 请求之后,API 会立马返回一个结果,包含一个 task_id 的字段信息,代表当前的任务 ID。当任务完成之后,生成音乐的结果会通过 POST JSON 的形式发送到客户端指定的 callback_url,其中也包括了 task_id 字段,这样任务结果就可以通过 ID 关联起来了。
{ "success": true, "task_id": "44472ab8-783b-4054-b861-5bf14e462f60", "data": [ { "id": "da4324e5-84b2-484b-b0e9-dd261381c594", "title": "Winter Whispers", "image_url": "https://cdn1.suno.ai/image_da4324e5-84b2-484b-b0e9-dd261381c594.png", "lyric": "[Verse]\nSnow falling gently from the sky\nChildren giggling as they pass by\nFire crackling\nCozy and warm\nChristmas spirit begins to swarm\n[Verse 2]\nTwinkling lights\nA sight to behold\nStockings hung\nWaiting to be filled with gold\nGifts wrapped with love\nPiled high\nExcitement in the air\nYou can't deny\n[Chorus]\nWinter whispers in the wind\nJoy and love it brings\nLet's celebrate this season\nWith the ones we're missing", "audio_url": "https://cdn1.suno.ai/da4324e5-84b2-484b-b0e9-dd261381c594.mp3", "video_url": "https://cdn1.suno.ai/da4324e5-84b2-484b-b0e9-dd261381c594.mp4", "created_at": "2024-05-11T07:33:05.430Z", "model": "chirp-v3", "prompt": "A song for Christmas", "style": "pop" }, { "id": "b878a87b-a0db-4046-8ccd-ecd2fb3d4372", "title": "Winter Whispers", "image_url": "https://cdn1.suno.ai/image_b878a87b-a0db-4046-8ccd-ecd2fb3d4372.png", "lyric": "[Verse]\nSnow falling gently from the sky\nChildren giggling as they pass by\nFire crackling\nCozy and warm\nChristmas spirit begins to swarm\n[Verse 2]\nTwinkling lights\nA sight to behold\nStockings hung\nWaiting to be filled with gold\nGifts wrapped with love\nPiled high\nExcitement in the air\nYou can't deny\n[Chorus]\nWinter whispers in the wind\nJoy and love it brings\nLet's celebrate this season\nWith the ones we're missing", "audio_url": "https://cdn1.suno.ai/b878a87b-a0db-4046-8ccd-ecd2fb3d4372.mp3", "video_url": "https://cdn1.suno.ai/b878a87b-a0db-4046-8ccd-ecd2fb3d4372.mp4", "created_at": "2024-05-11T07:33:05.430Z", "model": "chirp-v3", "prompt": "A song for Christmas", "style": "pop" } ] }
