
本文转载自:陈文管的博客-微信公众号文章爬取之:服务端数据采集 本篇内容介绍微信公众号文章服务端数据爬取的实现,配合上一篇微信公众号文章采集之:微信自动化,构成完整的微信公众号文章数据采集系统。
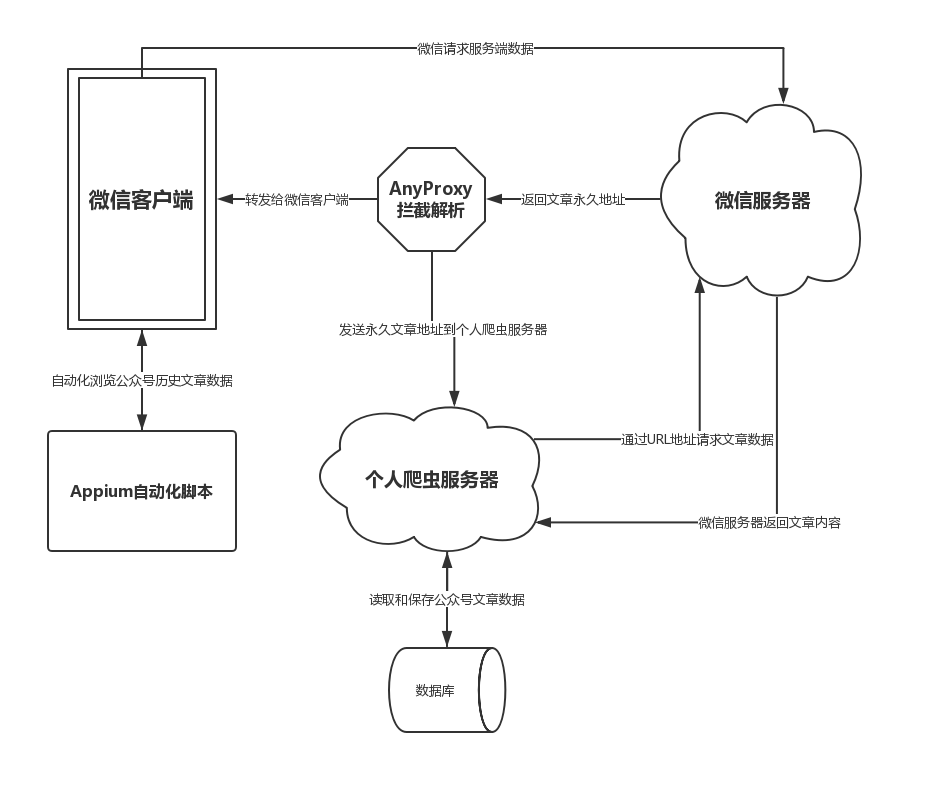
公众号文章爬取系统架构图
一、AnyProxy 配置(Mac)
AnyProxy是一个开放式的HTTP代理服务器,官方文档:http://anyproxy.io/cn/ Github主页:https://github.com/alibaba/anyproxy 主要特性包括: 基于Node.js,开放二次开发能力,允许自定义请求处理逻辑 支持Https的解析 提供GUI界面,用以观察请求
1、安装NodeJS
在安装Anyproxy之前,需要先安装Nodejs。Nodejs下载地址:http://nodejs.cn/download/。 下载安装完之后可以在终端执行以下命令查看所安装的版本:
1 |
node --version 查看node安装版本 |
2、AnyProxy安装配置
1) Mac端的安装配置
AnyProxy 不要安装最新的版本,因为接口变动较大,不便于在原来的基础上重写接口,如果已经安装最新的版本,先执行以下命令卸载:
1 |
sudo npm uninstall -g anyproxy |
之后安装3.X版本:
1 |
sudo npm install anyproxy@3.x -g |
接着安装相应的证书:
1 |
anyproxy --root |
2) AnyProxy rule_default.js 文件的配置
直接拷贝如下的配置覆盖AnyProxy rule_default.js配置文件即可,具体可参考知乎大神的文章:微信公众号内容的批量采集与应用 ,其中关于图片的优化,配置的fs.readFileSync()参数替换成自己的图片放置路径。将公众号里面的所有图片替换成本地图片的目的是减轻网络传输压力和浏览器占用的内存,有效的提高运行效率,可以自己制作一张1×1像素的png透明图片。 这边跟知乎文章不同的是,在replaceServerResDataAsync中只需要把拦截的微信文章URL地址转发到自己的服务器,因为自动化浏览脚本是直接进入到公众号文章的详情页面,就不需要像知乎文章介绍的那样那么麻烦。 TIPS: 在2019.5.6-2019.5.12时间段之间,微信公众号更新了公众号文章的请求加载方式。 在replaceServerResDataAsync接口中拦截URL的方式已经行不通, 通过AnyProxy拦截的URL参数可以看到已经没有了”/s?__biz=”开头的URL, 但是从
