
Scrapy-Redis 详解
通常我们在一个站站点进行采集的时候,如果是小站的话 我们使用scrapy本身就可以满足。 但是如果在面对一些比较大型的站点的时候,单个scrapy就显得力不从心了。  要是我们能够多个Scrapy一起采集该多好啊 人多力量大。 很遗憾Scrapy官方并不支持多个同时采集一个站点,虽然官方给出一个方法: 将一个站点的分割成几部分 交给不同的scrapy去采集 似乎是个解决办法,但是很麻烦诶!毕竟分割很麻烦的哇 下面就改轮到我们的额主角Scrapy-Redis登场了!
要是我们能够多个Scrapy一起采集该多好啊 人多力量大。 很遗憾Scrapy官方并不支持多个同时采集一个站点,虽然官方给出一个方法: 将一个站点的分割成几部分 交给不同的scrapy去采集 似乎是个解决办法,但是很麻烦诶!毕竟分割很麻烦的哇 下面就改轮到我们的额主角Scrapy-Redis登场了! 
什么??你这么就登场了?还没说为什么呢?
好吧 为了简单起见 就用官方图来简单说明一下:  这张图大家相信大家都很熟悉了。重点看一下SCHEDULER 1. 先来看看官方对于SCHEDULER的定义: SCHEDULER接受来自Engine的Requests,并将它们放入队列(可以按顺序优先级),以便在之后将其提供给Engine 点我看文档 2. 现在我们来看看SCHEDULER都提供了些什么功能: 根据官方文档说明 在我们没有没有指定 SCHEDULER 参数时,默认使用:’scrapy.core.scheduler.Scheduler’ 作为SCHEDULER(调度器) scrapy.core.scheduler.py:
这张图大家相信大家都很熟悉了。重点看一下SCHEDULER 1. 先来看看官方对于SCHEDULER的定义: SCHEDULER接受来自Engine的Requests,并将它们放入队列(可以按顺序优先级),以便在之后将其提供给Engine 点我看文档 2. 现在我们来看看SCHEDULER都提供了些什么功能: 根据官方文档说明 在我们没有没有指定 SCHEDULER 参数时,默认使用:’scrapy.core.scheduler.Scheduler’ 作为SCHEDULER(调度器) scrapy.core.scheduler.py:
1 |
class Scheduler(object): |
只挑了一些重点的写了一些注释剩下大家自己领会(才不是我懒哦 ) 从上面的代码 我们可以很清楚的知道 SCHEDULER的主要是完成了 push Request pop Request 和 去重的操作。 而且queue 操作是在内存队列中完成的。 大家看queuelib.queue就会发现基于内存的(deque) 那么去重呢?
1 |
class RFPDupeFilter(BaseDupeFilter): |