{ "success": true, "task_id": "57e8ce3a-39cb-41a2-802f-e70a324f4d0a", "data": { "text": "[Verse]\nSnowflakes falling from the sky\nWinter's cold touch\nOh how it gets me high\nI bundle up in layers\nOh so cozy\nStepping out and feeling the frost on my nose\nSee\n\n[Verse 2]\nThe world is covered in a blanket of white\nIcicles hanging\nShimmering so bright\nThe chilly air fills my lungs with every breath\nWalking in the snow\nLeaving footprints that won't be left\n\n[Chorus]\nOh\nWinter's cold touch\nIt's a season that I love so much\nSnowfall brings a feeling so divine\nWinter's cold touch\nIt's a magical time", "title": "Winter's Cold Touch", "status": "complete" } }
{ "answer": "I am an AI language model developed by OpenAI and I don't have a personal name. However, you can call me GPT or simply Chatbot. How can I assist you today?" }
{ "answer": "I am an AI language model created by OpenAI and I don't have a personal name. You can simply call me OpenAI or ChatGPT. How can I assist you today?", "id": "7cdb293b-2267-4979-a1ec-48d9ad149916" }
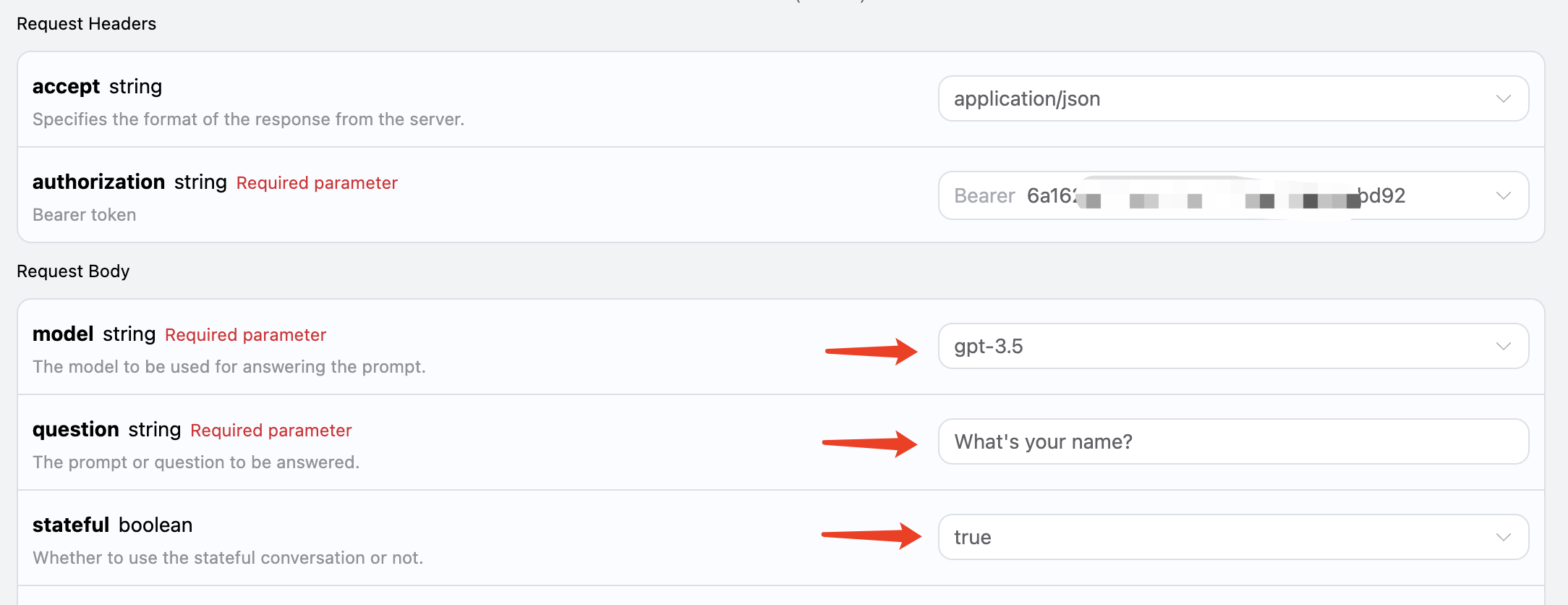
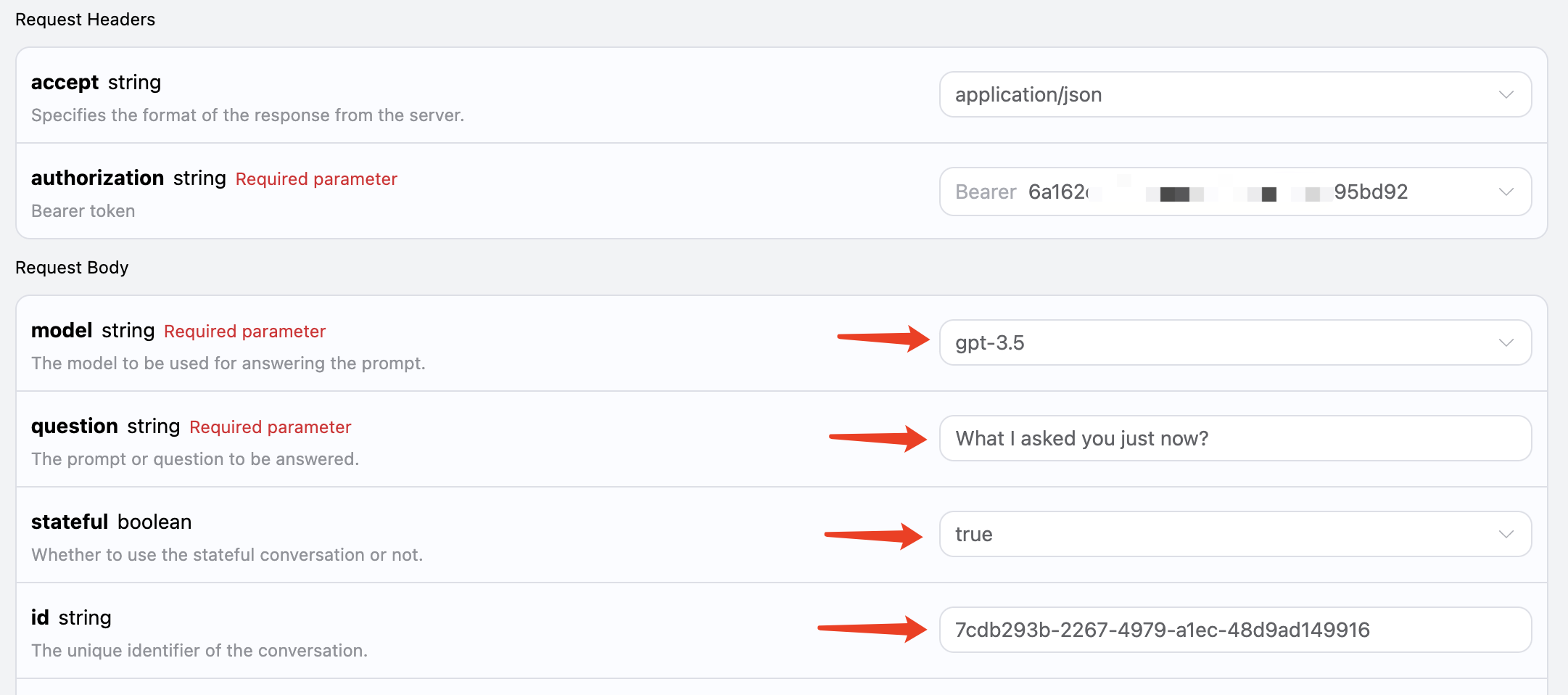
第二次请求,将第一次请求返回的 id 字段作为参数传递,同时 stateful 参数依然设置为 true,询问「What I asked you just now?」,如图所示:
对应代码如下:
1 2 3 4 5 6 7 8 9 10
curl -X POST 'https://api.acedata.cloud/aichat/conversations' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "model": "gpt-3.5", "stateful": true, "id": "7cdb293b-2267-4979-a1ec-48d9ad149916", "question": "What I asked you just now?" }'
结果如下:
1 2 3 4
{ "answer": "You asked me what my name is. As an AI language model, I do not possess a personal identity, so I don't have a specific name. However, you can refer to me as OpenAI or ChatGPT, the names used for this AI model. Is there anything else I can help you with?", "id": "7cdb293b-2267-4979-a1ec-48d9ad149916" }
@Override publicvoidonResponse(Call call, Response response)throws IOException { if (!response.isSuccessful()) thrownew IOException("Unexpected code " + response); try (BufferedReader br = new BufferedReader( new InputStreamReader(response.body().byteStream(), "UTF-8"))) { String responseLine; while ((responseLine = br.readLine()) != null) { System.out.println(responseLine); } } } });
其他语言可以另外自行改写,原理都是一样的。
模型预设
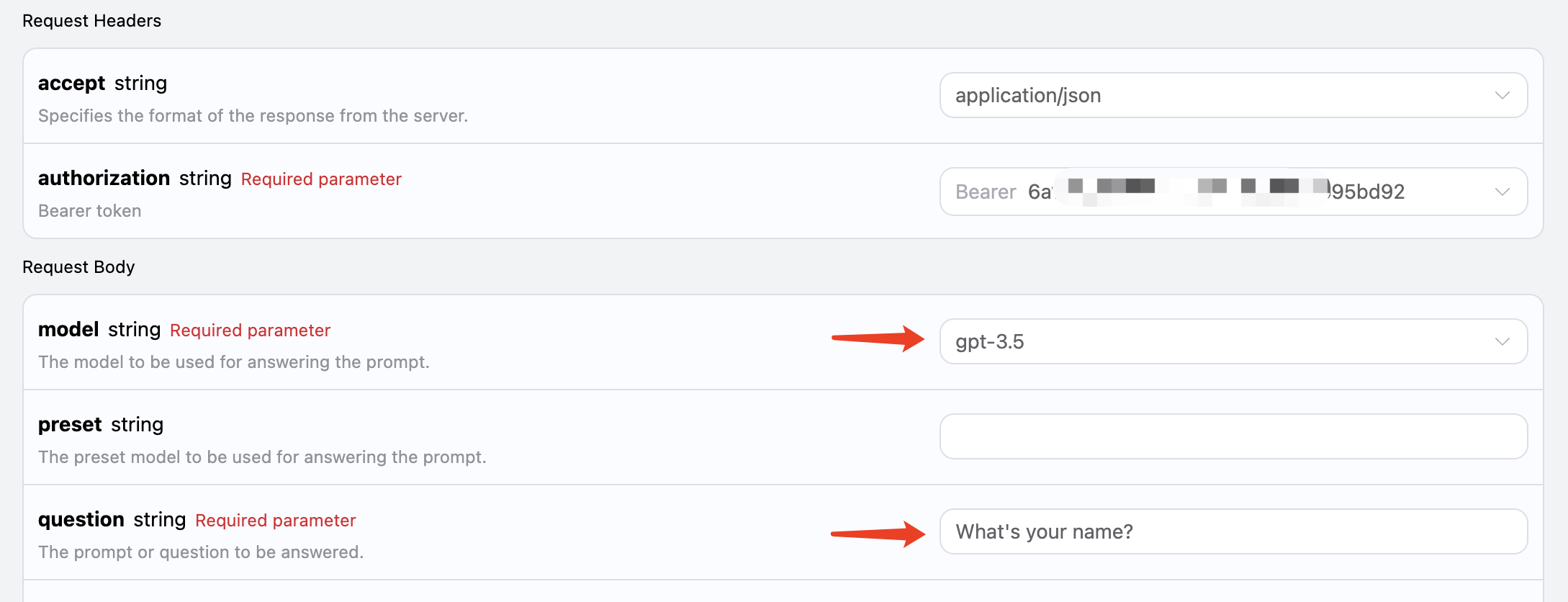
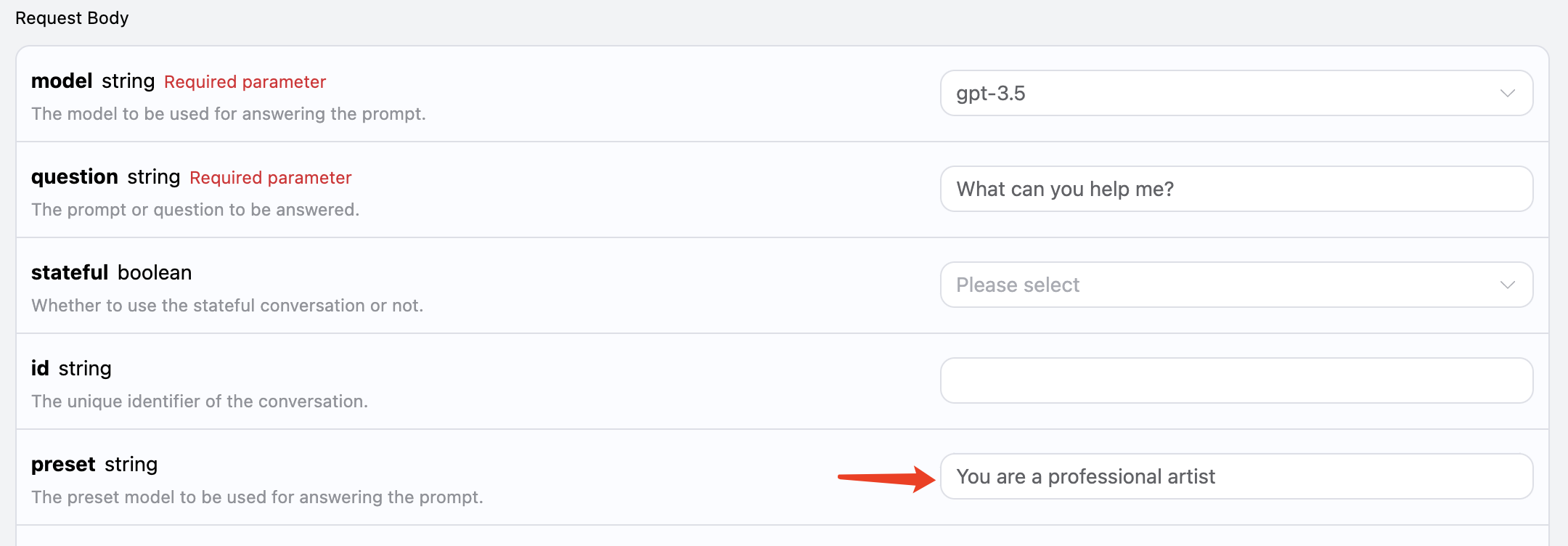
我们知道,OpenAI 相关的 API 有对应的 system_prompt 的概念,就是给整个模型设置一个预设,比如它叫什么名字等等。本 AI 问答 API 也暴露了这个参数,叫做 preset,利用它我们可以给模型增加预设,我们用一个例子来体验下:
这里我们额外添加 preset 字段,内容为 You are a professional artist,如图所示:
对应代码如下:
1 2 3 4 5 6 7 8 9 10
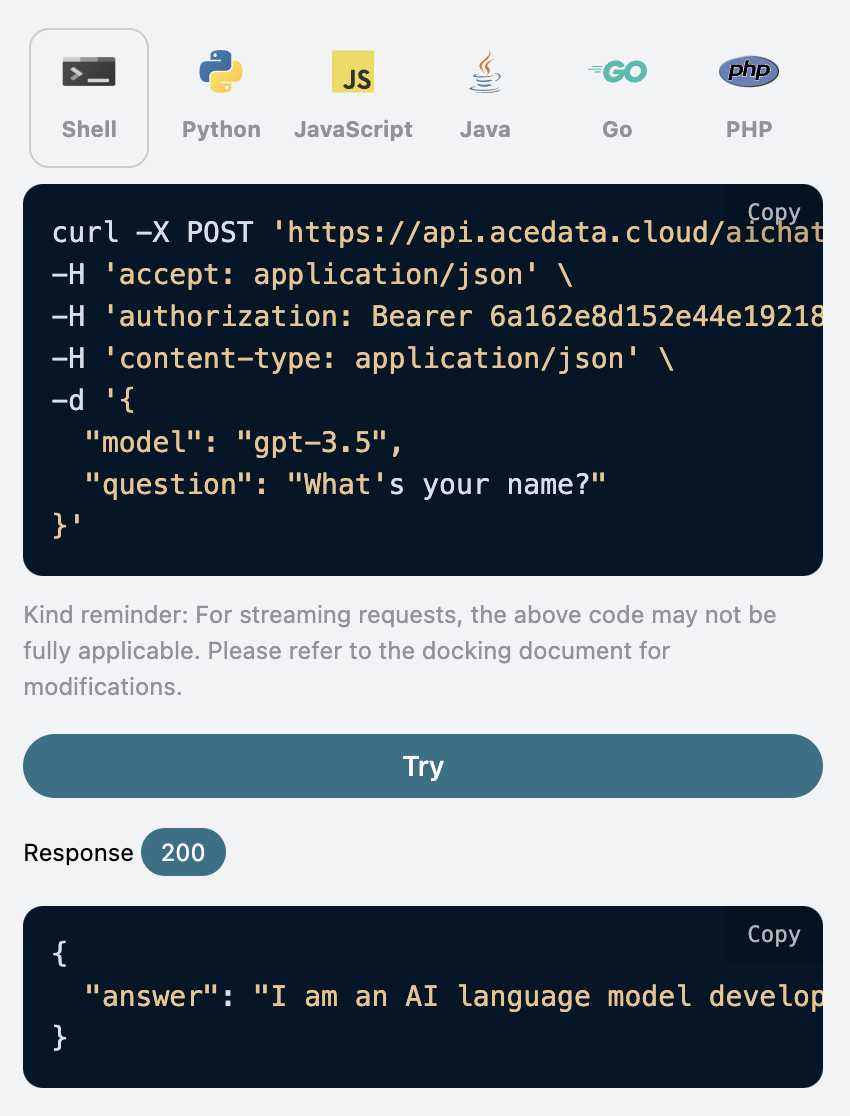
curl -X POST 'https://api.acedata.cloud/aichat/conversations' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "model": "gpt-3.5", "stateful": true, "question": "What can you help me?", "preset": "You are a professional artist" }'
运行结果如下:
1 2 3
{ "answer": "As a professional artist, I can offer a range of services and assistance depending on your specific needs. Here are a few ways I can help you:\n\n1. Custom Artwork: If you have a specific vision or idea, I can create custom artwork for you. This can include paintings, drawings, digital art, or any other medium you prefer.\n\n2. Commissioned Pieces: If you have a specific subject or concept in mind, I can create commissioned art pieces tailored to your preferences. This could be for personal enjoyment or as a unique gift for someone special.\n\n3. Art Consultation: If you need guidance on art selection, interior design, or how to showcase and display art in your space, I can provide professional advice to help enhance your aesthetic sense and create a cohesive look." }
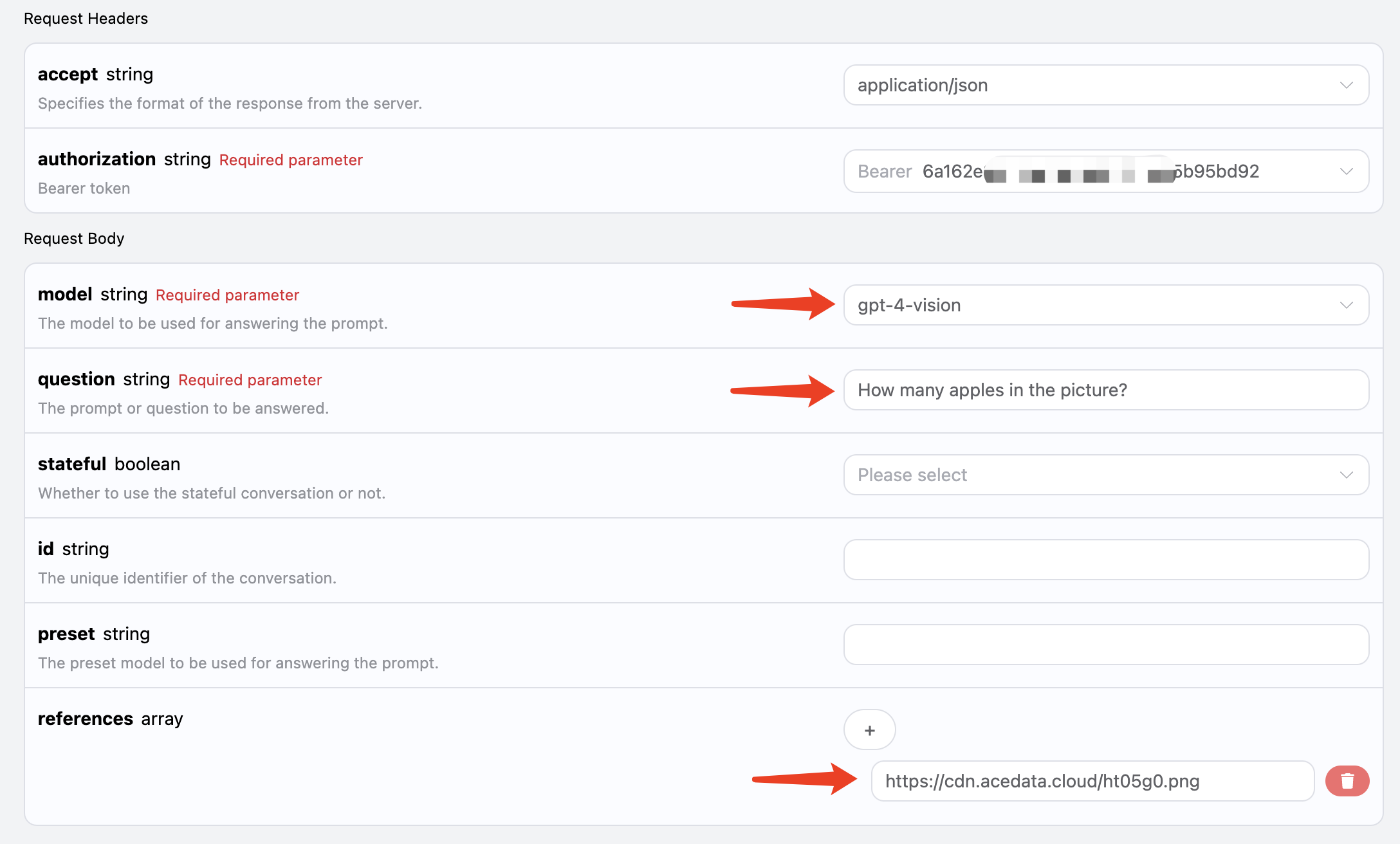
curl -X POST 'https://api.acedata.cloud/aichat/conversations' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "model": "gpt-4-vision", "question": "How many apples in the picture?", "references": ["https://cdn.acedata.cloud/ht05g0.png"] }'
运行结果如下:
1 2 3
{ "answer": "There are 5 apples in the picture." }
可以看到,我们就成功得到了对应图片的回答结果。
联网问答
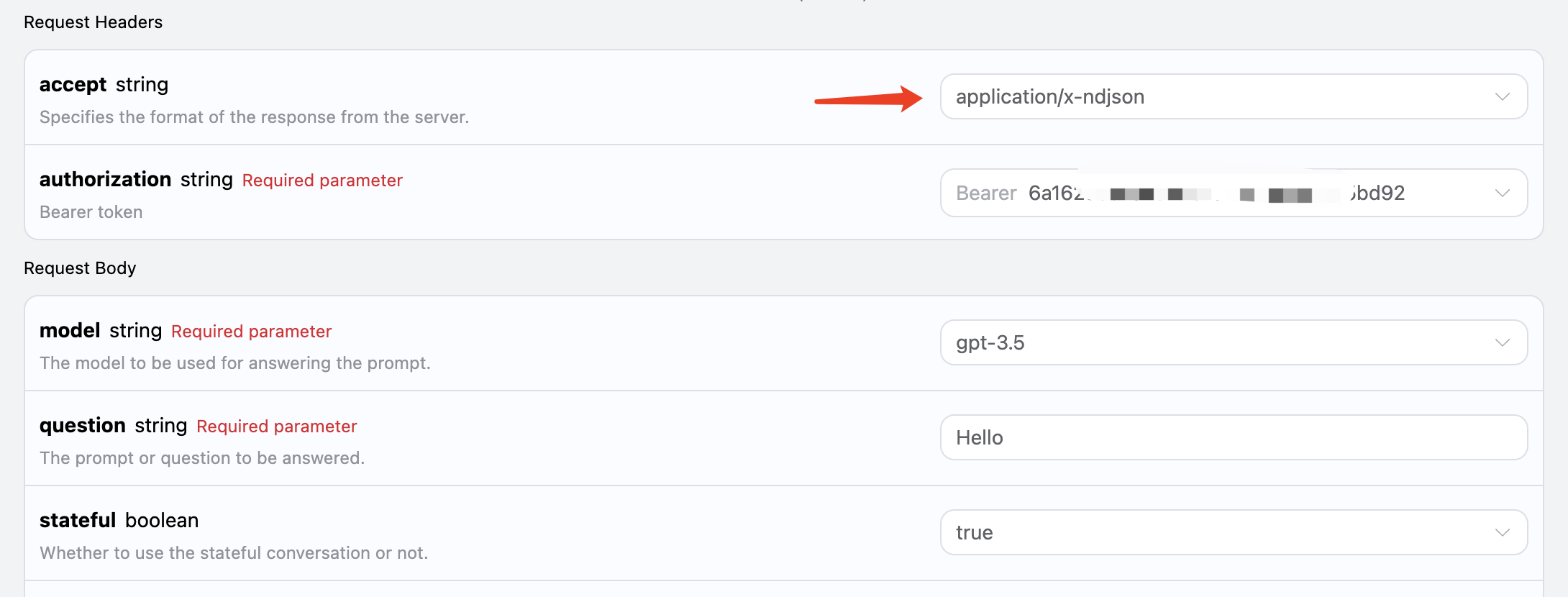
本 API 还支持联网模型,包括 GPT-3.5、GPT-4 均能支持,在 API 背后有一个自动搜索互联网并总结的过程,我们可以选择模型为 gpt-3.5-browsing 来体验下,如图所示:
代码如下:
1 2 3 4 5 6 7 8
curl -X POST 'https://api.acedata.cloud/aichat/conversations' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "model": "gpt-3.5-browsing", "question": "What's the weather of New York today?" }'
运行结果如下:
1 2 3
{ "answer": "The weather in New York today is as follows:\n- Current Temperature: 16°C (60°F)\n- High: 16°C (60°F)\n- Low: 10°C (50°F)\n- Humidity: 47%\n- UV Index: 6 of 11\n- Sunrise: 5:42 am\n- Sunset: 8:02 pm\n\nIt's overcast with a chance of occasional showers overnight, and the chance of rain is 50%.\nFor more details, you can visit [The Weather Channel](https://weather.com/weather/tenday/l/96f2f84af9a5f5d452eb0574d4e4d8a840c71b05e22264ebdc0056433a642c84).\n\nIs there anything else you'd like to know?" }