1 |
“/mp/getappmsgext?”和“/mp/getappmsgad?“ |
开头的请求链接点击进去还是可以看到文章的请求链接地址。 如果是2019.5.12号之前的时间点,拦截URL接口在replaceServerResDataAsync,对应的AnyProxy rule_default.js配置文件为:rule_default_before20190512.js 在2019.5.12号之后的时间点,拦截URL的接口变动到shouldUseLocalResponse : function(req,reqBody),只要把request body发送到后台服务器,再加上”https://mp.weixin.qq.com/s?”前缀进行拼接就行,对应的AnyProxy rule_default.js配置文件应该改为:rule_default_after20190512.js 如果忘记了AnyProxy的安装路径,用命令查找rule_default.js文件即可:
1 |
find ~ -iname "rule_default.js" |
3)AnyProxy启动
在终端执行命令启动AnyProxy:
1 |
anyproxy -i |
如果遇到如下的异常说明缺少写文件夹的权限:
1 |
the default rule for AnyProxy. |
用以下命令修改下文件夹权限即可:
1 |
sudo chown -R `whoami` /Users/chenwenguan/.anyproxy |
4)Android虚拟机上的配置
AnyProxy启动完成后,访问GUI地址:http://192.168.1.101:8002

下载AnyProxy证书文件
点击下载rootCA.crt文件,可以在虚拟机SD卡根目录下新建一个rootCA文件夹,把文件用adb命令的方式Push到虚拟机的sdcard目录下:
1 |
adb push rootCA.crt /sdcard/rootCA/ |
之后进入Android虚拟机系统设置界面,进入安全设置项,选择从SD卡安装(从SD卡安装证书)设置项,选择Push到sd卡下的证书文件安装,如果没有做这个操作,在微信加载WebView的时候会不断地弹出警告弹窗。 如果没有在模拟器找到系统设置或WI-FI网络设置的入口,可用adb命令调用进入,直接进入网络设置页面命令如下:
1 |