按照正常流程就是大家都会进行重复的采集;我们都知道进程之间内存中的数据不可共享的,那么你在开启多个Scrapy的时候,它们相互之间并不知道对方采集了些什么那些没有没采集。那就大家伙儿自己玩自己的了。完全没没有效率的提升啊!  怎么解决呢? 这就是我们Scrapy-Redis解决的问题了,不能协作不就是因为Request 和 去重这两个 不能共享吗? 那我把这两个独立出来好了。 将Scrapy中的SCHEDULER组件独立放到大家都能访问的地方不就OK啦!加上scrapy-redis后流程图就应该变成这样了? 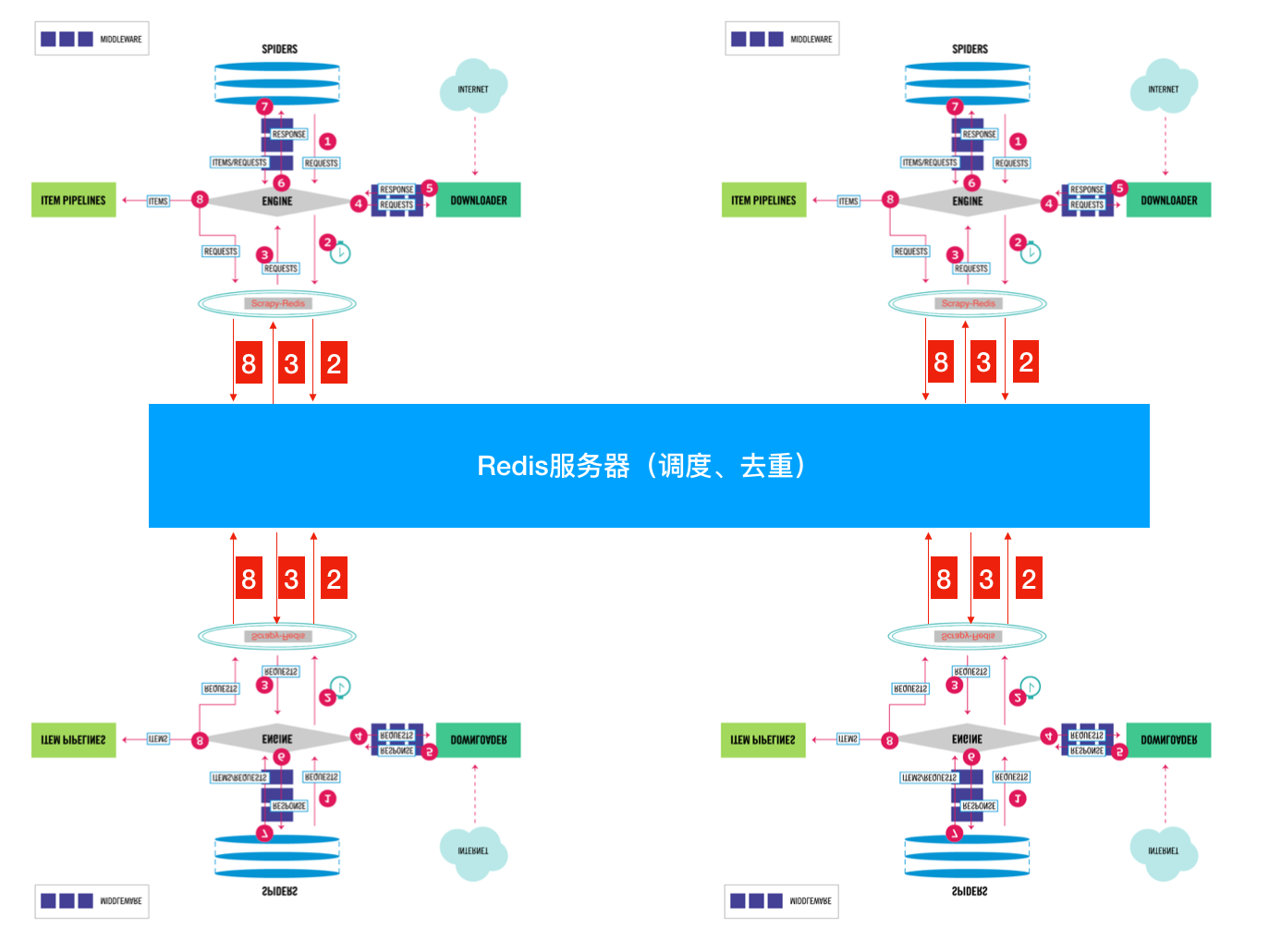 So············· 这样是不是看起来就清楚多了??? 下面我们来看看Scrapy-Redis是怎么处理的? scrapy_redis.scheduler.py:
1 |
class Scheduler(object): |
来先来看看 以上就是Scrapy-Redis中的SCHEDULER模块。下面我们来看看queue和本身的什么不同: scrapy_redis.queue.py 以最常用的优先级队列 PriorityQueue 举例:
1 |
class PriorityQueue(Base): |
以上就是SCHEDULER在处理Request的时候做的操作了。 是时候来看看SCHEDULER是怎么处理去重的了! 只需要注意这个?方法即可:
1 |
def request_seen(self, request): |
这样大家就都可以访问同一个Redis 获取同一个spider的Request 在同一个位置去重,就不用担心重复啦 大概就像这样:
- spider1:检查一下这个Request是否在Redis去重,如果在就证明其它的spider采集过啦!如果不在就添加进调度队列,等待别 人获取。自己继续干活抓取网页 产生新的Request了 重复之前步骤。
- spider2:以相同的逻辑执行
可能有些小伙儿会产生疑问了~~!spider2拿到了别人的Request了 怎么能正确的执行呢?逻辑不会错吗? 这个不用担心啦 因为整Request当中包含了,所有的逻辑,回去看看上面那个序列化的字典。 总结一下:
- 1. Scrapy-Reids 就是将Scrapy原本在内存中处理的 调度(就是一个队列Queue)、去重、这两个操作通过Redis来实现
- 多个Scrapy在采集同一个站点时会使用相同的redis key(可以理解为队列)添加Request 获取Request 去重Request,这样所有的spider不会进行重复采集。效率自然就嗖嗖的上去了。
- 3. Redis是原子性的,好处不言而喻(一个Request要么被处理 要么没被处理,不存在第三可能)
另外Scrapy-Redis本身不支持Redis-Cluster,大量网站去重的话会给单机很大的压力(就算使用boolfilter 内存也不够整啊!) 改造方式很简单:
- 使用 rediscluster 这个包替换掉本身的Redis连接
- Redis-Cluster 不支持事务,可以使用lua脚本进行代替(lua脚本是原子性的哦)
- 注意使用lua脚本 不能写占用时间很长的操作(毕竟一大群人等着操作Redis 你总不能让人家等着吧)
以上!完毕 对于懒人小伙伴儿 看看这个我改好的: 集群版Scrapy-Redis PS: 支持Python3.6+ 哦 ! 其余的版本没测试过 