可以看到,这里它自动联网搜索了 The Weather Channel 网站,并获得了里面的信息,然后进一步返回了实时结果。
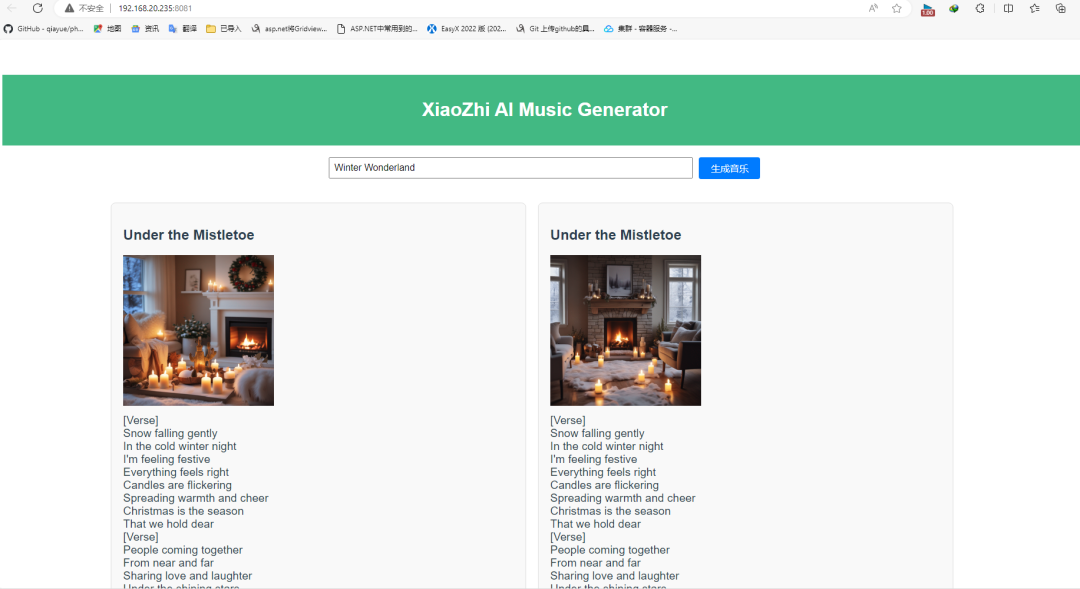
在这个数字化时代,人工智能技术正以惊人的速度改变着我们的生活方式和创造方式。音乐作为一种最直接、最感性的艺术形式,自然也成为了人工智能技术的应用场景之一。今天,我们将以 Vue 和 Node.js 为基础,利用现有的 API 来快速搭建一个 Suno AI 音乐站点。让我们一起探索这个令人兴奋的过程吧!
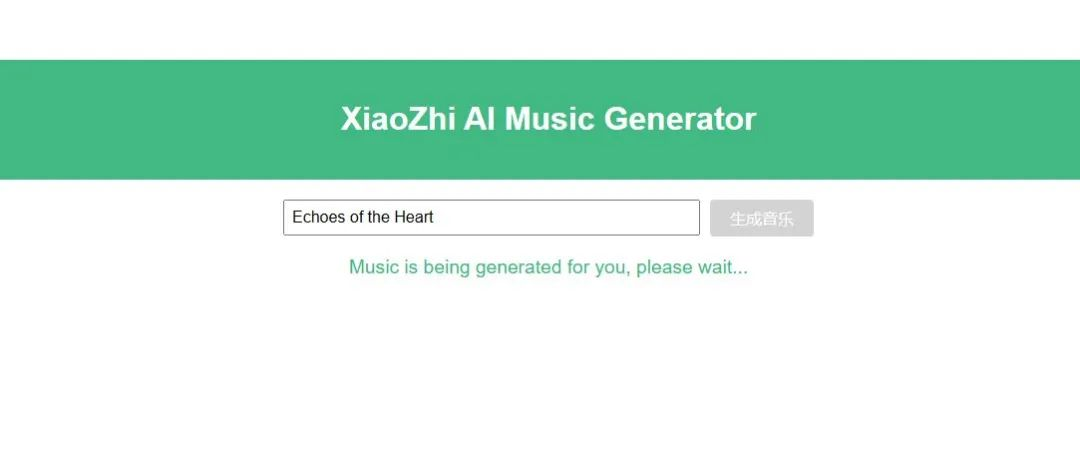
<template> <divid="app"> <header> <h1>XiaoZhi AI Music Generator</h1> </header> <main> <divclass="input-container"> <inputtype="text"v-model="musicTitle"placeholder="Enter a prompt for the music"> <button @click="handleGenerateMusic":disabled="loading">生成音乐</button> </div> <divv-if="loading"class="loading"> Music is being generated for you, please wait... </div>
<divv-if="musicGenerated"class="music-container"> <divv-for="music in generatedMusic":key="music.id"class="music-item"> <h2>{{ music.title }}</h2> <img:src="music.image_url"alt="Music Image"> <pclass="lyric">{{ music.lyric }}</p> <audiocontrolsclass="audio" @play="stopOtherMedia($event)"> <source:src="music.audio_url"type="audio/mpeg"> Your browser does not support the audio element. </audio> <videocontrolsclass="video" @play="stopOtherMedia($event)"> <source:src="music.video_url"type="video/mp4"> Your browser does not support the video element. </video> </div> </div>
我们还可以通过 position 参数控制二维码的位置,比如说一张图片里面有一个女生穿裙子,而我们想要把二维码放在裙子的位置并与之融合起来,我们就可以尝试改下二维码的位置,调用样例如下:
1 2 3 4 5 6 7 8 9
curl -X POST "https://api.zhishuyun.com/qrart/generate?token={token}" \ -H "accept: application/json" \ -H "content-type: application/json" \ -d '{ "type": "link", "content": "https://data.zhishuyun.com", "prompt": "one of the beautiful girls in the moonlight in the background, in the style of pixelated chaos, rococo-inspired art, dark white and sky-blue, made of plastic, delicate flowers, gongbi, wimmelbilder", "position": "bottom" }'
官方介绍这家的代理 IP 数量大约是九千万左右,这个数量非常庞大,同时官方介绍说代理的可用率是 99.9%。
下面我们来看一下他们的一些套餐类型:
动态住宅代理:这种代理实际上就是用真实的住宅用户的 IP 搭建的代理。一般来说,住宅代理对于很多场景的使用封禁概率会比较低,因为很多厂商对封禁住宅代理是比较谨慎的。动态住宅代理其实就是可以定时切换的 IP,比如说做网络爬虫,我们就需要不断变换的不同的代理 IP,这样可以进一步的减少被封禁的概率。