adb shell am start -a android.intent.action.MAIN -n com.android.settings/.wifi.WifiSettings |
进入模拟器系统设置页面命令:
1 |
adb shell am start com.android.settings/com.android.settings.Settings |
在Android模拟器上还要设置网络代理,长按WIFI网络设置项,弹窗选择修改网络选项,IP地址就写电脑的IP,端口填8001。
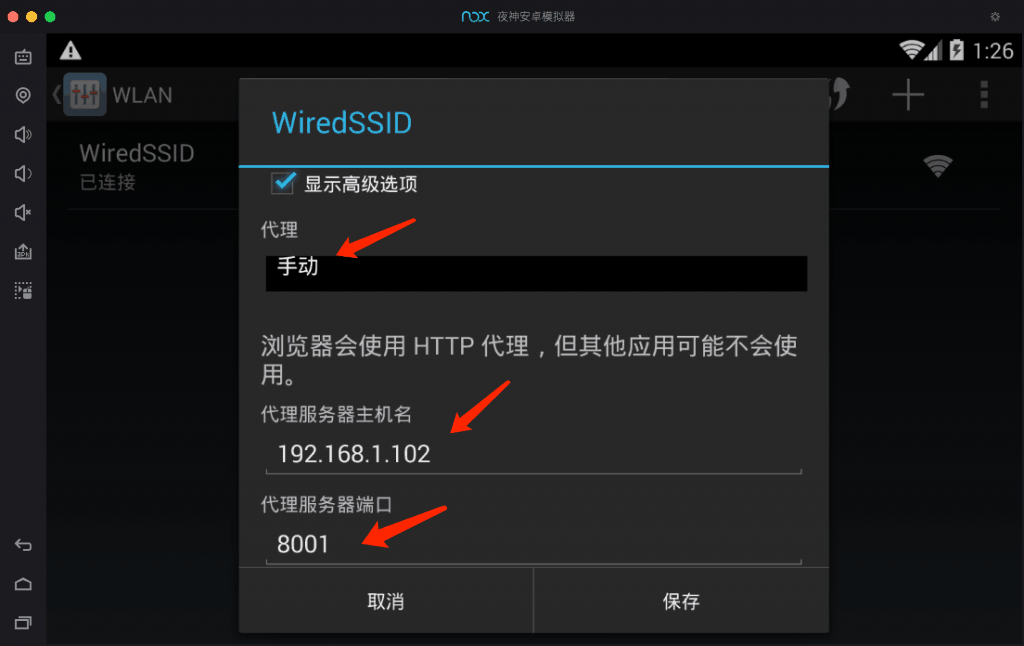
安卓虚拟机网络代理设置
在以上都配置完毕之后,进入微信应用查看公众号文章,就可以在GUI界面上看到AnyProxy拦截到的所有请求URL地址信息。 如文章前面的说明,在2019.5.12时间点之前还可以看到”/s?__biz=”开头的URL请求参数。
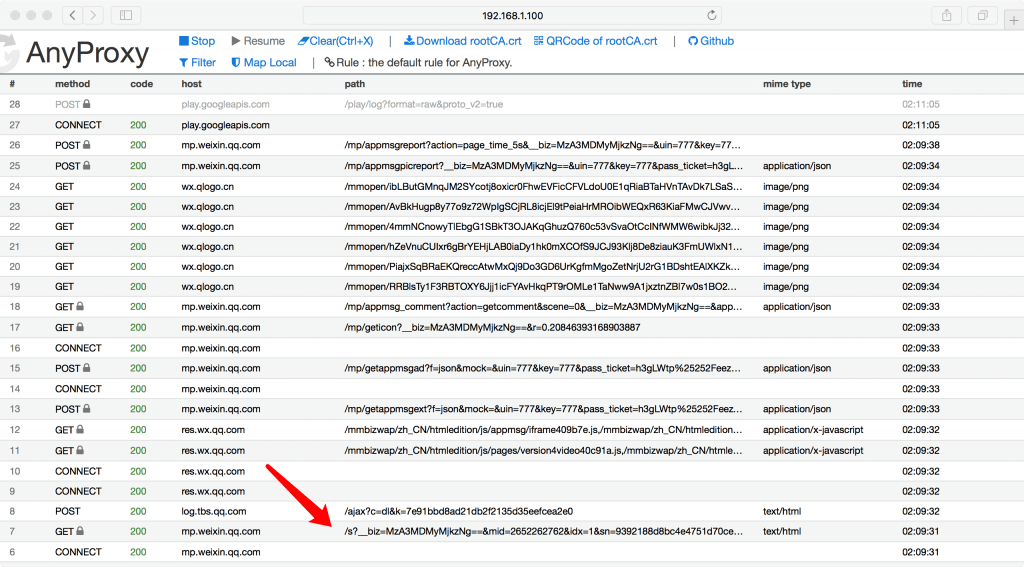
AnyProxy 拦截的URL信息
上面/s?__biz=开头的URL就是微信公众号文章详细的URL地址,可以点击查看具体的详细信息:
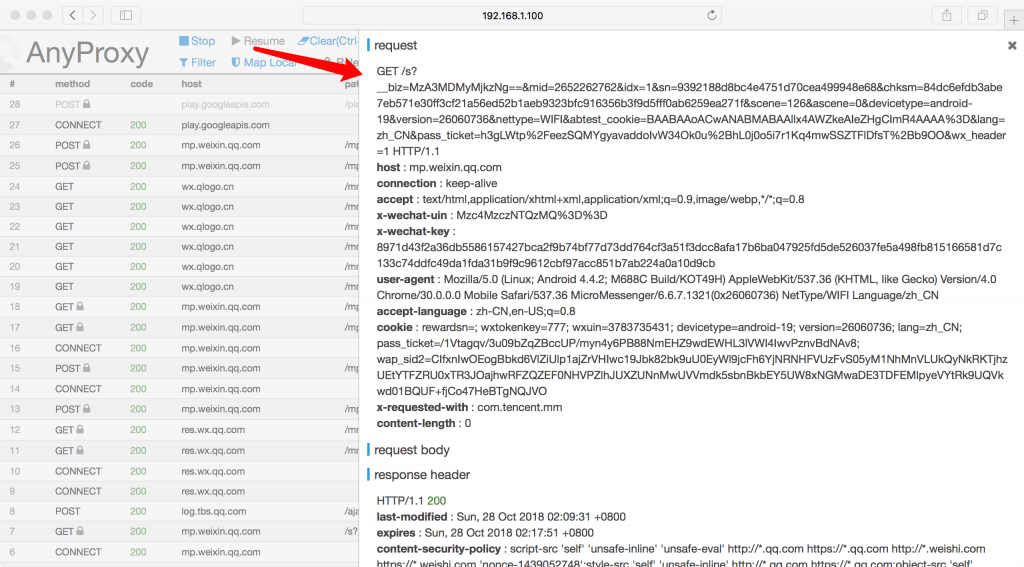
微信公众号文章URL详细信息
页面往下滑动,查看请求到的公众号文章详细字段信息,服务端爬虫就是从这些字段参数定义的值来截取需要的信息。
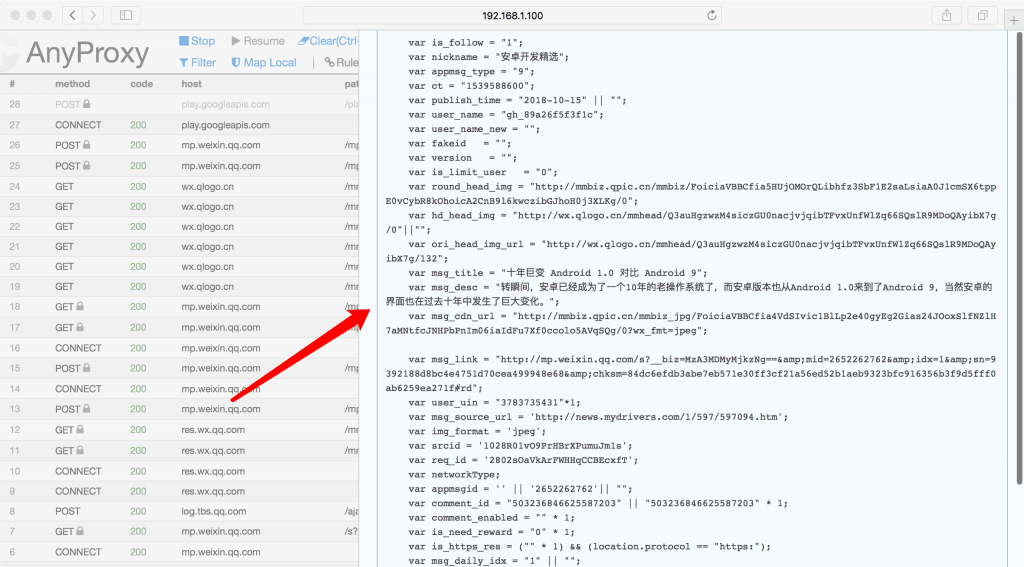
AnyProxy解析的公众号文章详细信息
目前在服务端实现保存的字段只是一些基本的信息,如标题、作者、文章发布时间等,如果需要其他信息可以参考上图的一些字段做正则匹配。 在2015.5.12时间点,微信变动公众号文章加载方式之后,文章的实际地址参数在“/mp/getappmsgext?”开头的请求链接里面,包括点赞和阅读数据也在这个请求返回的结构体里面。在“ /mp/getappmsgad?“开头的请求链接request body也是文章的链接地址,但选择“/mp/getappmsgext?”开头的URL来拦截处理比较好。

拦截getappmsgext的请求结构体就是文章实际地址
在getappmsgext拦截的页面往下滑动到response body就可以看到文章的阅读和点赞数据,因为这边没有阅读和点赞的数据解析需求,有需要的自行研究下从rule_default.js配置文件哪个接口拦截转发数据。
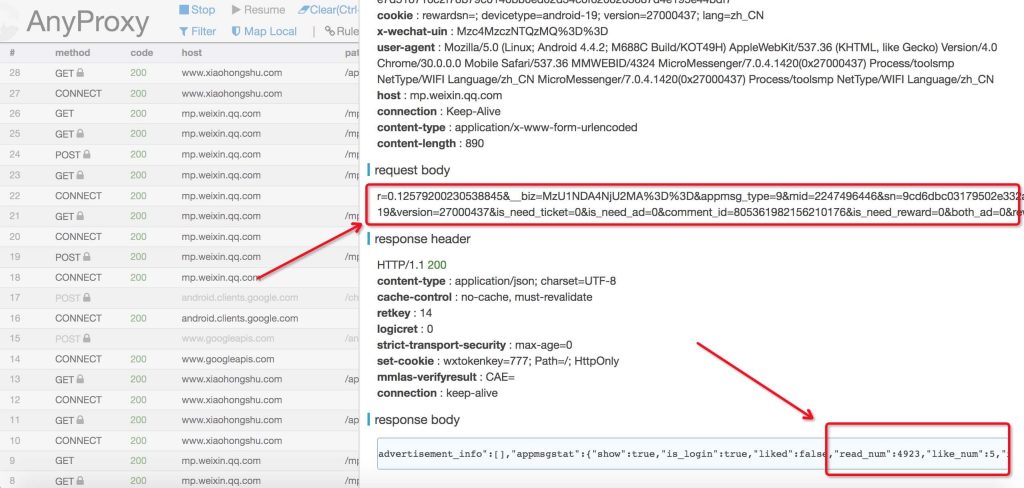
拦截getappmsgext的请求返回的数据包括阅读和点赞数
二、JavaWeb 服务端实现
1、运行环境配置
Intellij IDEA 官网下载地址:https://www.jetbrains.com/idea/ 破解方法参考:IntelliJ IDEA 2017 完美注册方法 TIPS:要先打开IDEA之后再做如下配置,否则会被识别为文件已损坏
1 |
-javaagent:/Applications/IntelliJ IDEA.app/Contents/bin/JetbrainsCrack-2.7-release-str.jar |
2、服务端实现
爬虫服务端实现GitHub源码地址:
1 |
[https://github.com/wenguan0927/WechatSpider](https://github.com/wenguan0927/WechatSpider) |
1)实现类说明
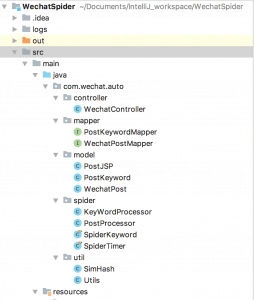
公众号爬虫服务端实现源码类说明
WechatController类做AnyProxy转发的文章链接接收和JSP页面显示的逻辑处理。 mapper文件夹下的两个类是数据库操作的映射操作类,通过配置文件自动生成,只是手动加了几个数据查询方法的实现,PostKeyWordMapper用来操作存储公众号文章关键词的数据,WechatPostMapper用来操作存储公众号文章详细数据。 model文件夹下PostJSP只是用来JSP页面显示数据的一个中间类,在JSP页面中去拼接包含较多特殊字符的文本内容容易出问题,我这边的实现是要直接生成MarkDown文档的格式,所以做了一层转化处理。PostKeyWord是公众号关键字的类,WechatPost是公众号文章详细数据类。 spider文件夹下的类就是公众号文章关键字和公众号文章详细信息的爬取解析处理类。 util文件夹下放的是工具类,SimHash只是用来测试通过关键字计算公众号文章关联性实现类,有兴趣可以自己做下挖掘。
2)配置文件说明
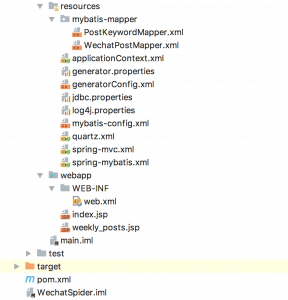
公众号爬虫服务端实现配置文件说明
mybatis-mapper文件夹下的两个文件是数据库映射XML资源文件,通过generator.properties和generatorConfig.xml两个配置文件自动生成,具体可参考:数据库表反向生成(一) MyBatis-generator与IDEA的集成 。 