静态住宅代理:相对于动态代理来说,静态住宅代理的特点就是长效稳定,可以一直获取一个稳定不变的代理 IP,适合长久的稳定的海外网络环境使用。比如说,我们要进行自动化网站的爬取,如果在一个页面内 IP 地址频繁变动会增大被风控的概率。所以,如果有一个长效稳定的住宅 IP 代理,就会非常方便。
数据中心代理:这种代理实际上是很多服务器厂商的服务器搭建起来的代理。例如腾讯云、阿里云、微软云等服务器所在的 IP 地址段,就属于所谓的数据中心的 IP 地址段。因此,用这些服务器搭建出来的代理就叫做数据中心代理。一般来说,这种数据中心代理相对于住宅代理更容易被爬虫封禁,但是这种代理的优势就是价格更加便宜,而且网络速度也会相对较好。
I want you to act as a javascript console. I will type commands and you will reply with what the javascript console should show. I want you to only reply with the terminal output inside one unique code block, and nothing else. do not write explanations. do not type commands unless I instruct you to do so. when i need to tell you something in english, i will do so by putting text inside curly brackets {like this}. my first command is console.log(“Hello World”);
import time from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.remote.webelement import WebElement from selenium.webdriver.common.action_chains import ActionChains from app.captcha_resolver import CaptchaResolver
# click captchas recognized_indices = [i for i, x in enumerate(recognized_results) if x] logger.debug(f'recognized_indices {recognized_indices}') click_targets = self.wait.until(EC.visibility_of_all_elements_located( (By.CSS_SELECTOR, '.task-image'))) for recognized_index in recognized_indices: click_target: WebElement = click_targets[recognized_index] click_target.click() time.sleep(random())
当然我们也可以通过执行 JavaScript 来对每个节点进行模拟点击,效果是类似的。
这里我们用 for 循环将 true false 列表转成了一个列表,列表的每个元素代表 true 在列表中的位置,其实就是我们的点击目标了。
然后接着我们获取了所有的验证码小图对应的节点,然后依次调用 click 方法进行点击即可。
这样我们就可以实现验证码小图的逐个识别了。
点击验证
好,那么有了上面的逻辑,我们就能完成整个 HCaptcha 的识别和点选了。
最后,我们模拟点击验证按钮就好了:
1 2 3 4 5
# after all captcha clicked verify_button: WebElement = self.get_verify_button() if verify_button.is_displayed: verify_button.click() time.sleep(3)
import time from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.remote.webelement import WebElement from selenium.webdriver.common.action_chains import ActionChains from app.captcha_resolver import CaptchaResolver
defget_question_id_by_target_name(target_name): logger.debug(f'try to get question id by {target_name}') question_id = CAPTCHA_TARGET_NAME_QUESTION_ID_MAPPING.get(target_name) logger.debug(f'question_id {question_id}') return question_id
single_captcha_elements = self.wait.until(EC.visibility_of_all_elements_located( (By.CSS_SELECTOR, '#rc-imageselect-target table td'))) for recognized_index in recognized_indices: single_captcha_element: WebElement = single_captcha_elements[recognized_index] single_captcha_element.click() # check if need verify single captcha self.verify_single_captcha(recognized_index)
defverify_single_captcha(self, index): time.sleep(3) elements = self.wait.until(EC.visibility_of_all_elements_located( (By.CSS_SELECTOR, '#rc-imageselect-target table td'))) single_captcha_element: WebElement = elements[index] class_name = single_captcha_element.get_attribute('class') logger.debug(f'verifiying single captcha {index}, class {class_name}') if'selected'in class_name: logger.debug(f'no new single captcha displayed') return logger.debug('new single captcha displayed') single_captcha_url = single_captcha_element.find_element_by_css_selector( 'img').get_attribute('src') logger.debug(f'single_captcha_url {single_captcha_url}') with open(CAPTCHA_SINGLE_IMAGE_FILE_PATH, 'wb') as f: f.write(requests.get(single_captcha_url).content) resized_single_captcha_base64_string = resize_base64_image( CAPTCHA_SINGLE_IMAGE_FILE_PATH, (100, 100)) single_captcha_recognize_result = self.captcha_resolver.create_task( resized_single_captcha_base64_string, get_question_id_by_target_name(self.captcha_target_name)) ifnot single_captcha_recognize_result: logger.error('count not get single captcha recognize result') return has_object = single_captcha_recognize_result.get( 'solution', {}).get('hasObject') if has_object isNone: logger.error('count not get captcha recognized indices') return if has_object isFalse: logger.debug('no more object in this single captcha') return if has_object: single_captcha_element.click() # check for new single captcha self.verify_single_captcha(index)
OK,这里我们定义了一个 verify_single_captcha 方法,然后传入了格子对应的序号。接着我们首先尝试查找格子对应的节点,然后找出对应的 HTML 的 class 属性。如果没有出现新的小图,那就是这样的选中状态,对应的 class 就包含了 selected 字样,如图所示:
比如说,我们有两台主机 A、B,我们最终想实现在 A 上控制 B。那么如果用正向 Shell,其实就是在 A 上输入 B 的连接地址,比如通过 ssh 连接到 B,连接成功之后,我们就可以在 A 上通过命令控制 B 了。如果用反向 Shell,那就是在 A 上先开启一个监听端口,然后让 B 去连接 A 的这个端口,连接成功之后,A 这边就能通过命令控制 B 了。
反弹 Shell 有什么用?