这边需要注意的是,如果要在反向生成的数据库映射操作文件中增加方法实现,不要在Mapper.xml文件里面添加方法,要加的话在Mapper.java的类中加,可参考WechatPostMapper.java 类中末尾几个方法,通过在函数上添加注解的方式实现。 generator.properties文件中的jdbc.driverLocation改成自己电脑的connector实际路径,jdbc.userId和jdbc.password改成自己数据库的用户名和密码。 jdbc.properties文件中的数据库参数也改成自己配置的值。 其他文件只是常规的Web实现配置,此处不做多余赘述。
3)实现过程中遇到的问题
1)@Autowired注解的Mapper类报NullPointException异常
1 |
|
这边需要注意的是通过@Autowired注解声明的类不能在一个new出来的类中使用,@Autowired只能在通过框架注解生成的类中使用,在一个new出来的类中使用注解在框架生成的类中是找不到的,所以会报空指针异常。其他异常可参考:@Autowired注解和静态方法 2)Intellj(IDEA) warning no artifacts configured 异常 参考文章:【错误解决】Intellj(IDEA) warning no artifacts configured 3)Intellij 代理端口占用异常
1 |
错误: 代理抛出异常错误: |
终端输入命令查看端口所在进程:
1 |
sudo lsof -i :1099 |
之后可看到如下类似的结果:
1 |
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME |
终端输命令杀进程:kill 582 4)http://java.sun.com/jsp/jstl/core cannot be resolved 如果配置的jstl版本是1.2, 不需要通过导入jstl.jar和standard.jar包的方式,如果配置的是1.2以下的版本,可参考文章: core cannot be resolved。 jar包的下载地址:
1 |
[http://archive.apache.org/dist/jakarta/taglibs/standard/binaries/](http://archive.apache.org/dist/jakarta/taglibs/standard/binaries/) |
5) Warning:The/usr/local/mysql/data directory is not owned by the ‘mysql’ or ‘_mysql’
如果因Mac系统更新导致MySQL提示以上异常,执行以下命令解决:
1 |
sudo chown -R _mysql:wheel /usr/local/mysql/data |
参考博文:Mac在偏好设置启动MySQL失败 6)注解中的数据库IN查询语句实现
1 |
@Select({"<script>", |
如果是要在注解中实现IN多条件查询,需要如上面的方式去实现,直接按照原生SQL语句的方式实现是行不通的。 参考博文:SpringBoot使用Mybatis注解开发教程-分页-动态sql
4) 数据库实现
公众号文章详情数据表实现:
1 |
CREATE TABLE `postTable` ( |
公众号关键字数据表实现:
1 |
CREATE TABLE `keywordTable` ( |
5)遗留问题
公众号文章的分类目前没有很好地实现,也就是,目前爬取的公众号文章我要分为三大类,新闻类、Android开发、技术扩展,一开始的想法是根据以往发布的每周技术周报文章内容,提取每个类别文章的关键词数据,生成一个关键词数据库,之后爬取的文章,可以通过提取文章的关键词跟历史记录文章的关键词词库进行对比,计算它们的相关性来进行归类。 目前用HanLP开源代码来做测试,提取的关键词都是中文的关键词,在做关联性计算的时候并不能达到理想的效果,因为开发类的文章有很多英文的词汇,HanLP里面并不包括英文词汇的词库,所以下一步要做的是做一个技术类文章的分词词库来实现文章的归类处理。 这边给出一些参考文章的链接资源,有兴趣可以自己做一下深挖。 TextRank算法提取关键词的Java实现 TextRank算法提取关键词和摘要 计算两组标签/关键词相似度算法 HanLP自然语言处理包开源 文本关键词提取算法解析 NLP点滴——文本相似度 文本相似性计算总结(余弦定理,simhash)及代码 如何实现一个基本的微信文章分类器 HanLP GitHub开源代码
三、其他参考资料
Mac OS X上IntelliJ IDEA 13与Tomcat 8的Java Web开发环境搭建 IntelliJ IDEA 15 创建maven项目 MyBatis官网 Intellij IDEA 使用教程 HTML语言中括号(尖括号)的字符编码 mac下mongodb的安装与配置 mac下mongodb的安装和使用(使用终端操作) Intellij Mongo配置 Java连接MongoDB进行增删改查 IntelliJ IDEA手动配置连接MySQL数据库 MongoDB中文教程 MongoDB官方文档 WebMagic 爬虫框架