还是原来的例子,我们想用 A 来控制 B,如果想用 ssh 等命令来控制,那得输入 B 的 sshd 地址或者端口对吧?但是在很多情况下,由于防火墙、安全组、局域网、NAT 等原因,我们实际上是无法直接连接到 B 的,比如:
网页是运行在浏览器端的,当我们浏览一个网页时,其 HTML 代码、 JavaScript 代码都会被下载到浏览器中执行。借助浏览器的开发者工具,我们可以看到网页在加载过程中所有网络请求的详细信息,也能清楚地看到网站运行的 HTML 代码和 JavaScript 代码,这些代码中就包含了网站加载的全部逻辑,如加载哪些资源、请求接口是如何构造的、页面是如何渲染的等等。正因为代码是完全透明的,所以如果我们能够把其中的执行逻辑研究出来,就可以模拟各个网络请求进行数据爬取了。
网站运营者首先想到防护措施可能是对某些数据接口的参数进行加密,比如说对某些 URL 的一些参数加上校验码或者把一些 id 信息进行编码,使其变得难以阅读或构造;或者对某些 API 请求加上一些 token、sign 等签名,这样这些请求发送到服务器时,服务器会通过客户端发来的一些请求信息以及双方约定好的秘钥等来对当前的请求进行校验,如果校验通过,才返回对应数据结果。
var a = ["hello"]; (function (c, d) { var e = function (f) { while (--f) { c["push"](c["shift"]()); } }; e(++d); })(a, 0x9b); var b = function (c, d) { c = c - 0x0; var e = a[c]; return e; }; let hello = "1" + 0x1; console["log"](b("0x0"), hello);
在一些付费代理套餐中,大家可能会注意到有这样的一个套餐 - 独享代理或私密代理,这种其实就是用了专用服务器搭建了代理服务,相对一般的付费代理来说,其稳定性更好,速度也更快,同时 IP 可以动态变化。这种独享代理或私密代理的 IP 切换大多数都是基于 ADSL 拨号机制来实现的,一台云主机每拨号一次就可以换一个 IP,同时云主机上搭建了代理服务,我们就可以直接使用该云主机的 HTTP 代理来进行数据爬取了。
本节我们就来实际操作一下搭建 ADSL 拨号代理服务的方法。
1. 什么是 ADSL
ADSL,英文全称是 Asymmetric Digital Subscriber Line,即非对称数字用户环路。它的上行和下行带宽不对称,它采用频分复用技术把普通的电话线分成了电话、上行和下行 3 个相对独立的信道,从而避免了相互之间的干扰。
ADSL 通过拨号的方式上网,拨号时需要输入 ADSL 账号和密码,每次拨号就更换一个 IP。IP 分布在多个 A 段,如果 IP 都能使用,则意味着 IP 量级可达千万。如果我们将 ADSL 主机作为代理,每隔一段时间云主机拨号就换一个 IP,这样可以有效防止 IP 被封禁。另外,由于我们是直接使用专有的云主机搭建的代理服务,所以其代理的稳定性相对更好,代理响应速度也相对更快。
接口模块:需要用 API 来提供对外服务的接口。其实我们可以直接连接数据库来取对应的数据,但是这样就需要知道数据库的连接信息,并且要配置连接,而比较安全和方便的方式就是提供一个 Web API 接口,我们通过访问接口即可拿到可用代理。另外,由于可用代理可能有多个,所以我们可以设置一个随机返回某个可用代理的接口,这样就能保证每个可用代理都可以取到,实现负载均衡。
import redis from proxypool.exceptions import PoolEmptyException from proxypool.schemas.proxy import Proxy from proxypool.setting import REDIS_HOST, REDIS_PORT, REDIS_PASSWORD, REDIS_KEY, PROXY_SCORE_MAX, PROXY_SCORE_MIN, \ PROXY_SCORE_INIT from random import choice from typing import List from loguru import logger from proxypool.utils.proxy import is_valid_proxy, convert_proxy_or_proxies
defadd(self, proxy: Proxy, score=PROXY_SCORE_INIT) -> int: """ add proxy and set it to init score :param proxy: proxy, ip:port, like 8.8.8.8:88 :param score: int score :return: result """ ifnot is_valid_proxy(f'{proxy.host}:{proxy.port}'): logger.info(f'invalid proxy {proxy}, throw it') return ifnot self.exists(proxy): if IS_REDIS_VERSION_2: return self.db.zadd(REDIS_KEY, score, proxy.string()) return self.db.zadd(REDIS_KEY, {proxy.string(): score})
defrandom(self) -> Proxy: """ get random proxy firstly try to get proxy with max score if not exists, try to get proxy by rank if not exists, raise error :return: proxy, like 8.8.8.8:8 """ # try to get proxy with max score proxies = self.db.zrangebyscore(REDIS_KEY, PROXY_SCORE_MAX, PROXY_SCORE_MAX) if len(proxies): return convert_proxy_or_proxies(choice(proxies)) # else get proxy by rank proxies = self.db.zrevrange(REDIS_KEY, PROXY_SCORE_MIN, PROXY_SCORE_MAX) if len(proxies): return convert_proxy_or_proxies(choice(proxies)) # else raise error raise PoolEmptyException
defdecrease(self, proxy: Proxy) -> int: """ decrease score of proxy, if small than PROXY_SCORE_MIN, delete it :param proxy: proxy :return: new score """ score = self.db.zscore(REDIS_KEY, proxy.string()) # current score is larger than PROXY_SCORE_MIN if score and score > PROXY_SCORE_MIN: logger.info(f'{proxy.string()} current score {score}, decrease 1') if IS_REDIS_VERSION_2: return self.db.zincrby(REDIS_KEY, proxy.string(), -1) return self.db.zincrby(REDIS_KEY, -1, proxy.string()) # otherwise delete proxy else: logger.info(f'{proxy.string()} current score {score}, remove') return self.db.zrem(REDIS_KEY, proxy.string())
defmax(self, proxy: Proxy) -> int: """ set proxy to max score :param proxy: proxy :return: new score """ logger.info(f'{proxy.string()} is valid, set to {PROXY_SCORE_MAX}') if IS_REDIS_VERSION_2: return self.db.zadd(REDIS_KEY, PROXY_SCORE_MAX, proxy.string()) return self.db.zadd(REDIS_KEY, {proxy.string(): PROXY_SCORE_MAX})
defcount(self) -> int: """ get count of proxies :return: count, int """ return self.db.zcard(REDIS_KEY)
defall(self) -> List[Proxy]: """ get all proxies :return: list of proxies """ return convert_proxy_or_proxies(self.db.zrangebyscore(REDIS_KEY, PROXY_SCORE_MIN, PROXY_SCORE_MAX))
defbatch(self, start, end) -> List[Proxy]: """ get batch of proxies :param start: start index :param end: end index :return: list of proxies """ return convert_proxy_or_proxies(self.db.zrevrange(REDIS_KEY, start, end - 1))
if __name__ == '__main__': conn = RedisClient() result = conn.random() print(result)
from retrying import retry import requests from loguru import logger
classBaseCrawler(object): urls = []
@retry(stop_max_attempt_number=3, retry_on_result=lambda x: x is None) deffetch(self, url, **kwargs): try: response = requests.get(url, **kwargs) if response.status_code == 200: return response.text except requests.ConnectionError: return
@logger.catch defcrawl(self): """ crawl main method """ for url in self.urls: logger.info(f'fetching {url}') html = self.fetch(url) for proxy in self.parse(html): logger.info(f'fetched proxy {proxy.string()} from {url}') yield proxy
import pkgutil from .base import BaseCrawler import inspect
# load classes subclass of BaseCrawler classes = [] for loader, name, is_pkg in pkgutil.walk_packages(__path__): module = loader.find_module(name).load_module(name) for name, value in inspect.getmembers(module): globals()[name] = value if inspect.isclass(value) and issubclass(value, BaseCrawler) and value isnot BaseCrawler: classes.append(value) __all__ = __ALL__ = classes
asyncdeftest(self, proxy: Proxy): """ test single proxy :param proxy: Proxy object :return: """ asyncwith aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False)) as session: try: logger.debug(f'testing {proxy.string()}') asyncwith session.get(TEST_URL, proxy=f'http://{proxy.string()}', timeout=TEST_TIMEOUT, allow_redirects=False) as response: if response.status in TEST_VALID_STATUS: self.redis.max(proxy) logger.debug(f'proxy {proxy.string()} is valid, set max score') else: self.redis.decrease(proxy) logger.debug(f'proxy {proxy.string()} is invalid, decrease score') except EXCEPTIONS: self.redis.decrease(proxy) logger.debug(f'proxy {proxy.string()} is invalid, decrease score')
@logger.catch defrun(self): """ test main method :return: """ # event loop of aiohttp logger.info('stating tester...') count = self.redis.count() logger.debug(f'{count} proxies to test') for i in range(0, count, TEST_BATCH): # start end end offset start, end = i, min(i + TEST_BATCH, count) logger.debug(f'testing proxies from {start} to {end} indices') proxies = self.redis.batch(start, end) tasks = [self.test(proxy) for proxy in proxies] # run tasks using event loop self.loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__': tester = Tester() tester.run()
这里定义了一个类 Tester,__init__ 方法中建立了一个 RedisClient 对象,供该对象中其他方法使用。接下来,定义了一个 test 方法,这个方法用来检测单个代理的可用情况,其参数就是被检测的代理。注意,test 方法前面加了 async 关键词,这代表这个方法是异步的。方法内部首先创建了 aiohttp 的 ClientSession 对象,可以直接调用该对象的 get 方法来访问页面。
测试链接在这里定义为常量 TEST_URL。如果针对某个网站有抓取需求,建议将 TEST_URL 设置为目标网站的地址,因为在抓取过程中,代理本身可能是可用的,但是该代理的 IP 已经被目标网站封掉了。例如,某些代理可以正常访问百度等页面,但是对知乎来说可能就被封了,所以我们可以将 TEST_URL 设置为知乎的某个页面的链接。当请求失败、代理被封时,分数自然会减下来,失效的代理就不会被取到了。
如果想做一个通用的代理池,则不需要专门设置 TEST_URL,既可以将其设置为一个不会封 IP 的网站,也可以设置为百度这类响应稳定的网站。
defrun_server(self): """ run server for api """ ifnot ENABLE_SERVER: logger.info('server not enabled, exit') return app.run(host=API_HOST, port=API_PORT, threaded=API_THREADED)
defrun(self): global tester_process, getter_process, server_process try: logger.info('starting proxypool...') if ENABLE_TESTER: tester_process = multiprocessing.Process(target=self.run_tester) logger.info(f'starting tester, pid {tester_process.pid}...') tester_process.start()
if ENABLE_GETTER: getter_process = multiprocessing.Process(target=self.run_getter) logger.info(f'starting getter, pid{getter_process.pid}...') getter_process.start()
if ENABLE_SERVER: server_process = multiprocessing.Process(target=self.run_server) logger.info(f'starting server, pid{server_process.pid}...') server_process.start()
tester_process.join() getter_process.join() server_process.join() except KeyboardInterrupt: logger.info('received keyboard interrupt signal') tester_process.terminate() getter_process.terminate() server_process.terminate() finally: # must call join method before calling is_alive tester_process.join() getter_process.join() server_process.join() logger.info(f'tester is {"alive"if tester_process.is_alive() else"dead"}') logger.info(f'getter is {"alive"if getter_process.is_alive() else"dead"}') logger.info(f'server is {"alive"if server_process.is_alive() else"dead"}') logger.info('proxy terminated')
if __name__ == '__main__': scheduler = Scheduler() scheduler.run()
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import WebDriverException import time from loguru import logger
COUNT = 1000
for i in range(1, COUNT + 1): try: browser = webdriver.Chrome() wait = WebDriverWait(browser, 10) browser.get('https://captcha1.scrape.center/') button = wait.until(EC.element_to_be_clickable( (By.CSS_SELECTOR, '.el-button'))) button.click() captcha = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '.geetest_slicebg.geetest_absolute'))) time.sleep(5) captcha.screenshot(f'data/captcha/images/captcha_{i}.png') except WebDriverException as e: logger.error(f'webdriver error occurred {e.msg}') finally: browser.close()
我们在做爬虫的过程中经常会遇到这样的情况,最初爬虫正常运行,正常抓取数据,一切看起来都是那么美好,然而一杯茶的功夫可能就会出现错误,比如 403 Forbidden,这时打开网页一看,可能会看到 “您的 IP 访问频率太高” 这样的提示。出现这种现象的原因是网站采取了一些反爬虫措施。比如,服务器会检测某个 IP 在单位时间内的请求次数,如果超过了这个阈值,就会直接拒绝服务,返回一些错误信息,这种情况可以称为封 IP。
既然服务器检测的是某个 IP 单位时间的请求次数,那么借助某种方式来伪装我们的 IP,让服务器识别不出是由我们本机发起的请求,不就可以成功防止封 IP 了吗?
一种有效的方式就是使用代理,后面会详细说明代理的用法。在这之前,需要先了解下代理的基本原理,它是怎样实现伪装 IP 的呢?
1. 基本原理
代理实际上指的就是代理服务器,英文叫作 Proxy Server,它的功能是代理网络用户去取得网络信息。形象地说,它是网络信息的中转站。在我们正常请求一个网站时,是发送了请求给 Web 服务器,Web 服务器把响应传回给我们。如果设置了代理服务器,实际上就是在本机和服务器之间搭建了一个桥,此时本机不是直接向 Web 服务器发起请求,而是向代理服务器发出请求,请求会发送给代理服务器,然后由代理服务器再发送给 Web 服务器,接着由代理服务器再把 Web 服务器返回的响应转发给本机。这样我们同样可以正常访问网页,但这个过程中 Web 服务器识别出的真实 IP 就不再是我们本机的 IP 了,就成功实现了 IP 伪装,这就是代理的基本原理。
由于验证码目标缺口通常具有比较明显的边缘,所以借助于一些边缘检测算法并通过调整阈值是可以找出它的位置的。目前应用比较广泛的边缘检测算法是 Canny,它是 John F. Canny 于 1986 年开发出来的一个多级边缘检测算法,效果还是不错的,OpenCV 也对此算法进行了实现,方法名称就叫做 Canny,声明如下:
OCR,即 Optical Character Recognition,中文翻译叫做光学字符识别。它是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。OCR 现在已经广泛应用于生产生活中,如文档识别、证件识别、字幕识别、文档检索等等。当然对于本节所述的图形验证码的识别也没有问题。
import time import re import tesserocr from selenium import webdriver from io import BytesIO from PIL import Image from retrying import retry from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium.common.exceptions import TimeoutException import numpy as np
上市了!")